You might also like
- Notes InformaticaDocument121 pagesNotes InformaticaVijay Lolla100% (3)
- Oracle Database Administration Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandOracle Database Administration Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesRating: 5 out of 5 stars5/5 (1)
- SSIS TutorialDocument33 pagesSSIS Tutorialildiko_91No ratings yet
- Scheme Samsung NT p29Document71 pagesScheme Samsung NT p29Ricardo Avidano100% (1)
- Learning Recovery Plan2Document8 pagesLearning Recovery Plan2Remelyn RodrigoNo ratings yet
- Rouge No DengonDocument2 pagesRouge No DengonNaylimar D Alvarez CNo ratings yet
- Tableau Integration With HadoopDocument11 pagesTableau Integration With HadoopsunitaNo ratings yet
- Data On Demand With Enterprise Guide: A Cheap and Easy Approach To Real-Time Database AccessDocument11 pagesData On Demand With Enterprise Guide: A Cheap and Easy Approach To Real-Time Database AccessChristian LegaultNo ratings yet
- SSIS SSRS 2008 TutorialDocument79 pagesSSIS SSRS 2008 TutorialTrurlScribdNo ratings yet
- Tableau Interview Questions and AnswersDocument35 pagesTableau Interview Questions and AnswersparasharaNo ratings yet
- LP-VI Handwritten WriteupsDocument9 pagesLP-VI Handwritten Writeupskillua gojoNo ratings yet
- An Introduction To ClientDocument11 pagesAn Introduction To ClientVladislav KovalenkoNo ratings yet
- Power PivotDocument254 pagesPower PivotArif WahyudiNo ratings yet
- Tableau QuestionsDocument3 pagesTableau QuestionsMy online ShoppingNo ratings yet
- Java Database HandoutDocument29 pagesJava Database HandoutMark Arthur ParinaNo ratings yet
- ASP.NET Data Access TutorialDocument70 pagesASP.NET Data Access TutorialnageshNo ratings yet
- Tableau Products IntroductionDocument20 pagesTableau Products Introductionpalanisamy744No ratings yet
- SSIS TutorialDocument29 pagesSSIS TutorialAkram MalikNo ratings yet
- Esten Es Infoplc Net Controller Nx Nj Mysql SQL 2.0 Quick Start en 202002 Sw-103Document54 pagesEsten Es Infoplc Net Controller Nx Nj Mysql SQL 2.0 Quick Start en 202002 Sw-103kevin18jmsNo ratings yet
- What Is A Derived Table in Data Warehousing?Document3 pagesWhat Is A Derived Table in Data Warehousing?Abhilasha ModekarNo ratings yet
- 9.1. SQL Server Express: 9.1.1. Administrator AccessDocument15 pages9.1. SQL Server Express: 9.1.1. Administrator Accessapi-3797828No ratings yet
- Bi PracticalsDocument5 pagesBi Practicalsrucha8050No ratings yet
- Business PracticalsDocument54 pagesBusiness PracticalspameluftNo ratings yet
- Creating SSIS Packages: SQL Server 2005Document18 pagesCreating SSIS Packages: SQL Server 2005743,625,489,652 SubscribersNo ratings yet
- SSIS Tutorial: SQL Server 2005 Integration Services TutorialDocument28 pagesSSIS Tutorial: SQL Server 2005 Integration Services TutorialDawnGlennNo ratings yet
- SSIS 2008 TutorialDocument32 pagesSSIS 2008 TutorialPatricia SosaNo ratings yet
- Create Your First PowerPivot Workbook TutorialDocument20 pagesCreate Your First PowerPivot Workbook Tutorialfrancis07No ratings yet
- Designing and Developing RDLC Reports in ASPDocument6 pagesDesigning and Developing RDLC Reports in ASPDharmendra RaiNo ratings yet
- GUNADWDMDocument105 pagesGUNADWDMbekaketadvewNo ratings yet
- Aginity Netezza Workbench DocumentationDocument8 pagesAginity Netezza Workbench Documentationvanptl9361No ratings yet
- Import Excel data to SQL Server with SSIS Derived ColumnDocument9 pagesImport Excel data to SQL Server with SSIS Derived Columndash1022No ratings yet
- SQL Developer User GuideDocument90 pagesSQL Developer User Guidehani mundruNo ratings yet
- Types Of relations: One to one, one to many and many to many relationships in databasesDocument12 pagesTypes Of relations: One to one, one to many and many to many relationships in databasesNishanthNo ratings yet
- PLSQL Web ToolkitDocument31 pagesPLSQL Web ToolkitdvartaNo ratings yet
- Odbc and SQL: Creating A ChannelDocument9 pagesOdbc and SQL: Creating A ChannelKevin VillotaNo ratings yet
- SQL Developer User GuideDocument90 pagesSQL Developer User Guidevamshi4csNo ratings yet
- Talend Subramanyam B Feb 2022Document283 pagesTalend Subramanyam B Feb 2022Anonymous xMYE0TiNBcNo ratings yet
- SQL Server 2000 TutorialDocument46 pagesSQL Server 2000 TutorialAbdul Sattar KianiNo ratings yet
- SQL Server QuestionDocument16 pagesSQL Server QuestionDhiraj GautameNo ratings yet
- DAC Interview QuestionsDocument5 pagesDAC Interview QuestionsPoornima SrivenkateshNo ratings yet
- Excel to PeopleSoft Data Import UtilityDocument14 pagesExcel to PeopleSoft Data Import UtilityVeer PolavarapuNo ratings yet
- ETL Framework Methodology: Prepared by Michael Favero & Kenneth BlandDocument19 pagesETL Framework Methodology: Prepared by Michael Favero & Kenneth BlandsparadraNo ratings yet
- DB Connect ExtractionDocument16 pagesDB Connect Extractionyshrini50% (2)
- QW SQL Wizard: (January 4, 2010)Document13 pagesQW SQL Wizard: (January 4, 2010)kgskgmNo ratings yet
- Chapter 16: SQL Server Integration ServicesDocument32 pagesChapter 16: SQL Server Integration ServicesFrancisco ArrochaNo ratings yet
- ArchitectureDocument7 pagesArchitectureVu Duc TruongNo ratings yet
- Interbase vs. SQL ServerDocument7 pagesInterbase vs. SQL ServerteknograhaNo ratings yet
- Ecc To Hana by BodsDocument52 pagesEcc To Hana by BodsAdaikalam Alexander RayappaNo ratings yet
- BI Apps WarehouseDocument7 pagesBI Apps WarehouseRrguyyalaNo ratings yet
- SDLC of Data WarehoseDocument2 pagesSDLC of Data Warehosesaurav5600% (1)
- Informatica Interview QuestionsDocument5 pagesInformatica Interview QuestionsPreethaNo ratings yet
- Mis621 - Lap ReportDocument14 pagesMis621 - Lap ReportSajidMahmoodChoudhuryNo ratings yet
- Ba Createing Data Mart SQLDocument25 pagesBa Createing Data Mart SQLParasVashishtNo ratings yet
- SQL Joins in ReportDocument6 pagesSQL Joins in ReportSonalNo ratings yet
- How to Write a Bulk Emails Application in Vb.Net and Mysql: Step by Step Fully Working ProgramFrom EverandHow to Write a Bulk Emails Application in Vb.Net and Mysql: Step by Step Fully Working ProgramNo ratings yet
- Tableau Training Manual 9.0 Basic Version: This Via Tableau Training Manual Was Created for Both New and IntermediateFrom EverandTableau Training Manual 9.0 Basic Version: This Via Tableau Training Manual Was Created for Both New and IntermediateRating: 3 out of 5 stars3/5 (1)
- GETTING STARTED WITH SQL: Exercises with PhpMyAdmin and MySQLFrom EverandGETTING STARTED WITH SQL: Exercises with PhpMyAdmin and MySQLNo ratings yet
- How COVID-19-is-changing-consumer-behaviornow-and-foreverDocument6 pagesHow COVID-19-is-changing-consumer-behaviornow-and-forevermesay83No ratings yet
- COVID 19 Restrictions and Consumers Psychological Reactance Toward Offline Shopping Freedom RestorationDocument24 pagesCOVID 19 Restrictions and Consumers Psychological Reactance Toward Offline Shopping Freedom RestorationAhmad MqdadNo ratings yet
- 01 McKinsey & Company July 7 2020Document19 pages01 McKinsey & Company July 7 2020Gladwin Joseph100% (1)
- Online Shopping Factors That Affect Consumer Purchasing BehaviourDocument16 pagesOnline Shopping Factors That Affect Consumer Purchasing BehaviourAhmad MqdadNo ratings yet
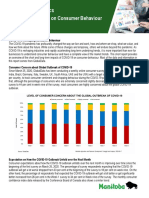
- Impact of COVID-19 On Consumer Behaviour: Manitoba AnalyticsDocument3 pagesImpact of COVID-19 On Consumer Behaviour: Manitoba AnalyticsAhmad MqdadNo ratings yet
- COVID-19 - Impact On Consumer Behavior Trends - AccentureDocument11 pagesCOVID-19 - Impact On Consumer Behavior Trends - AccentureAhmad MqdadNo ratings yet
- COVID-19 Generation: Conceptual Framework of Consumer Behavioral ShiftsDocument11 pagesCOVID-19 Generation: Conceptual Framework of Consumer Behavioral ShiftsMac John PierreNo ratings yet
- Change of Consumption Behaviours in The Pandemic of COVID-19: Examining Residents' Consumption Expenditure and Driving DeterminantsDocument15 pagesChange of Consumption Behaviours in The Pandemic of COVID-19: Examining Residents' Consumption Expenditure and Driving DeterminantsAhmad MqdadNo ratings yet
- Change of Consumption Behaviours in The Pandemic of COVID-19: Examining Residents' Consumption Expenditure and Driving DeterminantsDocument15 pagesChange of Consumption Behaviours in The Pandemic of COVID-19: Examining Residents' Consumption Expenditure and Driving DeterminantsAhmad MqdadNo ratings yet
- Impact of The COVID-19 Pandemic On Online Consumer Purchasing BehaviorDocument19 pagesImpact of The COVID-19 Pandemic On Online Consumer Purchasing BehaviorBình BìnhNo ratings yet
- HCI Individual Assignment Analysis of Priceline and True Lines Wear WebsitesDocument8 pagesHCI Individual Assignment Analysis of Priceline and True Lines Wear WebsitesAhmad MqdadNo ratings yet
- Change of Consumption Behaviours in The Pandemic of COVID-19: Examining Residents' Consumption Expenditure and Driving DeterminantsDocument15 pagesChange of Consumption Behaviours in The Pandemic of COVID-19: Examining Residents' Consumption Expenditure and Driving DeterminantsAhmad MqdadNo ratings yet
- COVID-19 Has Changed Consumer Behavior. What Does It Mean For The Future - University of Arizona NewsDocument5 pagesCOVID-19 Has Changed Consumer Behavior. What Does It Mean For The Future - University of Arizona NewsAhmad MqdadNo ratings yet
- Adventures of Sherlock Holmes, by A. Conan DoyleDocument194 pagesAdventures of Sherlock Holmes, by A. Conan DoyleAhmad MqdadNo ratings yet
- AhitofelAmir - Ahitofel - Amir - SQL at Main Amircohen87 - AhitofelAmir GitHubDocument25 pagesAhitofelAmir - Ahitofel - Amir - SQL at Main Amircohen87 - AhitofelAmir GitHubAhmad MqdadNo ratings yet
- Change of Consumption Behaviours in The Pandemic of COVID-19: Examining Residents' Consumption Expenditure and Driving DeterminantsDocument15 pagesChange of Consumption Behaviours in The Pandemic of COVID-19: Examining Residents' Consumption Expenditure and Driving DeterminantsAhmad MqdadNo ratings yet
- The Rover Boys in BusinessDocument163 pagesThe Rover Boys in BusinessAhmad MqdadNo ratings yet
- ERD FinalDocument1 pageERD FinalAhmad MqdadNo ratings yet
- Change of Consumption Behaviours in The Pandemic of COVID-19: Examining Residents' Consumption Expenditure and Driving DeterminantsDocument15 pagesChange of Consumption Behaviours in The Pandemic of COVID-19: Examining Residents' Consumption Expenditure and Driving DeterminantsAhmad MqdadNo ratings yet
- UNIT III Case Study 1Document4 pagesUNIT III Case Study 1Ahmad MqdadNo ratings yet
- Impact of The COVID-19 Pandemic On Online Consumer Purchasing BehaviorDocument19 pagesImpact of The COVID-19 Pandemic On Online Consumer Purchasing BehaviorBình BìnhNo ratings yet
- HCI Individual Assignment Analysis of Priceline and True Lines Wear WebsitesDocument8 pagesHCI Individual Assignment Analysis of Priceline and True Lines Wear WebsitesAhmad MqdadNo ratings yet
- Questionnaire About The Pressure To Hire Family Members in The Family Business ResultesDocument13 pagesQuestionnaire About The Pressure To Hire Family Members in The Family Business ResultesAhmad MqdadNo ratings yet
- Chapter 3 - Summary Business Essentials Chapter 3 - Summary Business EssentialsDocument8 pagesChapter 3 - Summary Business Essentials Chapter 3 - Summary Business EssentialsAhmad MqdadNo ratings yet
- Business Essentials: Entrepreneurship, New Ventures, and Business OwnershipDocument45 pagesBusiness Essentials: Entrepreneurship, New Ventures, and Business OwnershipAhmad MqdadNo ratings yet
- Business Essentials: Marketing Processes and Consumer BehaviorDocument49 pagesBusiness Essentials: Marketing Processes and Consumer BehaviorAhmad MqdadNo ratings yet
- Change of Consumption Behaviours in The Pandemic of COVID-19: Examining Residents' Consumption Expenditure and Driving DeterminantsDocument15 pagesChange of Consumption Behaviours in The Pandemic of COVID-19: Examining Residents' Consumption Expenditure and Driving DeterminantsAhmad MqdadNo ratings yet
- Business Essentials: Understanding Business Ethics and Social ResponsibilityDocument42 pagesBusiness Essentials: Understanding Business Ethics and Social ResponsibilityDee IsmailNo ratings yet
- Chapter 2 - Summary Business Essentials Chapter 2 - Summary Business EssentialsDocument11 pagesChapter 2 - Summary Business Essentials Chapter 2 - Summary Business EssentialsAhmad MqdadNo ratings yet
- Senguntha KshatriyaDocument34 pagesSenguntha Kshatriyabogar marabuNo ratings yet
- National Scholars Program 2005 Annual Report: A Growing Tradition of ExcellenceDocument24 pagesNational Scholars Program 2005 Annual Report: A Growing Tradition of ExcellencejamwilljamwillNo ratings yet
- Poultry Fool & FinalDocument42 pagesPoultry Fool & Finalaashikjayswal8No ratings yet
- 9 English Eng 2023 24Document4 pages9 English Eng 2023 24Vikas SinghNo ratings yet
- 3.5 Procedure For Gathering DataDocument1 page3.5 Procedure For Gathering DataJeremyGuiabNo ratings yet
- HR Generalist SyllabusDocument4 pagesHR Generalist Syllabusdugdugdugdugi100% (1)
- Organic Agriculture Gr11 Q2.Module5 LRDocument17 pagesOrganic Agriculture Gr11 Q2.Module5 LRJam Hamil AblaoNo ratings yet
- Carbohydrates ReviewerDocument2 pagesCarbohydrates ReviewerJazer AvellanozaNo ratings yet
- 07 Trumpet 2, 3Document3 pages07 Trumpet 2, 3Eneas Augusto100% (1)
- 2015-10-26 Plaintiff's Letter To Defendant Regarding Discovery (Flores V DOJ) (FOIA Lawsuit)Document25 pages2015-10-26 Plaintiff's Letter To Defendant Regarding Discovery (Flores V DOJ) (FOIA Lawsuit)Progress QueensNo ratings yet
- Parallel Worlds ChessDocument2 pagesParallel Worlds ChessRobert BonisoloNo ratings yet
- Encoder DecoderDocument6 pagesEncoder Decodermarkcelis1No ratings yet
- Aadhaar update form for Anjali SinghDocument4 pagesAadhaar update form for Anjali Singhrahul chaudharyNo ratings yet
- Beauty Paulor Management SystemDocument2 pagesBeauty Paulor Management SystemTheint Theint AungNo ratings yet
- X-Ray Artifacts: by DR Mangal S MahajanDocument12 pagesX-Ray Artifacts: by DR Mangal S MahajanTsega HagosNo ratings yet
- OBE-Syllabus Photography 2015Document8 pagesOBE-Syllabus Photography 2015Frederick Eboña100% (1)
- ?PMA 138,39,40,41LC Past Initials-1Document53 pages?PMA 138,39,40,41LC Past Initials-1Saqlain Ali Shah100% (1)
- Exam StructuralDocument1 pageExam StructuralJoyce DueroNo ratings yet
- Wps PrenhallDocument1 pageWps PrenhallsjchobheNo ratings yet
- P17P01 Ca019 17 An 101 1260 in DWG 191 - Tus Ins 233 FS 0194 - 0 PDFDocument7 pagesP17P01 Ca019 17 An 101 1260 in DWG 191 - Tus Ins 233 FS 0194 - 0 PDFrenzomcuevaNo ratings yet
- AP Microeconomics 2016 Free-Response QuestionsDocument4 pagesAP Microeconomics 2016 Free-Response QuestionsSHIN SeoYoungNo ratings yet
- Chapter 4: Assessing Listening Skills: Exercise 1: Match The Six Types of Listenning (1-6) To The Examples (A-F)Document4 pagesChapter 4: Assessing Listening Skills: Exercise 1: Match The Six Types of Listenning (1-6) To The Examples (A-F)Ánh Lã NgọcNo ratings yet
- Supervision Assigment 1Document18 pagesSupervision Assigment 1Wendimu Nigusie100% (3)
- Module 6Document2 pagesModule 6Carla Mae F. DaduralNo ratings yet
- Common Customer Gateway Product SheetDocument2 pagesCommon Customer Gateway Product SheetNYSE TechnologiesNo ratings yet
- Cost EstimationDocument4 pagesCost EstimationMuhammed Azhar P JNo ratings yet
- Fcra Act 2010 PDFDocument2 pagesFcra Act 2010 PDFKateNo ratings yet