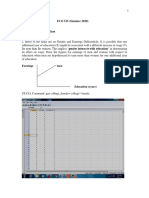
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5806)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (842)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (589)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- SUSS BSBA: BUS105 Jul 2020 TOA AnswersDocument10 pagesSUSS BSBA: BUS105 Jul 2020 TOA AnswersAzido Azide100% (1)
- MMS 2022-24 QP Business StatisticsDocument5 pagesMMS 2022-24 QP Business StatisticsnimeshnarnaNo ratings yet
- Name: Siti Mursyida Abdul Karim (Data Science Program) Topic: Assignment - EDADocument13 pagesName: Siti Mursyida Abdul Karim (Data Science Program) Topic: Assignment - EDAsiti mursyida100% (1)
- Test For Two Relates SamplesDocument48 pagesTest For Two Relates SamplesMiqz ZenNo ratings yet
- Brief Lecture NotesDocument13 pagesBrief Lecture NotesNazmul HudaNo ratings yet
- 8august2010 - Confidence Interval and Sample SizeDocument5 pages8august2010 - Confidence Interval and Sample SizeJOCELYN CAMACHONo ratings yet
- Final PPT Research Statistical Treatment of DataDocument12 pagesFinal PPT Research Statistical Treatment of DataAnalou Delfino100% (1)
- Data Science Interview QuestionsDocument300 pagesData Science Interview QuestionsMaheshBirajdar100% (1)
- Central Limit TheoremDocument46 pagesCentral Limit TheoremAneesh Gopinath 2027914No ratings yet
- Weebly Week of 4-27-15Document2 pagesWeebly Week of 4-27-15api-264567776No ratings yet
- Estimation of ParametersDocument37 pagesEstimation of ParametersReflecta123No ratings yet
- Worksheet - 3 Name-Sarah Nuzhat Khan ID-20175008Document6 pagesWorksheet - 3 Name-Sarah Nuzhat Khan ID-20175008Rupok ChowdhuryNo ratings yet
- Npar Tests: Npar Tests /K-S (Normal) Res - 1 /missing AnalysisDocument2 pagesNpar Tests: Npar Tests /K-S (Normal) Res - 1 /missing AnalysisHari Mas KuncoroNo ratings yet
- Mme 8201-4-Linear Regression ModelsDocument24 pagesMme 8201-4-Linear Regression ModelsJosephat KalanziNo ratings yet
- Semana 5parte 2 FinalDocument14 pagesSemana 5parte 2 FinalJoan VegaNo ratings yet
- PGP25116 - Soubhagya - Dash - DPolynomial RegressionDocument4 pagesPGP25116 - Soubhagya - Dash - DPolynomial RegressionSoubhagya DashNo ratings yet
- Constantine Habana Deber11Document4 pagesConstantine Habana Deber11HabanitaConstantineFrancoNo ratings yet
- 72 - P A G e Convenience Sampling: December 2022Document7 pages72 - P A G e Convenience Sampling: December 2022Wafaa HanyNo ratings yet
- Week 4 Seasonality ModelDocument14 pagesWeek 4 Seasonality ModelCico CocoNo ratings yet
- Econometrics For ECO 2022 Tutorial 6Document7 pagesEconometrics For ECO 2022 Tutorial 6HenkNo ratings yet
- Hypothesis Testing 1Document1 pageHypothesis Testing 1Debershi MitraNo ratings yet
- StatisticsDocument8 pagesStatisticsmarydahyllamarinduqueNo ratings yet
- Correlation Analysis 2Document15 pagesCorrelation Analysis 2ShahinNo ratings yet
- Confirmatory Factor AnalysisDocument8 pagesConfirmatory Factor Analysisolivia523No ratings yet
- Makalah Semhas - Hartinah Djalihu (Rev) PDFDocument12 pagesMakalah Semhas - Hartinah Djalihu (Rev) PDFanggitaNo ratings yet
- Chapter 13Document18 pagesChapter 13Kashif FaridNo ratings yet
- Lecture Note Chapter 10Document26 pagesLecture Note Chapter 10nain030510No ratings yet
- Propensity Score MatchingDocument40 pagesPropensity Score MatchingMizter. A. KnightsNo ratings yet
- Handout On Principles of SamplingDocument6 pagesHandout On Principles of SamplingClaudelle Mangubat100% (1)
- 1988 - On The Methodology of Selecting Design Wave Height - GodaDocument15 pages1988 - On The Methodology of Selecting Design Wave Height - GodaflpbravoNo ratings yet