You might also like
- Let's Check: Dolino, Mariel N. EDUC102 (556) Bsed-FilDocument2 pagesLet's Check: Dolino, Mariel N. EDUC102 (556) Bsed-FilMariel Nucum DolinoNo ratings yet
- Assign No 3 REVISEDDocument4 pagesAssign No 3 REVISEDKirito SeñarosaNo ratings yet
- Cot Filipino Q 2Document4 pagesCot Filipino Q 2Jane Bunuan SaludaresNo ratings yet
- Threshold Concepts and Capabilities in Signal ProcessingDocument7 pagesThreshold Concepts and Capabilities in Signal ProcessingbeaurNo ratings yet
- Five categories of learning skillsDocument1 pageFive categories of learning skillsfanggNo ratings yet
- Group 7Document7 pagesGroup 7Nur Faizal DamaNo ratings yet
- Frensch Curr Dir Psych Sci 2003Document7 pagesFrensch Curr Dir Psych Sci 2003Rachmat AgamNo ratings yet
- Learning theories and models for instructional designDocument2 pagesLearning theories and models for instructional designRuby Ann TerolNo ratings yet
- Lesson Plan NotesDocument13 pagesLesson Plan Notesapi-301457378No ratings yet
- Topic 3 Understanding Pedagogical Theories For Informed, Effective and Appropriate Teaching PracticeDocument16 pagesTopic 3 Understanding Pedagogical Theories For Informed, Effective and Appropriate Teaching PracticeJennica Roz Fronda-CastroNo ratings yet
- Dorola Aaron G.Document3 pagesDorola Aaron G.eyrondorolaNo ratings yet
- Teaching Receptive Skills Luis FernandezDocument3 pagesTeaching Receptive Skills Luis FernandezLuis FernándezNo ratings yet
- Science8 Q1 W4 D3 WhenIsWorkDoneDocument3 pagesScience8 Q1 W4 D3 WhenIsWorkDoneLenlen NamocNo ratings yet
- Towards Causal Representation LearningDocument24 pagesTowards Causal Representation LearningYishuai ZhangNo ratings yet
- Bi-CLKT Bi-Graph Contrastive Learning Based Knowledge TracingDocument12 pagesBi-CLKT Bi-Graph Contrastive Learning Based Knowledge Tracingliuyunwu2008No ratings yet
- Instructional Design FrameworkDocument13 pagesInstructional Design FrameworkEka KutateladzeNo ratings yet
- A Review On Deep Learning Techniques Applied To Semantic SegmentationDocument23 pagesA Review On Deep Learning Techniques Applied To Semantic SegmentationMatiur Rahman MinarNo ratings yet
- Increasing Fluid Intelligence Is Possible After AllDocument2 pagesIncreasing Fluid Intelligence Is Possible After AllJuan MNo ratings yet
- DatabaseDocument53 pagesDatabaseMJ HontiverosNo ratings yet
- Annotation-English 9 4TH CLASSROOM OBSERVATION February 20, 2020Document3 pagesAnnotation-English 9 4TH CLASSROOM OBSERVATION February 20, 2020Rey Salomon VistalNo ratings yet
- Near Real-Time Comprehension Classification With Artificial Neural Networks: Decoding E-Learner Non-Verbal BehaviourDocument8 pagesNear Real-Time Comprehension Classification With Artificial Neural Networks: Decoding E-Learner Non-Verbal BehaviourSnehaNo ratings yet
- Meta-Learning in Neural Networks: A SurveyDocument20 pagesMeta-Learning in Neural Networks: A SurveyLilian AyNo ratings yet
- Generative Learning PosterDocument1 pageGenerative Learning PosterHy Bang Tran HoangNo ratings yet
- Deep Reinforcement Learning: A Brief SurveyDocument13 pagesDeep Reinforcement Learning: A Brief Surveygiannis dimopoulosNo ratings yet
- Principles Strats m1 TransDocument1 pagePrinciples Strats m1 TransKz MinaNo ratings yet
- Inquiry Blog 3Document6 pagesInquiry Blog 3api-328368399No ratings yet
- Multi-task Learning Text Classification Using Hybrid CNN-RNN RepresentationDocument14 pagesMulti-task Learning Text Classification Using Hybrid CNN-RNN RepresentationsulisNo ratings yet
- Electronics 08 00292 v3 PDFDocument66 pagesElectronics 08 00292 v3 PDFRio CarthiisNo ratings yet
- A Study On The Effectiveness of Virtual Lab in E-Learning: Lavanya Rajendran, Ramachandran Veilumuthu, Divya. JDocument3 pagesA Study On The Effectiveness of Virtual Lab in E-Learning: Lavanya Rajendran, Ramachandran Veilumuthu, Divya. Jaditya thakkarNo ratings yet
- 7 Waysoflearning 2Document26 pages7 Waysoflearning 2AgnesNo ratings yet
- Stop Overkilling Simple Tasks With Black-BoxDocument7 pagesStop Overkilling Simple Tasks With Black-Boxel_charlieNo ratings yet
- Meta-Learning in Neural Networks: A Concise SurveyDocument20 pagesMeta-Learning in Neural Networks: A Concise SurveyMuhammad Fhadli SullivanNo ratings yet
- COVID-19: Examining the challenges for radiologic technology students of using online learningDocument3 pagesCOVID-19: Examining the challenges for radiologic technology students of using online learningMaria Sofia AngoluanNo ratings yet
- Annotation-English 9 First Classroom Observation July 30, 2019Document3 pagesAnnotation-English 9 First Classroom Observation July 30, 2019Rey Salomon Vistal100% (4)
- Learning TheoriesDocument2 pagesLearning Theories2015 Ens RAMOS GUERRERO LINDA MAGALY100% (1)
- Conneau Et Al. - 2017 - Supervised Learning of Universal Sentence Representations From Natural Language Inference DataDocument12 pagesConneau Et Al. - 2017 - Supervised Learning of Universal Sentence Representations From Natural Language Inference DataBlack FoxNo ratings yet
- Self-Supervised Representation Learning - Introduction, Advances and ChallengesDocument19 pagesSelf-Supervised Representation Learning - Introduction, Advances and Challengescavidanz12No ratings yet
- Learning Theories Applied To Program DevelopmentDocument2 pagesLearning Theories Applied To Program DevelopmentMa'am KinNo ratings yet
- Habitual Control of Goal Selection in HumansDocument6 pagesHabitual Control of Goal Selection in HumansJessica PhamNo ratings yet
- Dbda ManualDocument17 pagesDbda ManualStephen Mathew100% (1)
- HCI Lecture 5: Conceptual Models: Task AnalysisDocument4 pagesHCI Lecture 5: Conceptual Models: Task AnalysisSadıkNo ratings yet
- Performance Assessment Tasks for Teaching SubjectsDocument5 pagesPerformance Assessment Tasks for Teaching SubjectsReyna CarenioNo ratings yet
- Theory ChartDocument13 pagesTheory Chartapi-354131146No ratings yet
- Instructional Plan: Learning Area: Grade Level: Iplan No.: Quarter: Duration: Content Key Concepts CodeDocument3 pagesInstructional Plan: Learning Area: Grade Level: Iplan No.: Quarter: Duration: Content Key Concepts Codejayson reyesNo ratings yet
- 3 LEARNING THEORIES_MUHAMMAD NASRULLAH BIN MOHD NOOR_154161Document1 page3 LEARNING THEORIES_MUHAMMAD NASRULLAH BIN MOHD NOOR_154161qr2scb27dzNo ratings yet
- Instructional Plan: Learning Area: Grade Level: Iplan No.: Quarter: Duration: Content Key Concepts CodeDocument3 pagesInstructional Plan: Learning Area: Grade Level: Iplan No.: Quarter: Duration: Content Key Concepts Codejayson reyes100% (1)
- 1 s2.0 S0896627319307408 MainDocument13 pages1 s2.0 S0896627319307408 MainRaghavendranNo ratings yet
- Authors: Sathish Kumar Mudedla Abdennour Braka Sangwook WuDocument4 pagesAuthors: Sathish Kumar Mudedla Abdennour Braka Sangwook WuHabaekNo ratings yet
- Relation Meural MachinesDocument8 pagesRelation Meural MachinesEaco ShawNo ratings yet
- EVIDENCE 1 Loredo Jessa Mae D.Document10 pagesEVIDENCE 1 Loredo Jessa Mae D.April Grace Genobatin BinayNo ratings yet
- TABLE of Critical ReviewDocument6 pagesTABLE of Critical ReviewnurainizaNo ratings yet
- Connectionist Models of Reinforcement Imitation and Instruction in Learning To Solve Complex Problem-eQuDocument12 pagesConnectionist Models of Reinforcement Imitation and Instruction in Learning To Solve Complex Problem-eQumohmmaed khalidNo ratings yet
- Tutorial On Deep Learning For Human Activity Recognition: Marius Bock Alexander HölzemannDocument6 pagesTutorial On Deep Learning For Human Activity Recognition: Marius Bock Alexander HölzemannFrancesco BNo ratings yet
- Kendall'S AND Marzano NEW Taxonomy: Prepared By: Jonalyn I. Camila (GROUP 3)Document20 pagesKendall'S AND Marzano NEW Taxonomy: Prepared By: Jonalyn I. Camila (GROUP 3)Alberth AbayNo ratings yet
- What Is Educational PsychologyDocument8 pagesWhat Is Educational PsychologyLairepmi EmjaneNo ratings yet
- IEEE PAMI: Towards Open Vocabulary Learning A SurveyDocument20 pagesIEEE PAMI: Towards Open Vocabulary Learning A SurveyMilton WongNo ratings yet
- Corrected Assessment 1 - Kareem Derbas 17699075Document10 pagesCorrected Assessment 1 - Kareem Derbas 17699075api-532746316No ratings yet
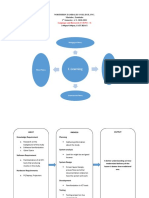
- Brown and White Doodle Mind Map Brainstorm GraphDocument1 pageBrown and White Doodle Mind Map Brainstorm GraphSri RetinaNo ratings yet
- Lesson Plan 3Document2 pagesLesson Plan 3api-449406527No ratings yet
- Spatial Learning Strategies: Techniques, Applications, and Related IssuesFrom EverandSpatial Learning Strategies: Techniques, Applications, and Related IssuesCharles D. HolleyNo ratings yet
- The Complexity Approach To EconomicsDocument31 pagesThe Complexity Approach To EconomicsclearlyInvisibleNo ratings yet
- Carlsson - On The Nature, Function and Composition of Technological SystemsDocument26 pagesCarlsson - On The Nature, Function and Composition of Technological SystemsclearlyInvisibleNo ratings yet
- Cordes - Innovation Economics TheoryDocument46 pagesCordes - Innovation Economics TheoryclearlyInvisibleNo ratings yet
- Rosa Et Al. - 2019 - BADGER Learning To (Learn (Learning Algorithms) TDocument15 pagesRosa Et Al. - 2019 - BADGER Learning To (Learn (Learning Algorithms) TclearlyInvisibleNo ratings yet
- Key Features of Sap Conversational A IDocument14 pagesKey Features of Sap Conversational A Iswarup_sawantNo ratings yet
- Tuyls Et Al. - 2020 - Game Plan What AI Can Do For Football, and What FDocument41 pagesTuyls Et Al. - 2020 - Game Plan What AI Can Do For Football, and What FclearlyInvisibleNo ratings yet
- Liu Et Al. - 2020 - GoChat Goal-Oriented Chatbots With Hierarchical RDocument4 pagesLiu Et Al. - 2020 - GoChat Goal-Oriented Chatbots With Hierarchical RclearlyInvisibleNo ratings yet
- How Complex Are Complex SystemsDocument16 pagesHow Complex Are Complex SystemsclearlyInvisibleNo ratings yet
- Gu Et Al. - 2019 - Meta-Learning Biologically Plausible Semi-SupervisDocument6 pagesGu Et Al. - 2019 - Meta-Learning Biologically Plausible Semi-SupervisclearlyInvisibleNo ratings yet
- Liu Et Al. - 2021 - From Motor Control To Team Play in Simulated HumanDocument57 pagesLiu Et Al. - 2021 - From Motor Control To Team Play in Simulated HumanclearlyInvisibleNo ratings yet
- Gemp Et Al. - 2020 - EigenGame PCA As A Nash EquilibriumDocument11 pagesGemp Et Al. - 2020 - EigenGame PCA As A Nash EquilibriumclearlyInvisibleNo ratings yet
- PDLTDocument449 pagesPDLTTruc LeNo ratings yet
- Tiwari Et Al. - 2021 - A Dynamic Goal Adapted Task Oriented Dialogue AgenDocument32 pagesTiwari Et Al. - 2021 - A Dynamic Goal Adapted Task Oriented Dialogue AgenclearlyInvisibleNo ratings yet
- Gaggioli Et Al. - 2021 - Machines Like Us and People Like You Toward HumanDocument6 pagesGaggioli Et Al. - 2021 - Machines Like Us and People Like You Toward HumanclearlyInvisibleNo ratings yet
- Brown Et Al. - Elder Care Wearable Device Final ReportDocument53 pagesBrown Et Al. - Elder Care Wearable Device Final ReportclearlyInvisibleNo ratings yet
- Hosseini-Asl Et Al. - A Simple Language Model For Task-Oriented DialogueDocument13 pagesHosseini-Asl Et Al. - A Simple Language Model For Task-Oriented DialogueclearlyInvisibleNo ratings yet
- Nakamura and Kobayashi - 2021 - Connection Between The Bacterial Chemotactic NetwoDocument5 pagesNakamura and Kobayashi - 2021 - Connection Between The Bacterial Chemotactic NetwoclearlyInvisibleNo ratings yet
- Martínez-Martín and Cazorla - 2019 - A Socially Assistive Robot For Elderly Exercise PRDocument15 pagesMartínez-Martín and Cazorla - 2019 - A Socially Assistive Robot For Elderly Exercise PRclearlyInvisibleNo ratings yet
- Abour BciDocument42 pagesAbour BciSenthilNo ratings yet
- Teaching robot programming to K-12 students with blocks-based visual environmentDocument13 pagesTeaching robot programming to K-12 students with blocks-based visual environmentclearlyInvisibleNo ratings yet
- Hydroxyurea-The Good, The Bad and The UglyDocument18 pagesHydroxyurea-The Good, The Bad and The UglyclearlyInvisibleNo ratings yet
- Artificial Evil and The Foundation PDFDocument12 pagesArtificial Evil and The Foundation PDFSam GvmxdxNo ratings yet
- Ojha - 2021 - Computational Thinking and Social Science EducatioDocument5 pagesOjha - 2021 - Computational Thinking and Social Science EducatioclearlyInvisibleNo ratings yet
- Deep Learning Chorale Prelude 2Document3 pagesDeep Learning Chorale Prelude 2Krishna ChivukulaNo ratings yet
- Deep Dictionary Learning - 2016Document9 pagesDeep Dictionary Learning - 2016bamshadpotaNo ratings yet
- Rombach High-Resolution Image Synthesis With Latent Diffusion Models CVPR 2022 Paper-2Document12 pagesRombach High-Resolution Image Synthesis With Latent Diffusion Models CVPR 2022 Paper-2Dinuo LiaoNo ratings yet
- Online Dynamic Security Assessment of Wind Integrated Power System UsingDocument9 pagesOnline Dynamic Security Assessment of Wind Integrated Power System UsingRizwan Ul HassanNo ratings yet
- Comprehensive Guide Attention Mechanism Deep LearningDocument17 pagesComprehensive Guide Attention Mechanism Deep LearningVishal Ashok PalledNo ratings yet
- (2020) Gaussian Error Linear Units (Gelus)Document9 pages(2020) Gaussian Error Linear Units (Gelus)Mhd rdbNo ratings yet
- Early Fault Detection of Machine Tools Based On Deep Learning and Dynamic IdentificationDocument9 pagesEarly Fault Detection of Machine Tools Based On Deep Learning and Dynamic IdentificationBushra AbbasNo ratings yet
- Neuroscience-Inspired Artificial IntelligenceDocument15 pagesNeuroscience-Inspired Artificial IntelligenceGOGUNo ratings yet
- Non-Invasive Anomaly Diagnosis For Hydro Electrical Generators Rotor Inter-Turn Short-Circuit Detection Using Stray Flux and The VAEDocument7 pagesNon-Invasive Anomaly Diagnosis For Hydro Electrical Generators Rotor Inter-Turn Short-Circuit Detection Using Stray Flux and The VAEhamidrezaNo ratings yet
- Deep Learning With H2ODocument31 pagesDeep Learning With H2OcristianmondacaNo ratings yet
- Credit Card Fraud Detection Using Deep Learning Based On Auto-Encoder and Restricted Boltzmann MachineDocument8 pagesCredit Card Fraud Detection Using Deep Learning Based On Auto-Encoder and Restricted Boltzmann Machinesahki hNo ratings yet
- ASurveyonDeepLearningforData-drivenSoftSensors EarlyaccessDocument15 pagesASurveyonDeepLearningforData-drivenSoftSensors EarlyaccessTushar MukherjeeNo ratings yet
- Ladi-Vton: Latent Diffusion Textual-Inversion Enhanced Virtual Try-OnDocument15 pagesLadi-Vton: Latent Diffusion Textual-Inversion Enhanced Virtual Try-Onzhangzhengyi443No ratings yet
- Perturbation Inactivation Based Adversarial Defense For Face RecognitionDocument15 pagesPerturbation Inactivation Based Adversarial Defense For Face RecognitionRaymon ArnoldNo ratings yet
- A Comparison Study of Credit Card Fraud Detection - Supervised Versus UnsupervisedDocument9 pagesA Comparison Study of Credit Card Fraud Detection - Supervised Versus Unsupervisedsahki hNo ratings yet
- AI 101: An Introduction to Artificial IntelligenceDocument32 pagesAI 101: An Introduction to Artificial IntelligenceNguyen KimNo ratings yet
- 1 s2.0 S1874490722000490 MainDocument14 pages1 s2.0 S1874490722000490 MainBudgeNo ratings yet
- A Survey of Deep Causal ModelDocument31 pagesA Survey of Deep Causal ModelOwenliey LiuNo ratings yet
- Mm16-Yejun 1Document4 pagesMm16-Yejun 1شروق الحارثيNo ratings yet
- Phdthesisfinalmghifary PDFDocument273 pagesPhdthesisfinalmghifary PDFPendekar SaktiNo ratings yet
- DLunit 5Document17 pagesDLunit 5EXAMCELL - H4No ratings yet
- 4.1 - Unsupervised Visual Representation Learning by Context PredictionDocument10 pages4.1 - Unsupervised Visual Representation Learning by Context Predictionfarzad imanpourNo ratings yet
- Deepfakes: Trick or Treat?: Business Horizons December 2019Document13 pagesDeepfakes: Trick or Treat?: Business Horizons December 2019Ali MattrNo ratings yet
- A Survey On State Estimation Techniques and ChalleDocument12 pagesA Survey On State Estimation Techniques and ChalleAmputee FunNo ratings yet
- Chaos As An Interpretable Benchmark For Forecasting and Data-Driven ModellingDocument43 pagesChaos As An Interpretable Benchmark For Forecasting and Data-Driven Modellingwork gradsNo ratings yet
- A Gentle Introduction To LSTM AutoencodersDocument74 pagesA Gentle Introduction To LSTM AutoencodersMhd rdbNo ratings yet
- Lecture 17 - KL Divergence, AutoencodersDocument54 pagesLecture 17 - KL Divergence, AutoencodersRobert BabayanNo ratings yet
- A Simplified Generative Model Based On Gradient Descent and Mean Square ErrorDocument8 pagesA Simplified Generative Model Based On Gradient Descent and Mean Square ErrorOmar Lopez-RinconNo ratings yet
- Set Features For Fine-Grained Anomaly DetectionDocument18 pagesSet Features For Fine-Grained Anomaly DetectionVetal YeshorNo ratings yet
- Deep Learning PPT Full NotesDocument105 pagesDeep Learning PPT Full NotesAkash guptaNo ratings yet