You might also like
- Digital Modulations using MatlabFrom EverandDigital Modulations using MatlabRating: 4 out of 5 stars4/5 (6)
- Cuda 9 and BeyondDocument45 pagesCuda 9 and BeyondJapaneseNo ratings yet
- High-Performance D/A-Converters: Application to Digital TransceiversFrom EverandHigh-Performance D/A-Converters: Application to Digital TransceiversNo ratings yet
- Tesla V100 Performance GuideDocument23 pagesTesla V100 Performance GuideJhonattan CapoteNo ratings yet
- GPU Bootcamp SamharDocument96 pagesGPU Bootcamp SamharAman JainNo ratings yet
- Heroux App Perf On Multicores Mantevo Project SAND2008-1085P 020408Document21 pagesHeroux App Perf On Multicores Mantevo Project SAND2008-1085P 020408radaki-1No ratings yet
- Accelerating Matrix Multiplication With Block Sparse Format and NVIDIA Tensor Cores - NVIDIA Technical BlogDocument7 pagesAccelerating Matrix Multiplication With Block Sparse Format and NVIDIA Tensor Cores - NVIDIA Technical BlogShrey AgarwalNo ratings yet
- Trinity Price ListDocument12 pagesTrinity Price Listkirtiraj gehlotNo ratings yet
- PowerEdge MX IO Guide PDFDocument72 pagesPowerEdge MX IO Guide PDFmarvinreneNo ratings yet
- PowerEdge MX7000 Networking GuideDocument48 pagesPowerEdge MX7000 Networking GuidedanycuppariNo ratings yet
- PowerEdge MX IO GuideDocument72 pagesPowerEdge MX IO GuideThành TrungNo ratings yet
- dc7261 Scott Ruppert Tim Woodard Deep Learning With Quadro in WorkstationDocument11 pagesdc7261 Scott Ruppert Tim Woodard Deep Learning With Quadro in Workstationyuriikorolov15No ratings yet
- PowerEdge MX IO GuideDocument99 pagesPowerEdge MX IO GuideasakjiNo ratings yet
- NVIDIA GPU Computing - A Journey From PC Gaming To Deep LearningDocument91 pagesNVIDIA GPU Computing - A Journey From PC Gaming To Deep LearningAldo ChellaNo ratings yet
- Openacc Online Course: Lecture 1: Introduction To OpenaccDocument47 pagesOpenacc Online Course: Lecture 1: Introduction To OpenaccQuant_GeekNo ratings yet
- RTI Control Processor ComparisonDocument1 pageRTI Control Processor Comparisonblesson123No ratings yet
- PowerEdge MX IO GuideDocument80 pagesPowerEdge MX IO GuidedanycuppariNo ratings yet
- Stateful Pcap Replay With Aticara Over Wifi InterfaceDocument4 pagesStateful Pcap Replay With Aticara Over Wifi InterfaceNaveen ChandraNo ratings yet
- 4 1 MWagner GPU VoltaDocument36 pages4 1 MWagner GPU VoltaYAAKOV SOLOMONNo ratings yet
- MES - 23xxP DatasheetDocument5 pagesMES - 23xxP Datasheetantonije44No ratings yet
- BRKCRS 3143Document105 pagesBRKCRS 3143prakashrjsekarNo ratings yet
- Whats New in ElectronicsDocument8 pagesWhats New in Electronicsozcan44No ratings yet
- Parameter C2050 (Fermi) K10 (Kepler)Document2 pagesParameter C2050 (Fermi) K10 (Kepler)haseeb ahmadNo ratings yet
- HSPA To LTEDocument15 pagesHSPA To LTErashedsobujNo ratings yet
- HFR My5G One Page Summary-March, 2021Document1 pageHFR My5G One Page Summary-March, 2021Heny Pramita SiwiNo ratings yet
- Adva Micromux™: Support For Lower-Speed Clients Today With No Impact On Future ScalabilityDocument2 pagesAdva Micromux™: Support For Lower-Speed Clients Today With No Impact On Future ScalabilityCyprienLaleau100% (1)
- Talk 1 Satoshi MatsuokaDocument112 pagesTalk 1 Satoshi Matsuokasofia9909No ratings yet
- Symmetric Key Cryptography On Modern Graphics HardwareDocument17 pagesSymmetric Key Cryptography On Modern Graphics Hardwaremagimic196No ratings yet
- Mellanox Ethernet Switch BrochureDocument4 pagesMellanox Ethernet Switch BrochureTimucin DIKMENNo ratings yet
- Data Sheet: Technical FeaturesDocument6 pagesData Sheet: Technical FeaturesHuy DoanNo ratings yet
- MX10003 MX204Document43 pagesMX10003 MX204Mohit Mittal33% (3)
- Whats New in Electronics DesktopDocument7 pagesWhats New in Electronics DesktopSmenn SmennNo ratings yet
- Whats New in Electronics DesktopDocument7 pagesWhats New in Electronics Desktopgabriel davilaNo ratings yet
- Channel Estimation PDFDocument4 pagesChannel Estimation PDFHuy Nguyễn QuốcNo ratings yet
- Vlsi2022 C10-1Document31 pagesVlsi2022 C10-1himmel17No ratings yet
- Understanding 10G To 400G Ethernet Speeds Transceivers and Selecting The Correct Fiber Optic Connectivity v2 1Document23 pagesUnderstanding 10G To 400G Ethernet Speeds Transceivers and Selecting The Correct Fiber Optic Connectivity v2 1huanyong wangNo ratings yet
- Comparing Nvidia K40 and V100 GPUDocument2 pagesComparing Nvidia K40 and V100 GPUmemeNo ratings yet
- HC31 1.11 Huawei - Davinci.HengLiao v4.0 PDFDocument44 pagesHC31 1.11 Huawei - Davinci.HengLiao v4.0 PDFCynthia SmithNo ratings yet
- Tutorial On TI C6678Document65 pagesTutorial On TI C6678Shashwat DubeyNo ratings yet
- Fx3gc PLC User Manual 20191026Document2 pagesFx3gc PLC User Manual 20191026Karim NasriNo ratings yet
- MES - 3348 - 3348 DatasheetDocument4 pagesMES - 3348 - 3348 Datasheetantonije44No ratings yet
- Introduction To OpenACC Course 20161026 1550 1Document68 pagesIntroduction To OpenACC Course 20161026 1550 1Fabio GonçalvesNo ratings yet
- Fujitsu LifeBook LH530 Quanta FH1 Intel UMA Rev1A SchematicDocument37 pagesFujitsu LifeBook LH530 Quanta FH1 Intel UMA Rev1A SchematicAsep IndraNo ratings yet
- Huawei CloudEngine Series Data Center Switch PortfolioDocument1 pageHuawei CloudEngine Series Data Center Switch PortfolioZekariyas GirmaNo ratings yet
- Plateform: High-Bit Rate Coherent Transmission: Main EquipmentsDocument1 pagePlateform: High-Bit Rate Coherent Transmission: Main EquipmentsHernan BenitesNo ratings yet
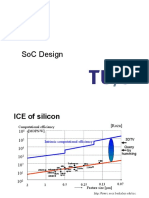
- SoCDesign PDFDocument42 pagesSoCDesign PDFNguyen Van ToanNo ratings yet
- Mehrpoo2019 PDFDocument5 pagesMehrpoo2019 PDFDigvijayNo ratings yet
- FPGA Vs DSP For Power ElectronicsDocument29 pagesFPGA Vs DSP For Power ElectronicsPepe FCNo ratings yet
- Trancated Multiplier PeprDocument5 pagesTrancated Multiplier PeprJagannath KbNo ratings yet
- 【HSE】2021 HSE Training - Product Professional - H3C ServerDocument38 pages【HSE】2021 HSE Training - Product Professional - H3C ServerAndre GermaineNo ratings yet
- MES23xx DatasheetDocument5 pagesMES23xx Datasheetantonije44No ratings yet
- Data Sheet: MES5448 Switches Are High Performance Devices WithDocument6 pagesData Sheet: MES5448 Switches Are High Performance Devices WithHuy DoanNo ratings yet
- CMOS 300 MSPS Quadrature Complete DDS AD9854: FeaturesDocument52 pagesCMOS 300 MSPS Quadrature Complete DDS AD9854: Featuresjigg1777No ratings yet
- An Energy-Efficient Cache Architecture For Chip-Multiprocessors Based On Non-Uniformity AccessesDocument4 pagesAn Energy-Efficient Cache Architecture For Chip-Multiprocessors Based On Non-Uniformity Accessesqwertyytrewq251931No ratings yet
- Platform NodeDocument5 pagesPlatform NodeCaraka TriNo ratings yet
- Apposite Technologies Product Comparison SheetDocument2 pagesApposite Technologies Product Comparison Sheetanon_380549038No ratings yet
- Innovative Line SensorDocument4 pagesInnovative Line SensorXavier Pacheco PaulinoNo ratings yet
- Datasheet: Thinking of Linking !Document7 pagesDatasheet: Thinking of Linking !jaeik changNo ratings yet
- MES 2324P 2348P Datasheet 4.0.10.1 enDocument5 pagesMES 2324P 2348P Datasheet 4.0.10.1 enHuy DoanNo ratings yet
- Ms-Sizing-Guide-Web-Gateway 7.4.2 AppliancesDocument1 pageMs-Sizing-Guide-Web-Gateway 7.4.2 AppliancesSerennia TsangNo ratings yet
- Special Cases:: - Unbounded Solution: - Multiple OptimalDocument38 pagesSpecial Cases:: - Unbounded Solution: - Multiple OptimalAffu ShaikNo ratings yet
- Binomial TheoremDocument9 pagesBinomial TheoremKrishnaNo ratings yet
- Ecr305 L7 SP 2017Document24 pagesEcr305 L7 SP 2017Shirazim MunirNo ratings yet
- How To Use The Hungarian Algorithm - 10 Steps (With Pictures)Document2 pagesHow To Use The Hungarian Algorithm - 10 Steps (With Pictures)AngelRibeiro10No ratings yet
- Neural NetworksDocument26 pagesNeural NetworksphreedomNo ratings yet
- Notebook OR 2015Document74 pagesNotebook OR 2015DonitaNo ratings yet
- Chapter 5. The Discrete Fourier Transform: Gao Xinbo School of E.E., Xidian UnivDocument53 pagesChapter 5. The Discrete Fourier Transform: Gao Xinbo School of E.E., Xidian Univஆனந்த் குமார்No ratings yet
- Data Analyis - PPT - 2Document18 pagesData Analyis - PPT - 2pppooNo ratings yet
- Convolution ExampleDocument10 pagesConvolution ExampleJuan Diego NiñoNo ratings yet
- 8 Assignment Problem PDFDocument30 pages8 Assignment Problem PDFchandel08No ratings yet
- Linear Programming Exercises Exercise 1. Given A Problem: Prove That Is An Extreme Optimal Solution of This ProblemDocument7 pagesLinear Programming Exercises Exercise 1. Given A Problem: Prove That Is An Extreme Optimal Solution of This ProblemHang PhamNo ratings yet
- MKL 2017 Developer Reference CDocument2,496 pagesMKL 2017 Developer Reference CQingZhen MaNo ratings yet
- Stochastic Gradient Descent: Ryan Tibshirani Convex Optimization 10-725Document22 pagesStochastic Gradient Descent: Ryan Tibshirani Convex Optimization 10-725jlmunozmezaNo ratings yet
- Secant MethodDocument24 pagesSecant Methodsoran najebNo ratings yet
- Mesh Free GRLIUDocument42 pagesMesh Free GRLIUSandeepNo ratings yet
- Learning Opportunity 1Document4 pagesLearning Opportunity 1Gabriel TambweNo ratings yet
- 3730007Document2 pages3730007Hardik JogranaNo ratings yet
- Transshipment Problem: Presented By: Shreeya Sharma Roll No: 21154 Hospital ManagementDocument16 pagesTransshipment Problem: Presented By: Shreeya Sharma Roll No: 21154 Hospital ManagementShreeya SharmaNo ratings yet
- Asm 2222222222Document5 pagesAsm 2222222222p5jp29697cNo ratings yet
- Tybms Regular Exams Operations Research Set 1Document6 pagesTybms Regular Exams Operations Research Set 1Surekha DebadwarNo ratings yet
- An Algorithm For Set Covering ProblemDocument9 pagesAn Algorithm For Set Covering ProblemdewyekhaNo ratings yet
- Practical Introduction To FEA and CFDDocument4 pagesPractical Introduction To FEA and CFDalagarg137691No ratings yet
- Answer-Sheet GEN MATHDocument5 pagesAnswer-Sheet GEN MATHJoesil Dianne SempronNo ratings yet
- Newton Raphson Method Example-2 F (X) 2x 3-2x-5Document3 pagesNewton Raphson Method Example-2 F (X) 2x 3-2x-5Rashid Abu abdoonNo ratings yet
- DeepLearning L1 IntroDocument92 pagesDeepLearning L1 IntrolafdaliNo ratings yet
- Feedback Control Systems (FCS) : Lecture-26 Routh-Herwitz Stability CriterionDocument19 pagesFeedback Control Systems (FCS) : Lecture-26 Routh-Herwitz Stability CriterionSARTHAK BAPATNo ratings yet
- Bharathi Education Trust G. Madegowda Institute of Technology (Gmit)Document10 pagesBharathi Education Trust G. Madegowda Institute of Technology (Gmit)harshithaNo ratings yet
- 09 Hybrid SystemsDocument43 pages09 Hybrid SystemsAnkit SoniNo ratings yet
- Neural Network and Fuzzy LogicDocument4 pagesNeural Network and Fuzzy LogicRashi SharmaNo ratings yet
- Angelo Algebra RecallDocument4 pagesAngelo Algebra RecallMelchor King Hilario EsquilloNo ratings yet