You might also like
- C & C++ Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandC & C++ Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- SummaryDocument36 pagesSummaryAnam KhalidNo ratings yet
- Arabic OCR ReportDocument20 pagesArabic OCR ReportAmirNo ratings yet
- Image Classification: KerasDocument21 pagesImage Classification: KerasDevyansh GuptaNo ratings yet
- L8 - Image ClassificationDocument20 pagesL8 - Image ClassificationKunapuli PoojithaNo ratings yet
- Transfer Learning and Fine-TuningDocument32 pagesTransfer Learning and Fine-TuningDevyansh GuptaNo ratings yet
- Tensors - Training A Model in Keras - Character Recognition Example - MINSTDocument25 pagesTensors - Training A Model in Keras - Character Recognition Example - MINSTsatitekmNo ratings yet
- Keras Sequential Model GuideDocument25 pagesKeras Sequential Model GuideDevyansh GuptaNo ratings yet
- CNN Explainer: What are Convolutional Neural NetworksDocument17 pagesCNN Explainer: What are Convolutional Neural Networksandres alfonso varelo silgadoNo ratings yet
- House Price Prediction: Project DescriptionDocument11 pagesHouse Price Prediction: Project DescriptionPOLURU SUMANTH NAIDU STUDENT - CSENo ratings yet
- L6 - Sequential ModelDocument22 pagesL6 - Sequential ModelKunapuli PoojithaNo ratings yet
- Augmentation and SegmentationDocument32 pagesAugmentation and SegmentationTanmay SahuNo ratings yet
- UNIT 2 Self NotesDocument10 pagesUNIT 2 Self NotesjainayushtechNo ratings yet
- CNN Implementation in PythonDocument7 pagesCNN Implementation in PythonMuhammad UsmanNo ratings yet
- Pattern Recognition and Machine Learning - 2022 Winter SemesterDocument19 pagesPattern Recognition and Machine Learning - 2022 Winter SemesterIshaan Shrivastava (B20AI013)No ratings yet
- Coding Neural Networks-Classification & RegressionDocument39 pagesCoding Neural Networks-Classification & RegressionHasanur RahmanNo ratings yet
- PyTorch Plus Computer Vision - Aravind AriharasudhanDocument28 pagesPyTorch Plus Computer Vision - Aravind AriharasudhanAravind AriharasudhanNo ratings yet
- Building Good Training Sets UNIT 1 PART2Document46 pagesBuilding Good Training Sets UNIT 1 PART2Aditya SharmaNo ratings yet
- Image Category Classification Using Deep LearningDocument11 pagesImage Category Classification Using Deep LearningHoàng Ngọc CảnhNo ratings yet
- DL Mannual For ReferenceDocument58 pagesDL Mannual For ReferenceDevant PajgadeNo ratings yet
- VINEELA ANN1Document9 pagesVINEELA ANN1vineelaNo ratings yet
- L7 - Functional APIDocument14 pagesL7 - Functional APIKunapuli PoojithaNo ratings yet
- Big Data Machine Learning Lab 4Document7 pagesBig Data Machine Learning Lab 4fahim.samady2001No ratings yet
- A Neural Network Model Using PythonDocument10 pagesA Neural Network Model Using PythonKarol SkowronskiNo ratings yet
- CS 475/675 Machine Learning: Homework 3 VisualizationsDocument8 pagesCS 475/675 Machine Learning: Homework 3 VisualizationsAli ZainNo ratings yet
- Project PresentationDocument28 pagesProject PresentationSathiya VaniNo ratings yet
- Efficient Net B0Document4 pagesEfficient Net B0NavyaNo ratings yet
- Project TitleDocument4 pagesProject TitleIezma MadzinNo ratings yet
- KT 01 Intro2KerasDocument24 pagesKT 01 Intro2KerasBalaji VenkateswaranNo ratings yet
- CVPDL hw3Document26 pagesCVPDL hw3評No ratings yet
- C1W3_Improve MNIST with ConvolutionsDocument7 pagesC1W3_Improve MNIST with ConvolutionsRainata PutraNo ratings yet
- Image Classifier ReportDocument7 pagesImage Classifier ReportOrlan GaliyNo ratings yet
- DCGAN (Deep Convolution Generative Adversarial Networks)Document27 pagesDCGAN (Deep Convolution Generative Adversarial Networks)lakpa tamangNo ratings yet
- Assignment 2 W2024 (4)Document1 pageAssignment 2 W2024 (4)Menatalla KhedrNo ratings yet
- Kenny-230718-The Ultimate Machine Learning Cheat SheetDocument20 pagesKenny-230718-The Ultimate Machine Learning Cheat SheetvanjchaoNo ratings yet
- Anomaly Detection in Images CIFAR-10Document9 pagesAnomaly Detection in Images CIFAR-10Mallikarjun patilNo ratings yet
- Unit 5Document12 pagesUnit 5Subbu mailNo ratings yet
- Machine Learning Unit 3Document40 pagesMachine Learning Unit 3read4freeNo ratings yet
- Deep learning time series Keras case studyDocument34 pagesDeep learning time series Keras case studyJorgeMoisesNo ratings yet
- Computer Vision NN ArchitectureDocument19 pagesComputer Vision NN ArchitecturePrasu MuthyalapatiNo ratings yet
- ML Lab Session 05 - CNN ImplementationDocument4 pagesML Lab Session 05 - CNN Implementationchatgptlogin2001No ratings yet
- Assignment 5 - NNDocument4 pagesAssignment 5 - NNthecoolguy96No ratings yet
- Deep LearningDocument43 pagesDeep LearningNen ManchodniNo ratings yet
- DL7Document42 pagesDL7Sandesh PokhrelNo ratings yet
- DL7.1Document19 pagesDL7.1Sandesh PokhrelNo ratings yet
- hw1 Problem SetDocument8 pageshw1 Problem SetBilly bobNo ratings yet
- Image ClassificationDocument18 pagesImage ClassificationDarshna GuptaNo ratings yet
- Ker As TutorialDocument33 pagesKer As TutorialYoann DragneelNo ratings yet
- Week 02 Ch2.1 Introduction To Neural NetworksDocument44 pagesWeek 02 Ch2.1 Introduction To Neural Networksgunduz.gizemNo ratings yet
- Improve The Accuracy of A CNN Layer in Deep LearningDocument14 pagesImprove The Accuracy of A CNN Layer in Deep LearningRahma RhmaNo ratings yet
- data_aug_transDocument4 pagesdata_aug_transmavoho1719No ratings yet
- Ass3 v1Document4 pagesAss3 v1Reeya PrakashNo ratings yet
- "I C U N N ": Mage Lassification Sing Eural EtworksDocument15 pages"I C U N N ": Mage Lassification Sing Eural Etworksbabloo veluvoluNo ratings yet
- Lecture 2 - Hello World in MLDocument49 pagesLecture 2 - Hello World in MLYi HengNo ratings yet
- MODULE 2 Deep LearningDocument26 pagesMODULE 2 Deep LearningENG20DS0040 SukruthaGNo ratings yet
- Module 5Document72 pagesModule 5prattyush1234No ratings yet
- Bangla Hand Written Digit RecognitionDocument19 pagesBangla Hand Written Digit RecognitionKhondoker Abu NaimNo ratings yet
- Deep Learning Sec4Document18 pagesDeep Learning Sec4sama ghorabNo ratings yet
- Homework: Prediction Methods and Machine LearningDocument3 pagesHomework: Prediction Methods and Machine LearningHadare IdrissouNo ratings yet
- 6 CNNDocument50 pages6 CNNSWAMYA RANJAN DASNo ratings yet
- Unit 5Document20 pagesUnit 5Devyansh GuptaNo ratings yet
- Lecture 6 Environment Act, 1986Document4 pagesLecture 6 Environment Act, 1986Devyansh GuptaNo ratings yet
- ETHICAL ISSUES IN HRM: Fairness & RightsDocument9 pagesETHICAL ISSUES IN HRM: Fairness & RightsDevyansh GuptaNo ratings yet
- Lecture 7 Ethical Issues of Financial ReportingDocument5 pagesLecture 7 Ethical Issues of Financial ReportingDevyansh GuptaNo ratings yet
- CSR - A Strategic Tool For BusinessDocument19 pagesCSR - A Strategic Tool For BusinessDevyansh GuptaNo ratings yet
- Scala NotesDocument71 pagesScala NotesDevyansh GuptaNo ratings yet
- Unit 1Document14 pagesUnit 1Devyansh GuptaNo ratings yet
- Indian Partnership ActDocument5 pagesIndian Partnership ActDevyansh GuptaNo ratings yet
- Slides - Module 5Document36 pagesSlides - Module 5VISHNU KNo ratings yet
- Unit 3Document17 pagesUnit 3Devyansh GuptaNo ratings yet
- Lecture 16 MGNM571Document14 pagesLecture 16 MGNM571Devyansh GuptaNo ratings yet
- Unit 2Document13 pagesUnit 2Devyansh GuptaNo ratings yet
- Lecture 0Document33 pagesLecture 0Devyansh GuptaNo ratings yet
- Lecture 18 MGNM571Document33 pagesLecture 18 MGNM571Devyansh GuptaNo ratings yet
- What Is Linear RegressionDocument2 pagesWhat Is Linear RegressionDevyansh GuptaNo ratings yet
- Lecture 8.2 (Capm and Apt)Document30 pagesLecture 8.2 (Capm and Apt)Devyansh GuptaNo ratings yet
- Unit 2 Measures of Central Tendency: Dr. Pooja Kansra Associate Professor Mittal School of BusinessDocument49 pagesUnit 2 Measures of Central Tendency: Dr. Pooja Kansra Associate Professor Mittal School of BusinessDevyansh GuptaNo ratings yet
- Ensemble Learning TechniquesDocument4 pagesEnsemble Learning TechniquesDevyansh GuptaNo ratings yet
- Lecture 2.3 (Risk and Return)Document47 pagesLecture 2.3 (Risk and Return)Devyansh GuptaNo ratings yet
- Lecture 1 (Introduction To Security Analysis)Document44 pagesLecture 1 (Introduction To Security Analysis)Devyansh GuptaNo ratings yet
- Beta and CAPM Risk CalculationDocument17 pagesBeta and CAPM Risk CalculationDevyansh GuptaNo ratings yet
- QTTM509 Research Methodology-I: What It's All About?Document30 pagesQTTM509 Research Methodology-I: What It's All About?Devyansh GuptaNo ratings yet
- EMH Market EfficiencyDocument46 pagesEMH Market EfficiencyDevyansh GuptaNo ratings yet
- Lecture on Median, Mode, Quartiles and PercentilesDocument32 pagesLecture on Median, Mode, Quartiles and PercentilesDevyansh GuptaNo ratings yet
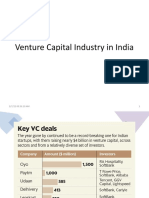
- Venture Capital Industry in IndiaDocument69 pagesVenture Capital Industry in IndiaDevyansh GuptaNo ratings yet
- Lecture (Free Cash Flow Model - DDM)Document23 pagesLecture (Free Cash Flow Model - DDM)Devyansh GuptaNo ratings yet
- Lecture 2.1 (Risk and Return)Document40 pagesLecture 2.1 (Risk and Return)Devyansh GuptaNo ratings yet
- Lecture3 Creation of Matric and ArrayDocument2 pagesLecture3 Creation of Matric and ArrayDevyansh GuptaNo ratings yet
- Time Series Analysis and Forecasting with ARIMADocument6 pagesTime Series Analysis and Forecasting with ARIMADevyansh GuptaNo ratings yet
- ZA Thought Leadership Investment Banking Repro PDFDocument12 pagesZA Thought Leadership Investment Banking Repro PDFMatthew LiewNo ratings yet
- Image Style Transfer Based On DeepLabV3 Semantic SDocument11 pagesImage Style Transfer Based On DeepLabV3 Semantic SZAHRA FASKANo ratings yet
- PCI Express CEM 1.1Document90 pagesPCI Express CEM 1.1MinlongerNo ratings yet
- Computer Networking Topologies and Transmission Media QuizDocument43 pagesComputer Networking Topologies and Transmission Media QuizSantosh PhatangareNo ratings yet
- SG125CX DatasheetDocument2 pagesSG125CX DatasheetJun OrtizNo ratings yet
- 5W 7H 7Z DMS Service D5W-40-025 Rev.ØDocument426 pages5W 7H 7Z DMS Service D5W-40-025 Rev.ØRubén DíazNo ratings yet
- Types of Data TransmissionDocument11 pagesTypes of Data TransmissionsunriseformoneNo ratings yet
- Errors While Importing Matplotlib:: General FAQ's of Week-3 (PDS)Document5 pagesErrors While Importing Matplotlib:: General FAQ's of Week-3 (PDS)Ragunathan SmgNo ratings yet
- Cambridge IGCSE: Computer Science 0478/21Document12 pagesCambridge IGCSE: Computer Science 0478/21Shop AliceNo ratings yet
- DB2 Purescale V11.5.6 Step by Step On RHEL8.1Document16 pagesDB2 Purescale V11.5.6 Step by Step On RHEL8.1legionario15No ratings yet
- Islem BenFraj CV Sep 2021Document1 pageIslem BenFraj CV Sep 2021saraaNo ratings yet
- D60 IndicatorDocument2 pagesD60 IndicatorThemaster withinNo ratings yet
- Reliability Evaluation of Fire Extinguisher - An Innovative Safety ApproachDocument4 pagesReliability Evaluation of Fire Extinguisher - An Innovative Safety ApproachInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- ESP-WROOM-32D/ESP32-WROOM-32U Datasheet: Espressif SystemsDocument25 pagesESP-WROOM-32D/ESP32-WROOM-32U Datasheet: Espressif SystemsVictor Hernandez MedinaNo ratings yet
- Web Design and Development FundamentalsDocument23 pagesWeb Design and Development FundamentalsFaryal FatimaNo ratings yet
- How to Mix Secondary Colors in ArtDocument5 pagesHow to Mix Secondary Colors in Artpankaj kararNo ratings yet
- Dbms FinalDocument25 pagesDbms FinalSunny VarshneyNo ratings yet
- Writing Diary, Memo, Job Vacancy, Application Letter, and Curriculum VitaeDocument20 pagesWriting Diary, Memo, Job Vacancy, Application Letter, and Curriculum Vitaemarnita sdn002No ratings yet
- Data Sheet 6GK7343-1CX10-0XE0: Transfer RateDocument3 pagesData Sheet 6GK7343-1CX10-0XE0: Transfer RateTrong Hung NguyenNo ratings yet
- Risk Score 0 Vulnerabilities: Useful LinksDocument5 pagesRisk Score 0 Vulnerabilities: Useful LinksMannan KhanNo ratings yet
- RMiT ApendicesDocument14 pagesRMiT ApendicesSoda JuiNo ratings yet
- Year 6 Mathematics 2019 Summer White Rose Reasoning Problem Solving Paper 2Document24 pagesYear 6 Mathematics 2019 Summer White Rose Reasoning Problem Solving Paper 2WISE EducationNo ratings yet
- Year 1 - Objective Coverage - SummerDocument5 pagesYear 1 - Objective Coverage - SummerALI AHMEDNo ratings yet
- Name List Correction 1Document11 pagesName List Correction 1THIRUNAVUKKARASU ENo ratings yet
- Introduction to IoT: What is it and How Does it WorkDocument11 pagesIntroduction to IoT: What is it and How Does it WorkOliver BenjaminNo ratings yet
- Guru Gobind Singh College For Women Prospectus 2020-21Document55 pagesGuru Gobind Singh College For Women Prospectus 2020-21Blue AceNo ratings yet
- Naveen Resume PDFDocument6 pagesNaveen Resume PDFNaveen ONo ratings yet
- C++ function pointers guide: How to declare, define and call functions using pointersDocument146 pagesC++ function pointers guide: How to declare, define and call functions using pointersPrasad MahajanNo ratings yet
- MELC Grade 10 1st To 4thDocument8 pagesMELC Grade 10 1st To 4thJoey De LunaNo ratings yet
- Mopping Module Design and Experiments of A Multifunction Floor Cleaning RobotDocument6 pagesMopping Module Design and Experiments of A Multifunction Floor Cleaning RobotAntonio MoisesNo ratings yet
- Boost Awareness, Communicate Purpose to Drive Change in Customer FocusDocument2 pagesBoost Awareness, Communicate Purpose to Drive Change in Customer FocusDebjani DeyNo ratings yet