You might also like
- High Speed Digital Design: Design of High Speed Interconnects and SignalingFrom EverandHigh Speed Digital Design: Design of High Speed Interconnects and SignalingNo ratings yet
- Channel Estimation For IEEE802.15.11Document12 pagesChannel Estimation For IEEE802.15.11nelsitotovarNo ratings yet
- Design for Testability, Debug and Reliability: Next Generation Measures Using Formal TechniquesFrom EverandDesign for Testability, Debug and Reliability: Next Generation Measures Using Formal TechniquesNo ratings yet
- Measurement Process of MOSFET Device Parameters WiDocument12 pagesMeasurement Process of MOSFET Device Parameters WinrckswangNo ratings yet
- Research On Anti-Interference of PLC: Procedia EngineeringDocument5 pagesResearch On Anti-Interference of PLC: Procedia EngineeringPABLO MAURONo ratings yet
- Genetic Algorithm2Document7 pagesGenetic Algorithm2Vaishnavi B VNo ratings yet
- Machine Translation Using Natural Language ProcessDocument6 pagesMachine Translation Using Natural Language ProcessFidelzy MorenoNo ratings yet
- Theory For Different Modulation PDFDocument8 pagesTheory For Different Modulation PDFKartik KulkarniNo ratings yet
- Tstat QoSIPDocument15 pagesTstat QoSIPLucivanio SantanaNo ratings yet
- Recurrent Nested Model For Sequence Generation: Wenhao Jiang, Lin Ma, Wei LuDocument8 pagesRecurrent Nested Model For Sequence Generation: Wenhao Jiang, Lin Ma, Wei LuAdmissionofficer kbgNo ratings yet
- Research On The SCADA System Constructing MethodolDocument6 pagesResearch On The SCADA System Constructing Methodoldarshan bsNo ratings yet
- B Tech Project ThesisDocument7 pagesB Tech Project Thesisczbsbgxff100% (2)
- Phase 2-FirstDocument22 pagesPhase 2-Firstgunjan26dNo ratings yet
- A Cluster Tree Method For Text Categorization - 2011 - Procedia EngineeringDocument6 pagesA Cluster Tree Method For Text Categorization - 2011 - Procedia EngineeringSwarnalathaNo ratings yet
- Rateless Codes ThesisDocument5 pagesRateless Codes Thesisafbtfukel100% (1)
- Design of A High Speed Serializer, Timing Analysis and Optimization in TSMC 28nm Process TechnologyDocument6 pagesDesign of A High Speed Serializer, Timing Analysis and Optimization in TSMC 28nm Process TechnologyEditor IJRITCCNo ratings yet
- High Speed RNS-To-Binary Converter DesignDocument6 pagesHigh Speed RNS-To-Binary Converter DesignAugus AngelNo ratings yet
- Ieee Research Papers On Image ProcessingDocument6 pagesIeee Research Papers On Image Processingaflbojhoa100% (1)
- Fully-Additive Printed Electronics - Transistor Model, Process Variation and Fundamental Circuit DesignsDocument9 pagesFully-Additive Printed Electronics - Transistor Model, Process Variation and Fundamental Circuit Designskamrul.malNo ratings yet
- Datacenter Connectivity TechnologiesDocument760 pagesDatacenter Connectivity TechnologiesCristianoVelosodeQueirozNo ratings yet
- The Design of The Embedded WEB Server Based On ENC28J60: Procedia EngineeringDocument5 pagesThe Design of The Embedded WEB Server Based On ENC28J60: Procedia EngineeringBRIGHT TZZZY CHINGWENANo ratings yet
- Thesis Sample Electronics EngineeringDocument8 pagesThesis Sample Electronics Engineeringgbwav8m4100% (2)
- Wavepipelined InterconnectsDocument5 pagesWavepipelined InterconnectsbibincmNo ratings yet
- Hardware and Software System-Level Simulator For Wireless Sensor NetworksDocument5 pagesHardware and Software System-Level Simulator For Wireless Sensor NetworksPhướcĐiềuTrầnNo ratings yet
- Image Compression Using Wavelet TransformDocument43 pagesImage Compression Using Wavelet Transformrachelpraisy_2451432No ratings yet
- Analytical Estimation of Signal Transition Activity From Word-Level StatisticsDocument16 pagesAnalytical Estimation of Signal Transition Activity From Word-Level StatisticsKumar N KrishnaMurthyNo ratings yet
- Traffic Engineering in Software-Defined NetworkingDocument12 pagesTraffic Engineering in Software-Defined NetworkingJamilCerezoNo ratings yet
- Passos 2018Document11 pagesPassos 2018Eduardo TarangoNo ratings yet
- Design and Implementation of Multifunctional VirtuDocument5 pagesDesign and Implementation of Multifunctional VirtuNazi JoonNo ratings yet
- M M !" #$ !" #$ M % %!#!"M M % %!#!"M &'' ( (') &'' ( (')Document35 pagesM M !" #$ !" #$ M % %!#!"M M % %!#!"M &'' ( (') &'' ( (')Kashif Aziz AwanNo ratings yet
- Simulation and Fault Detection For Aircraft IDG Sy-1Document5 pagesSimulation and Fault Detection For Aircraft IDG Sy-1rasoolNo ratings yet
- 1 s2.0 S2352711016300280 MainDocument8 pages1 s2.0 S2352711016300280 MainMikael CugnetNo ratings yet
- Comparative Analysis of Performance of Hub With Switch Local Area Network (LAN) Using Riverbed in University of Technology (Utech), JamaicaDocument23 pagesComparative Analysis of Performance of Hub With Switch Local Area Network (LAN) Using Riverbed in University of Technology (Utech), JamaicaOla Yemi UthmanNo ratings yet
- B.tech-I.T 7 & 8 Semester Course WorkDocument16 pagesB.tech-I.T 7 & 8 Semester Course WorkRocker byNo ratings yet
- 3D TCAD Simulation For CMOS NanoeletronicDocument337 pages3D TCAD Simulation For CMOS Nanoeletronicexfmln67% (3)
- 1742-6596 459 1 012012 PDFDocument5 pages1742-6596 459 1 012012 PDFAndri Adma WijayaNo ratings yet
- Implementing A Hidden Markov Model Speech RecognitDocument12 pagesImplementing A Hidden Markov Model Speech Recognitsamson wmariamNo ratings yet
- Design and Implementation of LPWA-Based Air Quality Monitoring SystemDocument18 pagesDesign and Implementation of LPWA-Based Air Quality Monitoring SystemHarsh mouryNo ratings yet
- 58 DS ProjectDocument22 pages58 DS Projectrr5221922No ratings yet
- Bachelor Thesis Informatik PDFDocument8 pagesBachelor Thesis Informatik PDFCynthia King100% (2)
- Simulation With Advanced Design System (ADS) : TNE088 RF ElectronicsDocument14 pagesSimulation With Advanced Design System (ADS) : TNE088 RF ElectronicsAnonymous LuK6R0No ratings yet
- Voltage ScalingDocument94 pagesVoltage Scalingvbharathi072100% (1)
- CT 320: Network and System Administration Fall 2014Document48 pagesCT 320: Network and System Administration Fall 2014Kushagra TiwaryNo ratings yet
- Thesis Turbo CodesDocument5 pagesThesis Turbo CodesjenniferreitherspringfieldNo ratings yet
- An Improved DV-Hop Localization Algorithm For Wire PDFDocument6 pagesAn Improved DV-Hop Localization Algorithm For Wire PDFM Chandan ShankarNo ratings yet
- FinalversionDocument5 pagesFinalversionAbhishek kumar PankajNo ratings yet
- Data Structures and Algorithms: Practical WorkbookDocument76 pagesData Structures and Algorithms: Practical Workbooksticky001100% (1)
- CT 320: Network and System Administration Fall 2014Document48 pagesCT 320: Network and System Administration Fall 2014Kushagra TiwaryNo ratings yet
- Analyzing Network CodingDocument9 pagesAnalyzing Network CodingHarsh KotakNo ratings yet
- Ternary Logic DocumentationDocument44 pagesTernary Logic Documentationanitha mettupalliNo ratings yet
- Electronics Engineering Thesis SampleDocument7 pagesElectronics Engineering Thesis Sampleerinperezphoenix100% (2)
- Syllabus 471c Wireless Communications LaboratoryDocument6 pagesSyllabus 471c Wireless Communications Laboratorycount3r5tr1keNo ratings yet
- 5 A Study On Teaching Method of Control EngineeringDocument9 pages5 A Study On Teaching Method of Control EngineeringAzt RibNo ratings yet
- CNTFET-Based Ternary Logic Gates: Design and Analysis ApproachDocument22 pagesCNTFET-Based Ternary Logic Gates: Design and Analysis ApproachHemant SaraswatNo ratings yet
- 12201619001-Niladree Pal-41 (DIP)Document12 pages12201619001-Niladree Pal-41 (DIP)NILADREE PAULNo ratings yet
- Multi-Functional Electronics Calculator ReportDocument49 pagesMulti-Functional Electronics Calculator Reportguddu kambleNo ratings yet
- Ac 2012-3977: Applications of Arduino Microcontroller in Student Projects in A Community CollegeDocument7 pagesAc 2012-3977: Applications of Arduino Microcontroller in Student Projects in A Community CollegeRic Chris DeeNo ratings yet
- Earthquake Simulations of Large Scale Structures Using Opensees Software On Grid and High Performance Computing in IndiaDocument4 pagesEarthquake Simulations of Large Scale Structures Using Opensees Software On Grid and High Performance Computing in Indiasofiane9500No ratings yet
- Free Research Papers in Electrical EngineeringDocument5 pagesFree Research Papers in Electrical Engineeringluwahudujos3100% (1)
- Thesis Report On AodvDocument8 pagesThesis Report On Aodvaragunikd100% (2)
- Mnras183 089PDocument4 pagesMnras183 089PManikanta Sai KumarNo ratings yet
- HM Eu Green Consumption PledgeDocument3 pagesHM Eu Green Consumption PledgeManikanta Sai KumarNo ratings yet
- Mnras183 089PDocument4 pagesMnras183 089PManikanta Sai KumarNo ratings yet
- North To South Laurel Park & Ride: 89M Bus Time Schedule & Line MapDocument7 pagesNorth To South Laurel Park & Ride: 89M Bus Time Schedule & Line MapManikanta Sai KumarNo ratings yet
- FY 2021 American Rescue Plan Act (H8F) : Funding For Health CentersDocument18 pagesFY 2021 American Rescue Plan Act (H8F) : Funding For Health CentersManikanta Sai KumarNo ratings yet
- Boeing 737-89P SP-LWA 12-19Document3 pagesBoeing 737-89P SP-LWA 12-19Manikanta Sai KumarNo ratings yet
- Model 89: 3/4" Rectangular Multiturn Cermet Trimming PotentiometerDocument6 pagesModel 89: 3/4" Rectangular Multiturn Cermet Trimming PotentiometerManikanta Sai KumarNo ratings yet
- Mnras183 089PDocument4 pagesMnras183 089PManikanta Sai KumarNo ratings yet
- Model 89: 3/4" Rectangular Multiturn Cermet Trimming PotentiometerDocument6 pagesModel 89: 3/4" Rectangular Multiturn Cermet Trimming PotentiometerManikanta Sai KumarNo ratings yet
- FY 2021 American Rescue Plan Act (H8F) : Funding For Health CentersDocument18 pagesFY 2021 American Rescue Plan Act (H8F) : Funding For Health CentersManikanta Sai KumarNo ratings yet
- The Total Package: ClassDocument2 pagesThe Total Package: ClassManikanta Sai KumarNo ratings yet
- E Program Files An ConnectManager SSIS TDS PDF Enviroline 378 Eng Usa LTR 20150205Document4 pagesE Program Files An ConnectManager SSIS TDS PDF Enviroline 378 Eng Usa LTR 20150205Manikanta Sai KumarNo ratings yet
- Boeing 737-89P SP-LWA 12-19Document3 pagesBoeing 737-89P SP-LWA 12-19Manikanta Sai KumarNo ratings yet
- Natural Resources Conservation Service Conservation Practice StandardDocument6 pagesNatural Resources Conservation Service Conservation Practice StandardManikanta Sai KumarNo ratings yet
- Fiber Optic Radiation Thermometer: Ir-Fa SeriesDocument6 pagesFiber Optic Radiation Thermometer: Ir-Fa SeriesManikanta Sai KumarNo ratings yet
- HM Eu Green Consumption PledgeDocument3 pagesHM Eu Green Consumption PledgeManikanta Sai KumarNo ratings yet
- Form No. 34F: (See Rule 44G)Document2 pagesForm No. 34F: (See Rule 44G)Manikanta Sai KumarNo ratings yet
- Template Form - SAT - CN8 - Review - DC1308 - PDF 39854695Document17 pagesTemplate Form - SAT - CN8 - Review - DC1308 - PDF 39854695Manikanta Sai KumarNo ratings yet
- Diamond Coring/ Hole Cutting: COSHH Essentials in Construction: Silica Engineering and RPEDocument4 pagesDiamond Coring/ Hole Cutting: COSHH Essentials in Construction: Silica Engineering and RPEManikanta Sai KumarNo ratings yet
- Natural Resources Conservation Service Conservation Practice StandardDocument6 pagesNatural Resources Conservation Service Conservation Practice StandardManikanta Sai KumarNo ratings yet
- E Program Files An ConnectManager SSIS TDS PDF Enviroline 378 Eng Usa LTR 20150205Document4 pagesE Program Files An ConnectManager SSIS TDS PDF Enviroline 378 Eng Usa LTR 20150205Manikanta Sai KumarNo ratings yet
- Template Form - SAT - CN8 - Review - DC1308 - PDF 39854695Document17 pagesTemplate Form - SAT - CN8 - Review - DC1308 - PDF 39854695Manikanta Sai KumarNo ratings yet
- Fiber Optic Radiation Thermometer: Ir-Fa SeriesDocument6 pagesFiber Optic Radiation Thermometer: Ir-Fa SeriesManikanta Sai KumarNo ratings yet
- Csi SVF n8 Bn8 Data SheetDocument3 pagesCsi SVF n8 Bn8 Data SheetManikanta Sai KumarNo ratings yet
- SM6T Series: Rans ORBDocument5 pagesSM6T Series: Rans ORBАлексейNo ratings yet
- K0096 N99 Respirator Masks FinalDocument5 pagesK0096 N99 Respirator Masks FinalManikanta Sai KumarNo ratings yet
- Template Form - SAT - CN8 - Review - DC1308 - PDF 39854695Document17 pagesTemplate Form - SAT - CN8 - Review - DC1308 - PDF 39854695Manikanta Sai KumarNo ratings yet
- Csi SVF n8 Bn8 Data SheetDocument3 pagesCsi SVF n8 Bn8 Data SheetManikanta Sai KumarNo ratings yet
- K0096 N99 Respirator Masks FinalDocument5 pagesK0096 N99 Respirator Masks FinalManikanta Sai KumarNo ratings yet
- Particulate Respirators With Valve: N99 ProtectionDocument2 pagesParticulate Respirators With Valve: N99 ProtectionManikanta Sai KumarNo ratings yet
- Mark Scheme: Double Award Science BiologyDocument9 pagesMark Scheme: Double Award Science BiologyDaniel LoughreyNo ratings yet
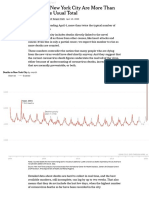
- Deaths in New York City Are More Than Double The Usual TotalDocument3 pagesDeaths in New York City Are More Than Double The Usual TotalRamón RuizNo ratings yet
- Pricelist LV Siemens 2019 PDFDocument96 pagesPricelist LV Siemens 2019 PDFBerlianiNo ratings yet
- Bubbles in Transformer Oil Dynamic Behavior Internal Discharge and Triggered Liquid BreakdownDocument9 pagesBubbles in Transformer Oil Dynamic Behavior Internal Discharge and Triggered Liquid BreakdownMuhammad Irfan NazhmiNo ratings yet
- FreeBSD HandbookDocument26 pagesFreeBSD Handbookhembeck119No ratings yet
- Ath9k and Ath9k - HTC DebuggingDocument4 pagesAth9k and Ath9k - HTC DebuggingHam Radio HSMMNo ratings yet
- SN Quick Reference 2018Document6 pagesSN Quick Reference 2018pinakin4uNo ratings yet
- Please Answer This Sincerely An TruthfullyDocument3 pagesPlease Answer This Sincerely An TruthfullyTiffany Tan100% (1)
- Asme B30.26 (2004)Document38 pagesAsme B30.26 (2004)Omar RamirezNo ratings yet
- 2023 The Eighth Dimension of Applied Behavior AnalysisDocument15 pages2023 The Eighth Dimension of Applied Behavior AnalysisFranciele PinheiroNo ratings yet
- VW 60330 2009 12 eDocument29 pagesVW 60330 2009 12 eAmir Borhanipour100% (1)
- Language - Introduction To The Integrated Language Arts CompetenciesDocument7 pagesLanguage - Introduction To The Integrated Language Arts CompetenciesHari Ng Sablay100% (1)
- Aeroacoustic Optimization of Wind Turbine Airfoils by Combining Thermographic and Acoustic Measurement DataDocument4 pagesAeroacoustic Optimization of Wind Turbine Airfoils by Combining Thermographic and Acoustic Measurement DatamoussaouiNo ratings yet
- BBC Learning English - 6 Minute English - Bitcoin - Digital Crypto-CurrencyDocument38 pagesBBC Learning English - 6 Minute English - Bitcoin - Digital Crypto-CurrencyMohamad GhafooryNo ratings yet
- EHS Audit - Review PaperDocument5 pagesEHS Audit - Review PaperYousef OlabiNo ratings yet
- SPC Company BrochureDocument22 pagesSPC Company BrochureDaivasigamaniNo ratings yet
- Shrutiand SmritiDocument9 pagesShrutiand SmritiAntara MitraNo ratings yet
- Roy B. Kantuna, MPRM, CESE: (For Midterm) (Instructor)Document8 pagesRoy B. Kantuna, MPRM, CESE: (For Midterm) (Instructor)Athena Mae DitchonNo ratings yet
- Can We Define Ecosystems - On The Confusion Between Definition and Description of Ecological ConceptsDocument15 pagesCan We Define Ecosystems - On The Confusion Between Definition and Description of Ecological ConceptsKionara SarabellaNo ratings yet
- IIRDocument2 pagesIIRJagan FaithNo ratings yet
- Retail ImageDocument76 pagesRetail ImageayushiNo ratings yet
- Pke - End Sleeves - Cembre (1) - AKBAR TRADING EST - SAUDI ARABIADocument2 pagesPke - End Sleeves - Cembre (1) - AKBAR TRADING EST - SAUDI ARABIAGIBUNo ratings yet
- 3286306Document5 pages3286306Sanjit OracleTrainingNo ratings yet
- Affidavit of Insurance ClaimsDocument2 pagesAffidavit of Insurance Claimsشزغتحزع ىطشفم لشجخبهNo ratings yet
- كتالوج وصفي للعملات الرومانية النادرة وغير المحررة من الفترة الأولى للعملات المعدنية الرومانية إلى انقراض الإمبراطورية تحت حكDocument570 pagesكتالوج وصفي للعملات الرومانية النادرة وغير المحررة من الفترة الأولى للعملات المعدنية الرومانية إلى انقراض الإمبراطورية تحت حكFayza MaghrabiNo ratings yet
- Dokumen - Tips Dm3220-Servicemanual PDFDocument62 pagesDokumen - Tips Dm3220-Servicemanual PDFwalidsayed1No ratings yet
- Mutant ChroniclesDocument3 pagesMutant ChroniclesZoth BernsteinNo ratings yet
- The Eminence in Shadow, Vol. 4Document255 pagesThe Eminence in Shadow, Vol. 4Ezra Salvame83% (6)
- The DAMA Guide To The Data Management Body of Knowledge - First EditionDocument430 pagesThe DAMA Guide To The Data Management Body of Knowledge - First Editionkakarotodesu100% (10)
- Data Science BooksDocument11 pagesData Science BooksAnalytics Insight100% (1)
- SQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLFrom EverandSQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLRating: 4.5 out of 5 stars4.5/5 (46)
- THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE: "THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE"From EverandTHE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE: "THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE"Rating: 3 out of 5 stars3/5 (1)
- Business Intelligence Strategy and Big Data Analytics: A General Management PerspectiveFrom EverandBusiness Intelligence Strategy and Big Data Analytics: A General Management PerspectiveRating: 5 out of 5 stars5/5 (5)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- Starting Database Administration: Oracle DBAFrom EverandStarting Database Administration: Oracle DBARating: 3 out of 5 stars3/5 (2)
- Dark Data: Why What You Don’t Know MattersFrom EverandDark Data: Why What You Don’t Know MattersRating: 4.5 out of 5 stars4.5/5 (3)
- ITIL 4: Digital and IT strategy: Reference and study guideFrom EverandITIL 4: Digital and IT strategy: Reference and study guideRating: 5 out of 5 stars5/5 (1)
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleFrom EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleRating: 4 out of 5 stars4/5 (16)
- IBM DB2 Administration Guide: Installation, Upgrade and Configuration of IBM DB2 on RHEL 8, Windows 10 and IBM Cloud (English Edition)From EverandIBM DB2 Administration Guide: Installation, Upgrade and Configuration of IBM DB2 on RHEL 8, Windows 10 and IBM Cloud (English Edition)No ratings yet
- Joe Celko's SQL for Smarties: Advanced SQL ProgrammingFrom EverandJoe Celko's SQL for Smarties: Advanced SQL ProgrammingRating: 3 out of 5 stars3/5 (1)
- Fusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureFrom EverandFusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureNo ratings yet
- Cloud Computing Playbook: 10 In 1 Practical Cloud Design With Azure, Aws And TerraformFrom EverandCloud Computing Playbook: 10 In 1 Practical Cloud Design With Azure, Aws And TerraformNo ratings yet
- COBOL Basic Training Using VSAM, IMS and DB2From EverandCOBOL Basic Training Using VSAM, IMS and DB2Rating: 5 out of 5 stars5/5 (2)
- Mastering Amazon Relational Database Service for MySQL: Building and configuring MySQL instances (English Edition)From EverandMastering Amazon Relational Database Service for MySQL: Building and configuring MySQL instances (English Edition)No ratings yet