You might also like
- A8557Document2 pagesA8557Nauman AliNo ratings yet
- Communication ProtocolsDocument23 pagesCommunication Protocolsphookandevraj100% (1)
- IMC-MG (42-02-6202 Rev B3)Document332 pagesIMC-MG (42-02-6202 Rev B3)ElputoAmo XDNo ratings yet
- Google - Real Exams - Professional Cloud DevOps Engineer.v2021!03!27.by - Louie.20qDocument11 pagesGoogle - Real Exams - Professional Cloud DevOps Engineer.v2021!03!27.by - Louie.20qLove Sahil SharmaNo ratings yet
- Standard Two-Storey School Building Philippines PG 1-8Document8 pagesStandard Two-Storey School Building Philippines PG 1-8JAY100% (1)
- Oltp Vs Datawarehouse DSSDocument2 pagesOltp Vs Datawarehouse DSSriteshkumar2kNo ratings yet
- Connected Lookup TransformationDocument26 pagesConnected Lookup TransformationDudi KumarNo ratings yet
- Modern Analytics With DBTDocument11 pagesModern Analytics With DBTCường VũNo ratings yet
- Ab Initio TrainingDocument103 pagesAb Initio Trainingsuperstarraj63% (8)
- Teradata Utilities Breaking The BarriersDocument128 pagesTeradata Utilities Breaking The Barriersvijayoec2009No ratings yet
- What Is Difference Between Server Jobs and Parallel Jobs? Ans:-Server JobsDocument71 pagesWhat Is Difference Between Server Jobs and Parallel Jobs? Ans:-Server JobsDinesh SanodiyaNo ratings yet
- Teradata Interview Prep QuestionsDocument52 pagesTeradata Interview Prep QuestionsRakshaNo ratings yet
- IDMC Best Practices and StandardsDocument27 pagesIDMC Best Practices and StandardsOrachai TassanamethinNo ratings yet
- Typical Interview QuestionsDocument11 pagesTypical Interview Questionssudas14No ratings yet
- Lesson Plan in Tle Computer Hardware andDocument7 pagesLesson Plan in Tle Computer Hardware andSJ BatallerNo ratings yet
- UBS OCF - IDQ Capabilities ReviewDocument15 pagesUBS OCF - IDQ Capabilities ReviewAmarnathMaitiNo ratings yet
- Olap Case Study - VJDocument16 pagesOlap Case Study - VJVijay S. GachandeNo ratings yet
- Netezza Oracle Configuration in DatastageDocument8 pagesNetezza Oracle Configuration in DatastagePraphulla RayalaNo ratings yet
- My Friends Has Attended ODIDocument5 pagesMy Friends Has Attended ODIचंदन जैसवालNo ratings yet
- GCP Data Engineer Course ContentDocument7 pagesGCP Data Engineer Course ContentAMIT DHOMNENo ratings yet
- Promotion PresentationDocument25 pagesPromotion PresentationDohaa NadeemNo ratings yet
- HP Proliant Server Foundation Test 01047329Document9 pagesHP Proliant Server Foundation Test 01047329Emerson0% (3)
- MDMMMMDocument14 pagesMDMMMMatulsharmarocksNo ratings yet
- Informatica AdminDocument13 pagesInformatica AdminVikas SinhaNo ratings yet
- Data Warehousing FAQDocument5 pagesData Warehousing FAQsrk78No ratings yet
- How To Obtain Flexible, Cost-Effective Scalability and Performance Through Pushdown ProcessingDocument16 pagesHow To Obtain Flexible, Cost-Effective Scalability and Performance Through Pushdown ProcessingAlok TiwaryNo ratings yet
- Elizabeth: ETL Informatica DeveloperDocument5 pagesElizabeth: ETL Informatica DeveloperJoshElliotNo ratings yet
- Seminar Topic NosqlDocument73 pagesSeminar Topic NosqlAnish ARNo ratings yet
- Notes On Dimension and FactsDocument32 pagesNotes On Dimension and FactsVamsi KarthikNo ratings yet
- Cuadernillo Actividades Ludicas PDFDocument209 pagesCuadernillo Actividades Ludicas PDFHector AbarcaNo ratings yet
- Informatica Powercenter 7.1 Basics: Education ServicesDocument287 pagesInformatica Powercenter 7.1 Basics: Education ServicesvijayinforNo ratings yet
- Scenario Based QuestionsDocument3 pagesScenario Based QuestionsJeffrey ReynoldsNo ratings yet
- Informatica Interview Questions (Scenario-Based) :: Source Qualifier Transformation Filter TransformationDocument59 pagesInformatica Interview Questions (Scenario-Based) :: Source Qualifier Transformation Filter TransformationSri Kanth SriNo ratings yet
- Ibm&accenture Datastage Faq'sDocument1 pageIbm&accenture Datastage Faq'sRameshRayal0% (1)
- Technic For Faster PL SQLDocument45 pagesTechnic For Faster PL SQLRob Abdur100% (2)
- PGSQL CheatSheet Mysql2psqlDocument7 pagesPGSQL CheatSheet Mysql2psqlkishore_m_kNo ratings yet
- Teradata CVDocument4 pagesTeradata CVkavitha221No ratings yet
- Resume of Ref No: Cjh647384 - Informatica MDM Specialist With 7 Years ExpDocument6 pagesResume of Ref No: Cjh647384 - Informatica MDM Specialist With 7 Years ExpSvr RaviNo ratings yet
- Oracle Fact Sheet 079219 PDFDocument2 pagesOracle Fact Sheet 079219 PDFGiovanni Serauto100% (1)
- Testing TemplateDocument5 pagesTesting Templatesaifrahman12349323No ratings yet
- Introduction To InformaticaDocument66 pagesIntroduction To InformaticaShravan KumarNo ratings yet
- Data Warehouse Concepts: by Mr. Umar Frauq & Mr. C. DivakarDocument58 pagesData Warehouse Concepts: by Mr. Umar Frauq & Mr. C. DivakarharishrjooriNo ratings yet
- Talend Big Data Data Transformation PigDocument8 pagesTalend Big Data Data Transformation PiggeoinsysNo ratings yet
- Battula Edukondalu: Good Experience inDocument3 pagesBattula Edukondalu: Good Experience innithinmamidala999No ratings yet
- Krishna - Informatica IICS DeveloperDocument11 pagesKrishna - Informatica IICS DeveloperjavadeveloperumaNo ratings yet
- Presented By: - Preeti Kudva (106887833) - Kinjal Khandhar (106878039)Document72 pagesPresented By: - Preeti Kudva (106887833) - Kinjal Khandhar (106878039)archna27No ratings yet
- Unica Campaign 850 Administrators GuideDocument490 pagesUnica Campaign 850 Administrators Guidekrzysio1972100% (1)
- Cog 1Document24 pagesCog 1pavanm84No ratings yet
- Informatica MDM High AvailabilityDocument6 pagesInformatica MDM High AvailabilitySourajit MitraNo ratings yet
- DataStage MatterDocument81 pagesDataStage MatterShiva Kumar0% (1)
- Project XplanationDocument4 pagesProject Xplanationvenkata ganga dhar gorrelaNo ratings yet
- IDQ ReferenceDocument31 pagesIDQ ReferenceRaman DekuNo ratings yet
- Qdoc - Tips Datastage-MaterialDocument40 pagesQdoc - Tips Datastage-MaterialRanji DhawanNo ratings yet
- INFORMATICA-Performance TuningDocument21 pagesINFORMATICA-Performance Tuningsvprasad.t100% (9)
- Answers 2Document202 pagesAnswers 2Miguel Angel HernandezNo ratings yet
- Vanishree-Sr. Informatica DeveloperDocument5 pagesVanishree-Sr. Informatica DeveloperJoshElliotNo ratings yet
- Introduction To ETL and DataStageDocument48 pagesIntroduction To ETL and DataStageRavi MNo ratings yet
- IDQ Mappings From Cleanse FunctionsDocument4 pagesIDQ Mappings From Cleanse FunctionsVenkata Sri HarshaNo ratings yet
- Unit 3 - OLAPDocument107 pagesUnit 3 - OLAPPARAZZINo ratings yet
- Foursquare & MongoDBDocument14 pagesFoursquare & MongoDBEnlightment ChenNo ratings yet
- Deepmerge Readthedocs Io en StableDocument17 pagesDeepmerge Readthedocs Io en StablepavankshrNo ratings yet
- Saroavr Terms Condition UldznaDocument1 pageSaroavr Terms Condition UldznapavankshrNo ratings yet
- Big Query Technical WPDocument26 pagesBig Query Technical WPpavankshrNo ratings yet
- Importance: Tomatoes Are Very Healthy As They Are A Good Source ofDocument11 pagesImportance: Tomatoes Are Very Healthy As They Are A Good Source ofpavankshrNo ratings yet
- DS 2CD7026G0'EP I (H) Datasheet - V5.5.62 - 20190404Document5 pagesDS 2CD7026G0'EP I (H) Datasheet - V5.5.62 - 20190404Kyaw Soe HlaingNo ratings yet
- HP Placement PapersDocument0 pagesHP Placement PapersApoorva PrabhuNo ratings yet
- City Montecristi : HistoryDocument4 pagesCity Montecristi : HistoryroxyNo ratings yet
- Accounting 497Document24 pagesAccounting 497perro_mxNo ratings yet
- Trace Log 20131229152625Document3 pagesTrace Log 20131229152625Razvan PaleaNo ratings yet
- Week 2Document12 pagesWeek 2Bilal Al-MuhtasebNo ratings yet
- Apple ImageWriter LQ Service SourceDocument18 pagesApple ImageWriter LQ Service SourceBeTeck Soc CoopNo ratings yet
- LTE Network Architecture - BasicDocument9 pagesLTE Network Architecture - BasicTELECOM INJINIYANo ratings yet
- Compare E1 and CARB - ApphDocument10 pagesCompare E1 and CARB - Apphmshafiey0% (1)
- Transmission Line Multiple Fault Detection and Indication To Electricity BoardDocument74 pagesTransmission Line Multiple Fault Detection and Indication To Electricity BoardCrisp100% (1)
- Flovent Demo Feb06!09!05-06Document59 pagesFlovent Demo Feb06!09!05-06Rawnee HoNo ratings yet
- LSF Users GuideDocument53 pagesLSF Users GuideSav SuiNo ratings yet
- Beamng DxdiagDocument32 pagesBeamng DxdiagANDREW FARRINGTON (Student)No ratings yet
- RI Rehabilitation Building and Fire CodeDocument59 pagesRI Rehabilitation Building and Fire Codehayeska3527No ratings yet
- 177: 1 Cross Brook Cottages, Trefil, Blaenau Gwent. Building RecordingDocument42 pages177: 1 Cross Brook Cottages, Trefil, Blaenau Gwent. Building RecordingAPAC LtdNo ratings yet
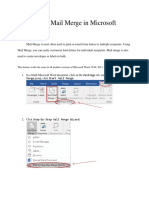
- How To Use Mail Merge in Microsoft WordDocument15 pagesHow To Use Mail Merge in Microsoft WordAvegail MantesNo ratings yet
- Paper Review 1 - Google File SystemDocument2 pagesPaper Review 1 - Google File Systemvicky.vetalNo ratings yet
- Control Area Network (CAN) Tutorial - ElectroSoftsDocument6 pagesControl Area Network (CAN) Tutorial - ElectroSoftsDeepak Reddy100% (1)
- 12 OS Security WorkshopDocument121 pages12 OS Security Workshopbalamurali_a100% (1)
- 58PAV, 58RAV Induced-Combustion Furnaces Service and Maintenance InstructionsDocument16 pages58PAV, 58RAV Induced-Combustion Furnaces Service and Maintenance InstructionsAnonymous oTrMzaNo ratings yet
- 1.internal Concrete Pour Register Updated On 25-01-2023Document9 pages1.internal Concrete Pour Register Updated On 25-01-2023721917114 47No ratings yet
- Bamboo Construction: January 2019Document30 pagesBamboo Construction: January 2019Mark Eli RebustilloNo ratings yet
- (STD 001) Procedures For Steel Grating Panels7FCEAAD7245BDocument1 page(STD 001) Procedures For Steel Grating Panels7FCEAAD7245BWalter E. PinillosNo ratings yet