You might also like
- Final Examination SalcedoDocument8 pagesFinal Examination SalcedoGian Georgette SalcedoNo ratings yet
- Tugas StatistikDocument2 pagesTugas StatistikjangpikNo ratings yet
- Sta 404 - Test - Aug 2023Document3 pagesSta 404 - Test - Aug 2023Hakkkinen LewisNo ratings yet
- Spring 2014 Final SampleExamkey 25Q Version A - FinalDocument12 pagesSpring 2014 Final SampleExamkey 25Q Version A - Finalduy phamNo ratings yet
- Table 1: Model SummaryDocument2 pagesTable 1: Model Summaryankit rajNo ratings yet
- Statap Practicetest 27Document7 pagesStatap Practicetest 27Hoa Dinh NguyenNo ratings yet
- SLM Economics-Xi Part-Ii Multiple Choice QuestionsDocument46 pagesSLM Economics-Xi Part-Ii Multiple Choice QuestionsShivanshi BansalNo ratings yet
- Graduate Studies Final Examination in Research and StatisticsDocument4 pagesGraduate Studies Final Examination in Research and StatisticsZyreane FernandezNo ratings yet
- Statistics exam results and data analysisDocument3 pagesStatistics exam results and data analysisMD Jabed MurshedNo ratings yet
- Chapter 4 (Hypothesis Testing)Document20 pagesChapter 4 (Hypothesis Testing)Dyg Nademah Pengiran MustaphaNo ratings yet
- Uji Mann WhitneyDocument3 pagesUji Mann WhitneyMuhamad Alpin DwizahraNo ratings yet
- Student Details and Final AssessmentDocument8 pagesStudent Details and Final AssessmentNavya VinnyNo ratings yet
- QAM 2 End Term Deepak PrajapatiDocument7 pagesQAM 2 End Term Deepak PrajapatiSakshi BahetiNo ratings yet
- SPSS ExerciseDocument11 pagesSPSS ExerciseAshish TewariNo ratings yet
- RM 2020Document9 pagesRM 2020Vinit D'souzaNo ratings yet
- Fundamental Information Technology Engineer Examination (Morning)Document35 pagesFundamental Information Technology Engineer Examination (Morning)Air_zaNo ratings yet
- Exercises (Chapter 3 and 4) : A B C DDocument3 pagesExercises (Chapter 3 and 4) : A B C Dcalvinteo89No ratings yet
- Fiitjee: All India Test SeriesDocument14 pagesFiitjee: All India Test SeriesRishiNo ratings yet
- Print Out SPSSDocument9 pagesPrint Out SPSSWan Azrika Muhamad ZukiNo ratings yet
- University of ZimbabweDocument7 pagesUniversity of Zimbabwekundayi shavaNo ratings yet
- Nafisatu Khoirun Nisa' - 16431020Document6 pagesNafisatu Khoirun Nisa' - 16431020Nafisatu Khoirun NisaNo ratings yet
- Chapter Iv Results and DiscussionDocument15 pagesChapter Iv Results and DiscussionAmbar WibowoNo ratings yet
- MBA Business Statistics Exam QuestionsDocument2 pagesMBA Business Statistics Exam QuestionsNishant TripathiNo ratings yet
- Mock Test PractiseDocument6 pagesMock Test Practisevijaylaxmimudliar2006No ratings yet
- JB Test: Test For NormalityDocument9 pagesJB Test: Test For NormalitytheonlypaulNo ratings yet
- CU MBA Questions 1st Sem 2015Document29 pagesCU MBA Questions 1st Sem 2015nivesaha48No ratings yet
- 0s5_9MA0-31_Statistics_-_Mock_set_5_mark_scheme_pdfDocument12 pages0s5_9MA0-31_Statistics_-_Mock_set_5_mark_scheme_pdfmustafaciplak0612No ratings yet
- Bachelor of Computer Applications (Bca) (Revised) Term-End Examination December, 2020Document6 pagesBachelor of Computer Applications (Bca) (Revised) Term-End Examination December, 2020HIDDEN ZONENo ratings yet
- Class-Xi ECONOMICS (030) ANNUAL EXAM (2020-21) : General InstructionsDocument8 pagesClass-Xi ECONOMICS (030) ANNUAL EXAM (2020-21) : General Instructionsadarsh krishnaNo ratings yet
- TKKDDocument7 pagesTKKDUyên VũNo ratings yet
- Mat 152-Test 1 Review Spring 2020Document14 pagesMat 152-Test 1 Review Spring 2020Alejandra TexidorNo ratings yet
- 954/3 STPM (PCS3 2020) : Section A (45 Marks) Answer All QuestionsDocument8 pages954/3 STPM (PCS3 2020) : Section A (45 Marks) Answer All QuestionsWendy LohNo ratings yet
- Year Level Q1A: CrosstabDocument12 pagesYear Level Q1A: CrosstabJenniferNo ratings yet
- Tugas Biostatiska Annisa RahmawatiDocument8 pagesTugas Biostatiska Annisa RahmawatiAnnisa RahmawatiNo ratings yet
- Statistics 252 - Midterm Exam: Instructor: Paul CartledgeDocument7 pagesStatistics 252 - Midterm Exam: Instructor: Paul CartledgeRauNo ratings yet
- De1 ML186 NLTK-va-TKDN 260921Document4 pagesDe1 ML186 NLTK-va-TKDN 260921tri le huynh ducNo ratings yet
- Correlation and Scatter GraphsDocument7 pagesCorrelation and Scatter Graphskaziba stephenNo ratings yet
- OU Osmania University - MBA - 2016 - 1st Semester - Jan - 1025 SM Statistics For ManagementDocument2 pagesOU Osmania University - MBA - 2016 - 1st Semester - Jan - 1025 SM Statistics For ManagementRachana PNo ratings yet
- ANOVA HomeworkDocument7 pagesANOVA HomeworkRobert Michael CorpusNo ratings yet
- Correlation Between Class Attendance and Exam ResultsDocument6 pagesCorrelation Between Class Attendance and Exam ResultsasbiniNo ratings yet
- Đề thi kết thúc học phần Nguyên lý thống kê kinh tế – quốc tế TOAE301"TITLE"Đề thi kết thúc học phần Nguyên lý thống kê kinh tế quốc tế tại trường Đại học Ngoại thươngDocument4 pagesĐề thi kết thúc học phần Nguyên lý thống kê kinh tế – quốc tế TOAE301"TITLE"Đề thi kết thúc học phần Nguyên lý thống kê kinh tế quốc tế tại trường Đại học Ngoại thươngngô long phạmNo ratings yet
- Quiz c345 A161 PDFDocument5 pagesQuiz c345 A161 PDFSyai GenjNo ratings yet
- My Sample TestDocument26 pagesMy Sample TestFayusri RoyfantoNo ratings yet
- Reading 2 Time-Series AnalysisDocument47 pagesReading 2 Time-Series Analysistristan.riolsNo ratings yet
- Praktikum Statistika 1Document2 pagesPraktikum Statistika 1gres sinagaNo ratings yet
- 15ECSC701 576 KLE48-15Ecsc701 Set2Document5 pages15ECSC701 576 KLE48-15Ecsc701 Set2Aniket AmbekarNo ratings yet
- Perhitungan VariableDocument5 pagesPerhitungan Variableago setiadiNo ratings yet
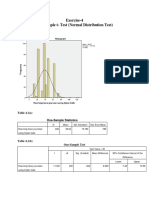
- Exercise-4 One Sample T-Test (Normal Distribution Test)Document10 pagesExercise-4 One Sample T-Test (Normal Distribution Test)Prarthana BorahNo ratings yet
- CRAFT: A Sample Computation of Savings From A Feasible Pairwise InterchangeDocument15 pagesCRAFT: A Sample Computation of Savings From A Feasible Pairwise Interchangeajeng.saraswatiNo ratings yet
- 6b7526addcf1248bdad9ff785e18c189_lecture16Document29 pages6b7526addcf1248bdad9ff785e18c189_lecture16Rak ADURNo ratings yet
- Qusetion 111 2 Data Analysis Assignment (問題卷)Document4 pagesQusetion 111 2 Data Analysis Assignment (問題卷)huangNo ratings yet
- Inter Rater Agreement Tugas Ns. SuniDocument5 pagesInter Rater Agreement Tugas Ns. Suniaprilia_ivhan04No ratings yet
- Homework 8-Huilin ZhangDocument9 pagesHomework 8-Huilin ZhangMax RahmanNo ratings yet
- Q2 2021 Fundamental IT Engineer Examination (Morning)Document27 pagesQ2 2021 Fundamental IT Engineer Examination (Morning)Pham Tien ThanhNo ratings yet
- Statistics 13A - Summer Session II 2009 Sample Midterm 1Document14 pagesStatistics 13A - Summer Session II 2009 Sample Midterm 1FatimaIjazNo ratings yet
- Learning Activity Statistics Exercises Template 1Document8 pagesLearning Activity Statistics Exercises Template 1Linghui Gao-GustaveNo ratings yet
- Classical Item and Test Analysis Report Ujian Sejarah Tahun 4Document23 pagesClassical Item and Test Analysis Report Ujian Sejarah Tahun 4waniNo ratings yet
- Let's Practise: Maths Workbook Coursebook 7From EverandLet's Practise: Maths Workbook Coursebook 7No ratings yet
- Preliminary solutions exam group analysisDocument5 pagesPreliminary solutions exam group analysisHenryck SpierenburgNo ratings yet
- Answers Test 6 2019-2020 - FinalDocument1 pageAnswers Test 6 2019-2020 - FinalHenryck SpierenburgNo ratings yet
- Answers Test 4 - FinalDocument1 pageAnswers Test 4 - FinalHenryck SpierenburgNo ratings yet
- Answers Test 5 2019-2020 - FinalDocument1 pageAnswers Test 5 2019-2020 - FinalHenryck SpierenburgNo ratings yet
- Answers Test 1Document2 pagesAnswers Test 1Henryck SpierenburgNo ratings yet
- Exercise 1 (Exam December 2012)Document30 pagesExercise 1 (Exam December 2012)Henryck SpierenburgNo ratings yet
- SPSS Assignment 1 Applied Statistics 2, 2019/20: Tutorial Group: Team Number: 8 Student 1 NameDocument4 pagesSPSS Assignment 1 Applied Statistics 2, 2019/20: Tutorial Group: Team Number: 8 Student 1 NameHenryck SpierenburgNo ratings yet
- Sample Exam 1Document10 pagesSample Exam 1Henryck SpierenburgNo ratings yet
- Sample Exam 1Document10 pagesSample Exam 1Henryck SpierenburgNo ratings yet
- Appendix G: Time Value of Money Solutions To Brief ExercisesDocument13 pagesAppendix G: Time Value of Money Solutions To Brief ExercisesHenryck SpierenburgNo ratings yet
- CH 05Document77 pagesCH 05Minh ThưNo ratings yet
- Display, Operate, Switch, Control, Regulate and Communicate: For Sales and SupportDocument24 pagesDisplay, Operate, Switch, Control, Regulate and Communicate: For Sales and SupportVictor Rolando Tarifa BlancoNo ratings yet
- Ignou MCS 14Document5 pagesIgnou MCS 14Abhishek MandalNo ratings yet
- Giant Salt Basin in Peru OverlookedDocument18 pagesGiant Salt Basin in Peru OverlookedFred LuqueNo ratings yet
- CWI - Part A Fundamentals Examination (Full) PDFDocument43 pagesCWI - Part A Fundamentals Examination (Full) PDFJulian Ramirez Ospina100% (4)
- Adventures in Lead Times PDFDocument20 pagesAdventures in Lead Times PDFAvinash RoutrayNo ratings yet
- CICADA2017Document60 pagesCICADA2017adu666No ratings yet
- Cswip 3.1 Practice QuestionDocument22 pagesCswip 3.1 Practice QuestionKoya ThangalNo ratings yet
- Practical Research 2 Activity 1Document1 pagePractical Research 2 Activity 1Pepito Manloloko100% (1)
- Power Systems Dynamics NotesDocument47 pagesPower Systems Dynamics Notessetsindia3735100% (1)
- Instrument Note RangesDocument11 pagesInstrument Note RangesWalter Macasiano GravadorNo ratings yet
- Erickson Power Electronics PDFDocument2 pagesErickson Power Electronics PDFStephanie0% (2)
- A New Fault Location Method For Underground Cables in Distribution SystemsDocument5 pagesA New Fault Location Method For Underground Cables in Distribution SystemsRagil SenpaiNo ratings yet
- RMM 31 FINAL - CompressedDocument117 pagesRMM 31 FINAL - CompressedSong BeeNo ratings yet
- PVTSim Method Documentation by CALSEPDocument179 pagesPVTSim Method Documentation by CALSEPAnonymous Vbv8SHv0bNo ratings yet
- FFHDocument763 pagesFFHnilesh2215No ratings yet
- Apr24-3g CDocument4 pagesApr24-3g COscar Payan ViamonteNo ratings yet
- AP Music Theory - Summer Work Packet (Ada)Document28 pagesAP Music Theory - Summer Work Packet (Ada)pj.sulls1234No ratings yet
- Mean and variance of discrete random variablesDocument11 pagesMean and variance of discrete random variablesJovito EspantoNo ratings yet
- Introduction Programming C EngineersDocument648 pagesIntroduction Programming C EngineersClaudio Di LivioNo ratings yet
- Profibus-Gateway v3 Eng 2Document64 pagesProfibus-Gateway v3 Eng 2Bob YahyaNo ratings yet
- Road Work & DrainageDocument17 pagesRoad Work & Drainagentah84No ratings yet
- Stress Corrosion Cracking in Stainless SteelDocument3 pagesStress Corrosion Cracking in Stainless Steelmavis16No ratings yet
- Distributed Safety: Sensor-Actuator Interfacing: SITRAIN Training ForDocument23 pagesDistributed Safety: Sensor-Actuator Interfacing: SITRAIN Training Forcarsan87No ratings yet
- A Framework and Methodology For Evaluating E-Commerce Web SitesDocument15 pagesA Framework and Methodology For Evaluating E-Commerce Web SitesVic KyNo ratings yet
- Chapter 5 - Protein Purification and Characterization Techniques (1) (Compatibility Mode)Document23 pagesChapter 5 - Protein Purification and Characterization Techniques (1) (Compatibility Mode)Nadine SabadoNo ratings yet
- WOCD-0306-02 Rotary Drilling With Casing - A Field Proven Method of Reducing Wellbore Construction CostDocument7 pagesWOCD-0306-02 Rotary Drilling With Casing - A Field Proven Method of Reducing Wellbore Construction CostMile SikiricaNo ratings yet
- Nidia Mindiyarti: Projects Big Data and Machine LearningDocument1 pageNidia Mindiyarti: Projects Big Data and Machine Learningnidia mindiyartiNo ratings yet
- AnovaDocument49 pagesAnovabrianmore10No ratings yet
- Aptitude and Reasoning QuestionsDocument5 pagesAptitude and Reasoning Questionsvyom saxenaNo ratings yet
- Tanner Tools v16.0 Release NotesDocument14 pagesTanner Tools v16.0 Release NotesPareve SolanoNo ratings yet