You might also like
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Machine Learning - SVMDocument11 pagesMachine Learning - SVMnagybalyNo ratings yet
- CIS536 - Tool - Loss Function Cheat SheetDocument1 pageCIS536 - Tool - Loss Function Cheat SheetyohhongNo ratings yet
- Intro 2 MLDocument162 pagesIntro 2 MLtherealj6ixNo ratings yet
- SVM Hands-On ProblemDocument7 pagesSVM Hands-On Problemishtiaque3044No ratings yet
- ML Logistic RegressionDocument19 pagesML Logistic RegressionZarfa MasoodNo ratings yet
- An Introduction To Support Vector Machines: Biplab BanerjeeDocument31 pagesAn Introduction To Support Vector Machines: Biplab BanerjeeAkshat sharmaNo ratings yet
- Pattern Recognition & Learning II: © UW CSE Vision FacultyDocument47 pagesPattern Recognition & Learning II: © UW CSE Vision FacultyDuong TheNo ratings yet
- Lecture 2 - LP Basics1Document33 pagesLecture 2 - LP Basics1TarekYehiaNo ratings yet
- Fundamental Knowledge of Machine Learning: Abstract This Chapter Introduces The Basic Concepts and Methods of MachineDocument14 pagesFundamental Knowledge of Machine Learning: Abstract This Chapter Introduces The Basic Concepts and Methods of MachineJasmine TuasonNo ratings yet
- Lec. 03 - An Introduction To Support Vector Machines - Giorgio Valentini U. MilanoDocument42 pagesLec. 03 - An Introduction To Support Vector Machines - Giorgio Valentini U. MilanoAlejandro VasquezNo ratings yet
- Lecture07 SlidesDocument42 pagesLecture07 SlidesYunyang LiNo ratings yet
- Theory of Errors Chapter 9 391668376849522Document7 pagesTheory of Errors Chapter 9 391668376849522Umar BashirNo ratings yet
- Restricted Boltzmann Machines For Collaborative FilteringDocument8 pagesRestricted Boltzmann Machines For Collaborative FilteringLordRoyNo ratings yet
- Lecture Notes SVMDocument4 pagesLecture Notes SVMLilia XaNo ratings yet
- Lecture Notes SVMDocument4 pagesLecture Notes SVMSreeprada VNo ratings yet
- 3 DeltaRule PDFDocument10 pages3 DeltaRule PDFEs ENo ratings yet
- DNN - M2 - Deep Feedforward NN 23decDocument97 pagesDNN - M2 - Deep Feedforward NN 23decManju Prasad NNo ratings yet
- Introduction To Matlab Tutorial 11Document37 pagesIntroduction To Matlab Tutorial 11Syarif HidayatNo ratings yet
- COMP 4211 - Machine LearningDocument19 pagesCOMP 4211 - Machine LearningLinh TaNo ratings yet
- A Bounded Operator Approach To Technical Indicators Without LagDocument10 pagesA Bounded Operator Approach To Technical Indicators Without Laganil singhNo ratings yet
- Sequential Minimal Optimization: A Fast Algorithm For Training Support Vector MachinesDocument21 pagesSequential Minimal Optimization: A Fast Algorithm For Training Support Vector MachinesLovey SaxenaNo ratings yet
- Unit - 1d ORDocument22 pagesUnit - 1d ORMedandrao. Kavya SreeNo ratings yet
- Learning 2Document104 pagesLearning 2Noel Roy DenjaNo ratings yet
- Machine Learning 10-701 Final Exam May 5, 2015: Obvious Exceptions For Pacemakers and Hearing AidsDocument17 pagesMachine Learning 10-701 Final Exam May 5, 2015: Obvious Exceptions For Pacemakers and Hearing AidsNithinNo ratings yet
- Flexible Regression - Lecture 6: Marnie Mclean Room 344 Mathematics and Statistics BuildingDocument27 pagesFlexible Regression - Lecture 6: Marnie Mclean Room 344 Mathematics and Statistics BuildingSammy 123No ratings yet
- Computing Project: Numerical Solver For The 2D-Channel-Flow in Vorticity-Streamfunction FormulationDocument18 pagesComputing Project: Numerical Solver For The 2D-Channel-Flow in Vorticity-Streamfunction FormulationHappy SinghNo ratings yet
- Formula Notes Industrial Engin 891686837008983Document30 pagesFormula Notes Industrial Engin 891686837008983Somu SinghNo ratings yet
- A Convenient Approach For Penalty Parameter Selection in Robust Lasso RegressionDocument12 pagesA Convenient Approach For Penalty Parameter Selection in Robust Lasso Regressionasfar as-salafiyNo ratings yet
- M7-Support Vector MechineDocument24 pagesM7-Support Vector MechineSupriyadi Ageng ParjoyonoNo ratings yet
- Support Vector Machines (SVMS) : Cs479/679 Pattern Recognition Dr. George BebisDocument37 pagesSupport Vector Machines (SVMS) : Cs479/679 Pattern Recognition Dr. George BebisFif PlayerNo ratings yet
- Linear Models (Unit II) Chapter III 1Document24 pagesLinear Models (Unit II) Chapter III 1AnilNo ratings yet
- Simon Chapter 3Document12 pagesSimon Chapter 3shreyas srNo ratings yet
- Chapter 4Document10 pagesChapter 4Emanuel DiegoNo ratings yet
- Appunti MLDocument10 pagesAppunti MLvincentNo ratings yet
- Lec 3Document7 pagesLec 3stathiss11No ratings yet
- Lecture 14 - Logistic and Softmax Regression - PlainDocument12 pagesLecture 14 - Logistic and Softmax Regression - PlainRajachandra VoodigaNo ratings yet
- 1.1. Linear Models - Scikit-Learn 1.4.2 DocumentationDocument17 pages1.1. Linear Models - Scikit-Learn 1.4.2 DocumentationBhukya PramodNo ratings yet
- Wave Optics Class - 3 (Notes)Document18 pagesWave Optics Class - 3 (Notes)Krishna GuptaNo ratings yet
- 05 1 Optimization Methods NDPDocument85 pages05 1 Optimization Methods NDPSebastian LorcaNo ratings yet
- Digital Video: Progressive Scanning: One Full Frame Every 1/30th of A SecondDocument12 pagesDigital Video: Progressive Scanning: One Full Frame Every 1/30th of A Secondsandipprmar007No ratings yet
- Envelope TheoremDocument10 pagesEnvelope Theoremehsan rashidiNo ratings yet
- 10 SVMDocument23 pages10 SVMAurobindo SarkarNo ratings yet
- Linear Regression and Classification: Lectures 3-4Document41 pagesLinear Regression and Classification: Lectures 3-4ValNo ratings yet
- Support Vector Machines For Classification and RegressionDocument8 pagesSupport Vector Machines For Classification and RegressionYiwei ChenNo ratings yet
- DS NN 03 RNNDocument259 pagesDS NN 03 RNNAllice BoneteNo ratings yet
- An Improved Evolutionary Programming Algorithm For Fuzzy Programming Problems and Its ApplicationDocument4 pagesAn Improved Evolutionary Programming Algorithm For Fuzzy Programming Problems and Its ApplicationIzz DanialNo ratings yet
- Real-Time Symbolic Dynamic Programming For Hybrid MDPS: Luis G. R. Vianna Leliane N. de Barros Scott SannerDocument7 pagesReal-Time Symbolic Dynamic Programming For Hybrid MDPS: Luis G. R. Vianna Leliane N. de Barros Scott SannerPopon KangpenkaeNo ratings yet
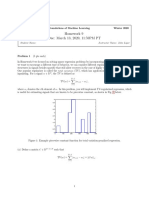
- Homework 9 Due: March 13, 2020, 11:59PM PTDocument2 pagesHomework 9 Due: March 13, 2020, 11:59PM PTPrateek VasudevNo ratings yet
- DCBlocker AlgorithmsDocument3 pagesDCBlocker AlgorithmsculyunNo ratings yet
- 19 Backpropagation4Document56 pages19 Backpropagation4Mahyar MohammadyNo ratings yet
- Econometrics CheatsheetDocument3 pagesEconometrics Cheatsheetf/z BENRABOUHNo ratings yet
- Lecture01d Cost FunctionsDocument8 pagesLecture01d Cost FunctionsUasdafNo ratings yet
- AssetAlloc and RiskManagementDocument16 pagesAssetAlloc and RiskManagementNeel KanakNo ratings yet
- Tutorial4 SVMDocument8 pagesTutorial4 SVMMark NamNo ratings yet
- Optimization: Machine Learning Course - CS-433Document23 pagesOptimization: Machine Learning Course - CS-433Diego Iriarte SainzNo ratings yet
- Support Vector Machine Classification Algorithm and Its ApplicationDocument8 pagesSupport Vector Machine Classification Algorithm and Its Application0191720003 ELIAS ANTONIO BELLO LEON ESTUDIANTE ACTIVONo ratings yet
- Section 9 Limited Dependent VariablesDocument17 pagesSection 9 Limited Dependent VariablesJose Bailon ChavarriNo ratings yet
- Lec 02 Computation GraphsDocument64 pagesLec 02 Computation GraphsMr. CoffeeNo ratings yet
- Insurance Analytics: Prof. Julien TrufinDocument21 pagesInsurance Analytics: Prof. Julien Trufindavid AbotsitseNo ratings yet
- Ebook A Short History of AIDocument9 pagesEbook A Short History of AIEllachgar MinaNo ratings yet
- Chapter 10-Frequency ResponseDocument67 pagesChapter 10-Frequency Responseعمر الفهدNo ratings yet
- Potato Leaf Disease Detection.-Test1Document8 pagesPotato Leaf Disease Detection.-Test1wrognNo ratings yet
- 12 State Space Analysis of Control SystemsDocument10 pages12 State Space Analysis of Control Systemsvidya_sagar826No ratings yet
- Introduction To Stages of AIDocument9 pagesIntroduction To Stages of AIMarkapuri Santhoash kumarNo ratings yet
- Hand Sign Language Translator For Speech ImpairedDocument4 pagesHand Sign Language Translator For Speech ImpairedInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- CCS 4102 Machine Learning Examinations-August 2020Document2 pagesCCS 4102 Machine Learning Examinations-August 2020Kefa MwitaNo ratings yet
- Ex 4Document15 pagesEx 4api-322416213No ratings yet
- International Journal of Chaos, Control, Modelling and Simulation (IJCCMS)Document3 pagesInternational Journal of Chaos, Control, Modelling and Simulation (IJCCMS)ijccmsNo ratings yet
- Speech RecognitionDocument27 pagesSpeech RecognitionLokendra Singh Shekhawat0% (1)
- MNIST Based Handwritten Digits RecognitionDocument5 pagesMNIST Based Handwritten Digits RecognitionraznahidNo ratings yet
- Tutorial On DNN 1 of 9 Background of DNNsDocument65 pagesTutorial On DNN 1 of 9 Background of DNNsAbdullah Al ImranNo ratings yet
- 2017 Machine Learning Summary v4 PDFDocument41 pages2017 Machine Learning Summary v4 PDFPaula GituNo ratings yet
- 2E1262 Nonlinear Control: Lyapunov-Based Control Design Methods Exact Feedback LinearizationDocument27 pages2E1262 Nonlinear Control: Lyapunov-Based Control Design Methods Exact Feedback LinearizationMutaz Ryalat100% (1)
- PS NN 2Document3 pagesPS NN 2Tapas KumarNo ratings yet
- 【DA】Time Series Data Augmentation for Deep Learning A SurveyDocument7 pages【DA】Time Series Data Augmentation for Deep Learning A SurveyJiancheng ZhangNo ratings yet
- Tut Week 5 QDocument9 pagesTut Week 5 QHon Yao Zhi MD30No ratings yet
- Machine Learning Toolkit User Manual PDFDocument7 pagesMachine Learning Toolkit User Manual PDFAngel of warNo ratings yet
- Data Mining Pertemuan 6Document28 pagesData Mining Pertemuan 6musim.jengkolNo ratings yet
- Hornoiu Lec III PragmaticaDocument59 pagesHornoiu Lec III PragmaticaAnamaria ManeaNo ratings yet
- (IJIT-V7I2P1) :nandita Bharambe, Pooja Barhate, Prachi DhannawatDocument3 pages(IJIT-V7I2P1) :nandita Bharambe, Pooja Barhate, Prachi DhannawatIJITJournalsNo ratings yet
- Reinforcement Learning With MATLAB: Understanding Training and DeploymentDocument39 pagesReinforcement Learning With MATLAB: Understanding Training and DeploymentGheorgheNo ratings yet
- 00703055Document5 pages00703055Paolita MicanNo ratings yet
- Fashion Recommendation System Reflecting Individuals Preferred StyleDocument2 pagesFashion Recommendation System Reflecting Individuals Preferred StyleMES LibraryNo ratings yet
- INT404 Artificial Intelligence: Lecture ZeroDocument28 pagesINT404 Artificial Intelligence: Lecture ZeroAmit SevenNo ratings yet
- Machine Learning LectureDocument332 pagesMachine Learning LectureDona DavakNo ratings yet
- Introduction To Advanced Control Systems: Topic 4Document18 pagesIntroduction To Advanced Control Systems: Topic 4Vedant .ChavanNo ratings yet
- Data Integrity Constraints-Lab-2 NotesDocument20 pagesData Integrity Constraints-Lab-2 Noteschauhansumi143No ratings yet
- Smart Cities: Moving Beyond Urban Cybernetics To Tackle Wicked ProblemsDocument14 pagesSmart Cities: Moving Beyond Urban Cybernetics To Tackle Wicked ProblemsShweta NandaNo ratings yet
- Assignment 3 - Research Report - Stephanie NgoeiDocument14 pagesAssignment 3 - Research Report - Stephanie NgoeiStephanie NgoeiNo ratings yet