You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Zenith 913 Manual Book PDFDocument190 pagesZenith 913 Manual Book PDFArvin Bhurtun71% (7)
- Site Diary TemplateDocument2 pagesSite Diary TemplatePhumla MaSompisi Mphemba100% (1)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Assignment No. 3 - Eng Maj 11Document4 pagesAssignment No. 3 - Eng Maj 11Mark GutierrezNo ratings yet
- Schematic of Experimental Span of JSC "STC FGC UES" For Testing of Vibration Dampers On Wire EfficiencyDocument5 pagesSchematic of Experimental Span of JSC "STC FGC UES" For Testing of Vibration Dampers On Wire EfficiencyStevepallmerNo ratings yet
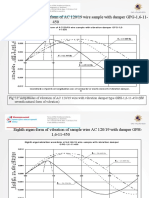
- Seventh Natural Waveform of AC 120/19 Wire Sample With Damper GPG-1,6-11-450Document5 pagesSeventh Natural Waveform of AC 120/19 Wire Sample With Damper GPG-1,6-11-450StevepallmerNo ratings yet
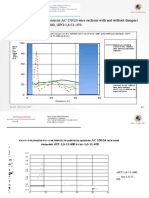
- Maximum Bending Stresses in AC 150/24 Wire Sections With and Without Dampers HVT-1,6-11-800, GPG-1,6-11-450Document5 pagesMaximum Bending Stresses in AC 150/24 Wire Sections With and Without Dampers HVT-1,6-11-800, GPG-1,6-11-450StevepallmerNo ratings yet
- Clase6 2014-7 PDFDocument1 pageClase6 2014-7 PDFStevepallmerNo ratings yet
- Thirteenth Proper Form of Vibration of The Sample Wire AC 120/19 With Dampener GPH-1,6-11-450Document5 pagesThirteenth Proper Form of Vibration of The Sample Wire AC 120/19 With Dampener GPH-1,6-11-450StevepallmerNo ratings yet
- Clase6 2014-5 PDFDocument1 pageClase6 2014-5 PDFStevepallmerNo ratings yet
- Fig. 5. Sample Selection of Random Action.: Z. Xiang, Et AlDocument1 pageFig. 5. Sample Selection of Random Action.: Z. Xiang, Et AlStevepallmerNo ratings yet
- Mediators: The Scientific World JournalDocument1 pageMediators: The Scientific World JournalStevepallmerNo ratings yet
- 10 PDFDocument1 page10 PDFStevepallmerNo ratings yet
- BF 02129047Document14 pagesBF 02129047StevepallmerNo ratings yet
- View PDFDocument135 pagesView PDFStevepallmerNo ratings yet
- 6 PDFDocument1 page6 PDFStevepallmerNo ratings yet
- Introduction and Modeling of Mechanical Ventilation SystemDocument1 pageIntroduction and Modeling of Mechanical Ventilation SystemStevepallmerNo ratings yet
- Tube Lung: 3. Experimental and Simulation StudyDocument1 pageTube Lung: 3. Experimental and Simulation StudyStevepallmerNo ratings yet
- Section 2.2.4: 5. ConclusionsDocument1 pageSection 2.2.4: 5. ConclusionsStevepallmerNo ratings yet
- 3.4. Analysis and Discussions. The Curve and Fitted Curve ofDocument1 page3.4. Analysis and Discussions. The Curve and Fitted Curve ofStevepallmerNo ratings yet
- Influence On Air Pressure Dynamic Characteristics: Figure 5: Respiratory Resistance of The SystemDocument1 pageInfluence On Air Pressure Dynamic Characteristics: Figure 5: Respiratory Resistance of The SystemStevepallmerNo ratings yet
- Research Article: Pressure Dynamic Characteristics of Pressure Controlled Ventilation System of A Lung SimulatorDocument1 pageResearch Article: Pressure Dynamic Characteristics of Pressure Controlled Ventilation System of A Lung SimulatorStevepallmerNo ratings yet
- 10 PDFDocument1 page10 PDFStevepallmerNo ratings yet
- Computational and Mathematical Methods in Medicine 9Document1 pageComputational and Mathematical Methods in Medicine 9StevepallmerNo ratings yet
- Determining KPIs To Measure Strategy Success by Arundhati BanerjeeDocument10 pagesDetermining KPIs To Measure Strategy Success by Arundhati BanerjeeArundhati BanerjeeNo ratings yet
- Dzone Refcard 347 Oauth Patterns Anti Patterns 202Document6 pagesDzone Refcard 347 Oauth Patterns Anti Patterns 202Brosoa LoquaNo ratings yet
- Syllabus Electrical Machines Subject Code: Ele-405 L T P: 2 1 0 Credits: 03Document3 pagesSyllabus Electrical Machines Subject Code: Ele-405 L T P: 2 1 0 Credits: 03Nitin PalNo ratings yet
- Dometic SMXHT ManualDocument2 pagesDometic SMXHT ManualAndri MorenoNo ratings yet
- Juniper Netscreen ISG Series DatasheetDocument12 pagesJuniper Netscreen ISG Series Datasheetbh.youssefNo ratings yet
- WFT101353 Weatherford Valves - CatalogoDocument13 pagesWFT101353 Weatherford Valves - Catalogoandres peraltaNo ratings yet
- Pronunciation NEWDocument7 pagesPronunciation NEWTrần Minh ThànhNo ratings yet
- Die Design FeaturesDocument46 pagesDie Design FeaturesMohamed Abdel FattahNo ratings yet
- Strategic Mine Planning-1Document7 pagesStrategic Mine Planning-1Harristio AdamNo ratings yet
- Vertical Flame ArresterDocument5 pagesVertical Flame ArresterMustafa PardawalaNo ratings yet
- Mahindra Max 28items CSD PerDocument1 pageMahindra Max 28items CSD Perboobalan_shriNo ratings yet
- Tls Master Key WindowsDocument5 pagesTls Master Key Windowsiiokojx386No ratings yet
- ACCT421 Detailed Course Outline, Term 2 2019-20 (Prof Andrew Lee) PDFDocument7 pagesACCT421 Detailed Course Outline, Term 2 2019-20 (Prof Andrew Lee) PDFnixn135No ratings yet
- B-Lift 201 Pro ADocument2 pagesB-Lift 201 Pro AALINo ratings yet
- ACI Remote Leaf Fabric Discovery v1.0 PDFDocument24 pagesACI Remote Leaf Fabric Discovery v1.0 PDFdelplayNo ratings yet
- Setembro :outubroDocument4 pagesSetembro :outubroblackgotravelNo ratings yet
- Bionaire BT015 Mini Tower FanDocument2 pagesBionaire BT015 Mini Tower FanAmarNo ratings yet
- Sony HCD Az2d PDFDocument110 pagesSony HCD Az2d PDFPranil RathodNo ratings yet
- 1.1 Background of The StudyDocument18 pages1.1 Background of The StudyPrakash KhadkaNo ratings yet
- PrintUnit 2 ThroughputLogDocument2 pagesPrintUnit 2 ThroughputLogErick GómezNo ratings yet
- General Organic and Biological Chemistry 7th Edition by Stoker ISBN Solution ManualDocument22 pagesGeneral Organic and Biological Chemistry 7th Edition by Stoker ISBN Solution Manualkermit100% (28)
- Grade 10 MathDocument142 pagesGrade 10 MathNiel Marc TomasNo ratings yet
- Architectural 3D Modeling in Historical PDFDocument10 pagesArchitectural 3D Modeling in Historical PDFThoraya SajidNo ratings yet
- UPS-GER 60kVA 0.8Pf 380V50Hz STR Out380V50Hz RangeDocument22 pagesUPS-GER 60kVA 0.8Pf 380V50Hz STR Out380V50Hz Rangeines lichihebNo ratings yet
- BAR EXAMINATIONS APPLICATION PROCESS Supreme Court of The PhilippinesDocument1 pageBAR EXAMINATIONS APPLICATION PROCESS Supreme Court of The PhilippinesPrettyNo ratings yet
- Chap 6 Verification and ValidationDocument33 pagesChap 6 Verification and ValidationmigadNo ratings yet