You might also like
- Blue and White Modern Technology Portfolio PresentationDocument13 pagesBlue and White Modern Technology Portfolio Presentationchetan jangirNo ratings yet
- Discrete Mathamethics: Algorithm Makes Google Map PossibleDocument16 pagesDiscrete Mathamethics: Algorithm Makes Google Map Possiblechetan jangirNo ratings yet
- AI_Lab ManualDocument25 pagesAI_Lab Manualharsh.sb03No ratings yet
- Design and Implementation of Pathfinding Algorithms in Unity 3DDocument11 pagesDesign and Implementation of Pathfinding Algorithms in Unity 3DIJRASETPublicationsNo ratings yet
- Path Finding and Sorting Algorithm VisualizerDocument51 pagesPath Finding and Sorting Algorithm VisualizerKunal GargNo ratings yet
- Navigation and Wayfinding in VideogamesDocument9 pagesNavigation and Wayfinding in Videogamesanon_952027728No ratings yet
- Graph Analytics For Python DevelopersDocument15 pagesGraph Analytics For Python DevelopersFufun DanyNo ratings yet
- Computer Science and Engineering: Course Title: Algorithms LabDocument9 pagesComputer Science and Engineering: Course Title: Algorithms Labpubji gamerNo ratings yet
- Path Planning For Unmanned Ground Vehicle: Fethi DEMIM, Kahina LOUADJ, Abdelkrim NEMRADocument3 pagesPath Planning For Unmanned Ground Vehicle: Fethi DEMIM, Kahina LOUADJ, Abdelkrim NEMRAAmal KekliNo ratings yet
- 01712818Document6 pages01712818frozen3592No ratings yet
- International Open UniversityDocument10 pagesInternational Open UniversityMoh'd Khamis SongoroNo ratings yet
- Breadth First Search (BFS) Depth First Search (DFS) A-Star Search (A ) Minimax Algorithm Alpha-Beta PruningDocument31 pagesBreadth First Search (BFS) Depth First Search (DFS) A-Star Search (A ) Minimax Algorithm Alpha-Beta Pruninglevecem778No ratings yet
- Final ProjectDocument7 pagesFinal ProjectanuNo ratings yet
- A Path Finding Visualization Using A Star Algorithm and Dijkstra's AlgorithmDocument2 pagesA Path Finding Visualization Using A Star Algorithm and Dijkstra's AlgorithmEditor IJTSRD100% (1)
- 18bce0537 VL2020210104308 Pe003Document31 pages18bce0537 VL2020210104308 Pe003CHALASANI AKHIL CHOWDARY 19BCE2390No ratings yet
- Graph Based Algorithms - NotesDocument5 pagesGraph Based Algorithms - Notessathwik vaguNo ratings yet
- Sankalp Saurav Dash 2101020114 Exp Learning PDFDocument19 pagesSankalp Saurav Dash 2101020114 Exp Learning PDFStupid IdiotNo ratings yet
- Implement Dijkstra's AlgorithmDocument4 pagesImplement Dijkstra's AlgorithmSharad KumbharanaNo ratings yet
- Useful Algorithms and Programming TechniqueDocument9 pagesUseful Algorithms and Programming TechniqueRahul JainNo ratings yet
- Search Algorithms in AI6Document17 pagesSearch Algorithms in AI6jhn75070No ratings yet
- Quiz#03: Q1. What Is A and Its Concepts?Document4 pagesQuiz#03: Q1. What Is A and Its Concepts?Abu Huraira Sohiab AkhtarNo ratings yet
- Path Visualizer: Gaurav Rana 01 Abhishek Kumar Singh 17 Adarsh Singh 18 Mentor-Mrs. Huda KhanDocument18 pagesPath Visualizer: Gaurav Rana 01 Abhishek Kumar Singh 17 Adarsh Singh 18 Mentor-Mrs. Huda KhanNEWNo ratings yet
- Ashish Worksheet 3.2Document3 pagesAshish Worksheet 3.2Adarsh KumarNo ratings yet
- Dijkstra's Algorithm Case Study Explains Shortest Path FindingDocument2 pagesDijkstra's Algorithm Case Study Explains Shortest Path FindingSahil SarwarNo ratings yet
- Department of Computer Science and Engineering C.V.Raman Global University, BhubaneswarDocument11 pagesDepartment of Computer Science and Engineering C.V.Raman Global University, BhubaneswarSaket AnandNo ratings yet
- Algorithm Study: A Search: 1 BackgroundDocument6 pagesAlgorithm Study: A Search: 1 Backgroundsophors-khut-9252No ratings yet
- Lab19 DijkastraDocument8 pagesLab19 DijkastraSarvesh YadavNo ratings yet
- Design and Analysis of Algorithms (COM336) : Dijkstra's AlgorithmDocument3 pagesDesign and Analysis of Algorithms (COM336) : Dijkstra's AlgorithmffNo ratings yet
- Shortest Path AlgorithmsDocument5 pagesShortest Path AlgorithmsRonak PanchalNo ratings yet
- Graph Theory As A Shortest Path Generator - FirstSem2021 - 6037 - GE MMW - Mathematics in The Modern WorldDocument1 pageGraph Theory As A Shortest Path Generator - FirstSem2021 - 6037 - GE MMW - Mathematics in The Modern WorldShanylle PrayonNo ratings yet
- Mini - Project - Template (RA2011003010649)Document15 pagesMini - Project - Template (RA2011003010649)HARIHARAN M (RA2011003010620)No ratings yet
- P F S F G B G: ATH Inding Olutions OR RID Ased RaphDocument10 pagesP F S F G B G: ATH Inding Olutions OR RID Ased RaphAnonymous IlrQK9HuNo ratings yet
- Find Shortest Flight Route Between Cities Using AlgorithmsDocument12 pagesFind Shortest Flight Route Between Cities Using AlgorithmsPéter NguyenNo ratings yet
- Memory-Efficient Fast Shortest Path Estimation in Large Social NetworksDocument10 pagesMemory-Efficient Fast Shortest Path Estimation in Large Social NetworksxkjonNo ratings yet
- D AAApblfinalDocument26 pagesD AAApblfinalabyefinalhaiNo ratings yet
- Faculty of Computers & Informatics, Zagazig UniversityDocument10 pagesFaculty of Computers & Informatics, Zagazig UniversityMohamed NasserNo ratings yet
- Exp4 CN 60004200044Document7 pagesExp4 CN 60004200044bhavik shahNo ratings yet
- Finding the Most Efficient Shortest Path AlgorithmDocument16 pagesFinding the Most Efficient Shortest Path AlgorithmPranjal KapurNo ratings yet
- Dijkstra's Algorithm: Project TitleDocument13 pagesDijkstra's Algorithm: Project TitleAkul SrinidhiNo ratings yet
- Pathfinding and Graph Search AlgorithmsDocument15 pagesPathfinding and Graph Search AlgorithmsNasser SalehNo ratings yet
- Fast Detour Computation For Ride Sharing: Robert Geisberger, Dennis Luxen, Sabine Neubauer, Peter Sanders, Lars VolkerDocument5 pagesFast Detour Computation For Ride Sharing: Robert Geisberger, Dennis Luxen, Sabine Neubauer, Peter Sanders, Lars Volkermadan321No ratings yet
- BFS Algorithm Guide for Graph Traversal & ApplicationsDocument5 pagesBFS Algorithm Guide for Graph Traversal & ApplicationsYashwanth gowdaNo ratings yet
- A Algorithem and Why It Is Better Then DFS. Situations A AlgorithemDocument9 pagesA Algorithem and Why It Is Better Then DFS. Situations A AlgorithemSarmad TabassumNo ratings yet
- Case StudyDocument10 pagesCase Studykuldeepsingh262003No ratings yet
- Route Planning with Flexible Objective FunctionsDocument14 pagesRoute Planning with Flexible Objective Functionsmadan321No ratings yet
- Pathfinding in Game DevelopmentDocument10 pagesPathfinding in Game DevelopmentSyahrandy WaskitoNo ratings yet
- CSE 231 - Computer Algorithm AssignmentDocument5 pagesCSE 231 - Computer Algorithm AssignmentAbu BasharNo ratings yet
- Dijkstra's Algorithm ExperimentDocument6 pagesDijkstra's Algorithm ExperimentLeiNo ratings yet
- Solution of Data Structure ST-2 PDFDocument21 pagesSolution of Data Structure ST-2 PDFharshitNo ratings yet
- CS5011-report-220016150Document9 pagesCS5011-report-220016150drferns16No ratings yet
- Background TheoryDocument15 pagesBackground TheoryTay Zar NaungNo ratings yet
- Combining Speedup Techniques Based On Landmarks and Containers With Parallelised Preprocessing in Random and Planar GraphsDocument20 pagesCombining Speedup Techniques Based On Landmarks and Containers With Parallelised Preprocessing in Random and Planar GraphsAnonymous Gl4IRRjzNNo ratings yet
- Graphs: by Sonia SoansDocument18 pagesGraphs: by Sonia SoanstvsnNo ratings yet
- ADS PPT A Division Grp18Document19 pagesADS PPT A Division Grp18Ojas YouNo ratings yet
- Phase2 Report1 UpdatedDocument17 pagesPhase2 Report1 Updatedmohammed naifNo ratings yet
- 54-Article Text-200-2-10-20230107Document9 pages54-Article Text-200-2-10-20230107Ganesh PanigrahiNo ratings yet
- Algorithms Lab Ex 7Document5 pagesAlgorithms Lab Ex 7pixaho2996No ratings yet
- Analog Electronics Lab File: Delhi Technological UniversityDocument6 pagesAnalog Electronics Lab File: Delhi Technological Universitychetan jangirNo ratings yet
- Analog Electronics Lab File: Delhi Technological UniversityDocument5 pagesAnalog Electronics Lab File: Delhi Technological Universitychetan jangirNo ratings yet
- EC 261 Analog Electronics Lab FileDocument6 pagesEC 261 Analog Electronics Lab Filechetan jangirNo ratings yet
- MTE Project Proposal by 2K20 - CO - 130,& 2K20 - CO - 144Document3 pagesMTE Project Proposal by 2K20 - CO - 130,& 2K20 - CO - 144chetan jangirNo ratings yet
- Discrete Structure Proposal 1Document5 pagesDiscrete Structure Proposal 1chetan jangirNo ratings yet
- सरदार वल्लभ भाई पटेलDocument2 pagesसरदार वल्लभ भाई पटेलchetan jangirNo ratings yet
- Aits 1819 PT III Jeem PCMDocument20 pagesAits 1819 PT III Jeem PCMLohit DakshaNo ratings yet
- Aits 1819 PT III Jeem PCMDocument20 pagesAits 1819 PT III Jeem PCMLohit DakshaNo ratings yet
- Channel CapDocument9 pagesChannel CapDeepika RastogiNo ratings yet
- Excel calendarDocument28 pagesExcel calendarThanh LêNo ratings yet
- Office & Branches: Head Office PT Indosat Mega Media (IM2)Document4 pagesOffice & Branches: Head Office PT Indosat Mega Media (IM2)satriamesumNo ratings yet
- This Study Resource WasDocument6 pagesThis Study Resource WasRian RorresNo ratings yet
- Intel Optane Memory User InstallationDocument57 pagesIntel Optane Memory User InstallationAlonso LGNo ratings yet
- Mobile Banking Prospects Problems BangladeshDocument20 pagesMobile Banking Prospects Problems BangladeshabrarNo ratings yet
- Study of Diesel Fuel Pumps ComponentsDocument6 pagesStudy of Diesel Fuel Pumps ComponentsPro GamerssNo ratings yet
- Passive Fire Protection PDFDocument7 pagesPassive Fire Protection PDFVictor SampaNo ratings yet
- Melissa Wanstall March 2016Document2 pagesMelissa Wanstall March 2016api-215567355No ratings yet
- 11608-Driving Women Fiction and PDFDocument240 pages11608-Driving Women Fiction and PDFAleksi KnuutilaNo ratings yet
- 638341140 (1)Document7 pages638341140 (1)Nishit BhanushaliNo ratings yet
- File 5119 PDFDocument5 pagesFile 5119 PDFIsabele LavadoNo ratings yet
- 1 Introduction To Electrical DrivesDocument45 pages1 Introduction To Electrical DrivesSetya Ardhi67% (3)
- Unit 1Document176 pagesUnit 1kassahun meseleNo ratings yet
- DATACOM Multiple Choice Question 6Document1 pageDATACOM Multiple Choice Question 6girijamohapatraNo ratings yet
- Hi Flow GroutDocument2 pagesHi Flow Groutpravi3434No ratings yet
- Electricity (Innovative Licence) Regulations 2023Document16 pagesElectricity (Innovative Licence) Regulations 2023BernewsAdminNo ratings yet
- Microeconomics Primer 1Document15 pagesMicroeconomics Primer 1md1sabeel1ansariNo ratings yet
- Whitmer Unveils Proposed 2022 Michigan BudgetDocument187 pagesWhitmer Unveils Proposed 2022 Michigan BudgetWXYZ-TV Channel 7 DetroitNo ratings yet
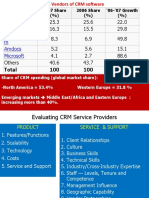
- CRM Vendors, Vendor SelectionDocument7 pagesCRM Vendors, Vendor SelectionsanamkmNo ratings yet
- Token Economics BookDocument81 pagesToken Economics BookNara E Aí100% (3)
- Presentation On AIR POWERED VEHICLEDocument26 pagesPresentation On AIR POWERED VEHICLEVishal SrivastavaNo ratings yet
- Sk200-8 Sk210lc-8 Super AsiaDocument16 pagesSk200-8 Sk210lc-8 Super AsiaAnwar Rashid86% (7)
- 11.30 Imran Akram IA CementDocument12 pages11.30 Imran Akram IA CementParamananda SinghNo ratings yet
- Resolution No. 100 - Ease of Doing BusinessDocument2 pagesResolution No. 100 - Ease of Doing BusinessTeamBamAquinoNo ratings yet
- TBelt - 02Document46 pagesTBelt - 02prasanthme34No ratings yet
- 1978 Damage - To Rock Tunnels From Earthquake ShakingDocument18 pages1978 Damage - To Rock Tunnels From Earthquake Shakingofelix505100% (1)
- Tesco AnalysisDocument12 pagesTesco Analysisdanny_wch7990No ratings yet
- Ryanair Strategic AnalysisDocument36 pagesRyanair Strategic AnalysisAlmas Uddin100% (1)
- UI UX Research DesignDocument7 pagesUI UX Research DesignSomya ShrivastavaNo ratings yet