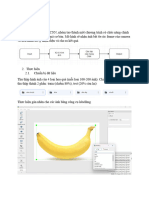
You might also like
- Bai Thuc Hanh 2 (Updated)Document6 pagesBai Thuc Hanh 2 (Updated)Cơ Đinh VănNo ratings yet
- BaiTap DeepLearning 4Document4 pagesBaiTap DeepLearning 4Văn Trịnh TrungNo ratings yet
- NLP - Bai Tap Thuc Hanh 2Document7 pagesNLP - Bai Tap Thuc Hanh 2Tong HuynhNo ratings yet
- NGUYỄN ĐỨC NAMDocument16 pagesNGUYỄN ĐỨC NAMNam ĐứcNo ratings yet
- Slide TH-C T-P AimesoftDocument26 pagesSlide TH-C T-P AimesoftThương PhạmNo ratings yet
- LUỒNG THỰC HIỆN BÀI TOÁN PHÂN LOẠI RƯỢU DỰA VÀO SOFTMAX REGRESSION2Document4 pagesLUỒNG THỰC HIỆN BÀI TOÁN PHÂN LOẠI RƯỢU DỰA VÀO SOFTMAX REGRESSION2phụng phạmNo ratings yet
- NMT DescriptionDocument20 pagesNMT DescriptionPeterNo ratings yet
- NG D NG Convolutional Neural Network Trong Bài Toán Phân Lo I NHDocument7 pagesNG D NG Convolutional Neural Network Trong Bài Toán Phân Lo I NHlearnit learnitNo ratings yet
- Deep Learning Cho Bài Toán Nhận Diện Chữ ViếtDocument8 pagesDeep Learning Cho Bài Toán Nhận Diện Chữ Viếtlearnit learnitNo ratings yet
- Bai 9Document5 pagesBai 9Vu Nguyen Manh HungNo ratings yet
- Machine Learning - NLP: Text Classification Sử Dụng Sklearn Python - Code Từ Đầu - Machine LearningDocument9 pagesMachine Learning - NLP: Text Classification Sử Dụng Sklearn Python - Code Từ Đầu - Machine Learningtnt007dataNo ratings yet
- Slide TH-C T-P AimesoftDocument26 pagesSlide TH-C T-P AimesoftThương PhạmNo ratings yet
- KT NLPDocument8 pagesKT NLPhieuNo ratings yet
- Baitap - Bosung - TIEULUAN MON HOCDocument1 pageBaitap - Bosung - TIEULUAN MON HOCVăn Trịnh TrungNo ratings yet
- Description VAEDocument22 pagesDescription VAEtruhtNo ratings yet
- NLP1 DescriptionDocument16 pagesNLP1 DescriptionĐỗ Đức ThảoNo ratings yet
- Tìm hiểu về thư viện keras trong deep learning: Thor Pham BlogDocument14 pagesTìm hiểu về thư viện keras trong deep learning: Thor Pham BlogTrương Thanh QuảngNo ratings yet
- TrinhThiCuc TH3Document4 pagesTrinhThiCuc TH3Lê ViệtNo ratings yet
- Image - Captioning - Jupyter NotebookDocument14 pagesImage - Captioning - Jupyter NotebookNguyễn Thanh TùngNo ratings yet
- Machine LearningDocument29 pagesMachine LearningNguyễn HoàngNo ratings yet
- Báo-Cáo MachineLearningDocument18 pagesBáo-Cáo MachineLearningduyanhnguyen100802No ratings yet
- Deep LearningDocument7 pagesDeep LearningTuấn Nguyễn AnhNo ratings yet
- Bai Tap Java 1Document42 pagesBai Tap Java 1Đinh Công ThuậnNo ratings yet
- 19 NguyenDuyKhang 21110204Document33 pages19 NguyenDuyKhang 21110204Duy Khang NguyễnNo ratings yet
- Phat Hien Ma Doc Bang Machine LearningDocument63 pagesPhat Hien Ma Doc Bang Machine LearningHana YukiNo ratings yet
- BTL XlaDocument12 pagesBTL XlaĐặng Thị Vân AnhNo ratings yet
- Assignment RequirementsDocument11 pagesAssignment RequirementsNguyễn Trọng PhúcNo ratings yet
- Vấn đáp món nàyDocument19 pagesVấn đáp món nàytrongnghia03.workNo ratings yet
- Xây Dựng Chương Trình Gợi ý Phim Dựa Vào Tập Dữ Liệu Movie LenDocument9 pagesXây Dựng Chương Trình Gợi ý Phim Dựa Vào Tập Dữ Liệu Movie Lenlearnit learnitNo ratings yet
- NHÚNGDocument15 pagesNHÚNGThai NgoNo ratings yet
- Ngon Ngu JavaDocument32 pagesNgon Ngu JavaCông NguyễnNo ratings yet
- Lab 01 141Document8 pagesLab 01 141hunfgNo ratings yet
- TTNT 0001Document11 pagesTTNT 0001Thanh HoàngNo ratings yet
- Bai05 KetTapVaKeThuaDocument37 pagesBai05 KetTapVaKeThuaToàn NguyễnNo ratings yet
- Lập trình Hướng đối tượng JAVADocument25 pagesLập trình Hướng đối tượng JAVAQuang Le100% (1)
- Báo cáo môn khai phá dữ liệuDocument9 pagesBáo cáo môn khai phá dữ liệuTiến Cù HuyNo ratings yet
- Xử lý ảnh và videoDocument12 pagesXử lý ảnh và videotuanlangla3No ratings yet
- HUỲNH THÁI QUYỀN-31201023981- TL CSLTDocument17 pagesHUỲNH THÁI QUYỀN-31201023981- TL CSLTQuyền HuỳnhNo ratings yet
- Báo CáoDocument12 pagesBáo Cáochutrinhtieumieucuuvibachho100% (1)
- Bao CaoDocument8 pagesBao Cao0296Nguyễn Nhật Song HàoNo ratings yet
- Cs316ac Phamcongdat 5293 Homwork 2Document99 pagesCs316ac Phamcongdat 5293 Homwork 2phamdat.290703No ratings yet
- Học Python Từ Con Số 0Document63 pagesHọc Python Từ Con Số 0Pham Minh HieuNo ratings yet
- Python PDFDocument140 pagesPython PDFbaominh007No ratings yet
- Khdl Phần Lý ThuyếtDocument21 pagesKhdl Phần Lý Thuyếttinhle.31221023009No ratings yet
- MLP303x ClassificationDocument9 pagesMLP303x Classificationđức ngọc trầnNo ratings yet
- MLP301x 1Document8 pagesMLP301x 1đức ngọc trầnNo ratings yet
- Da3 20158367Document28 pagesDa3 20158367Thịnh Nguyễn Tiến100% (1)
- Cau Truc Du Lieu Và Giai ThuatDocument6 pagesCau Truc Du Lieu Và Giai Thuattrungdung1001No ratings yet
- Chương 6. Hướng Dẫn Thực Hành Nhận Diện Ảnh CNNDocument10 pagesChương 6. Hướng Dẫn Thực Hành Nhận Diện Ảnh CNNThiên Trang0% (1)
- Bai05 KetTapVaKeThuaDocument39 pagesBai05 KetTapVaKeThuaNgô Việt CườngNo ratings yet
- Chương 3Document9 pagesChương 355. Nguyễn Đình TiệmNo ratings yet
- Lab 01 - Preprocessing: Đại Học Quốc Gia Thành Phố Hồ Chí Minh Trường Đại Học Khoa Học Tự NhiênDocument17 pagesLab 01 - Preprocessing: Đại Học Quốc Gia Thành Phố Hồ Chí Minh Trường Đại Học Khoa Học Tự Nhiêntriet24042404No ratings yet
- XlaDocument3 pagesXlachauminhhuy2020No ratings yet
- BC AiDocument13 pagesBC AiTrang MingNo ratings yet
- Chuong 7 - PTTKHTTT - Thiet Ke Lop Du LieuDocument54 pagesChuong 7 - PTTKHTTT - Thiet Ke Lop Du LieuUyên PhươngNo ratings yet
- TH02Document3 pagesTH02phannhat739090No ratings yet
- CH 07Document41 pagesCH 07Hudevelop iTestNo ratings yet
- Đề kiểm tra Cuối kỳ NLPDocument3 pagesĐề kiểm tra Cuối kỳ NLPhieuNo ratings yet