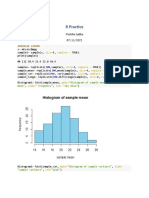
You might also like
- Clustering On Boston DatasetDocument3 pagesClustering On Boston Datasetanubhav582No ratings yet
- Writing Efficient R CodeDocument5 pagesWriting Efficient R CodeOctavio FloresNo ratings yet
- CFD Applied To Turbo MachineryDocument36 pagesCFD Applied To Turbo Machinerybakri10101No ratings yet
- The Kalman Decomposition PDFDocument5 pagesThe Kalman Decomposition PDFJose H. Vivas100% (2)
- Practica 2 TemperaturaDocument11 pagesPractica 2 TemperaturaJilmeNo ratings yet
- R FourierDocument18 pagesR FourierNUR ARZILAH ISMAILNo ratings yet
- Examen-Regresion MiguelEsparzaDocument9 pagesExamen-Regresion MiguelEsparzamaesparza2307No ratings yet
- Bioestadistica: Clara Carner 2023-05-29Document4 pagesBioestadistica: Clara Carner 2023-05-29Clara CarnerNo ratings yet
- R Code Default Data PDFDocument10 pagesR Code Default Data PDFShubham Wadhwa 23No ratings yet
- 20BCE1205 Lab6Document12 pages20BCE1205 Lab6SHUBHAM OJHANo ratings yet
- R PracticeDocument38 pagesR PracticeyoshitaNo ratings yet
- R Intro STAT5000Document17 pagesR Intro STAT5000vinay kumarNo ratings yet
- R HomeworkDocument13 pagesR HomeworkTesta MestaNo ratings yet
- Final Predictive Vaibhav 2020Document101 pagesFinal Predictive Vaibhav 2020sristi agrawalNo ratings yet
- Panel 2Document26 pagesPanel 2tilfaniNo ratings yet
- R CommandsDocument18 pagesR CommandsKhizra AmirNo ratings yet
- Downloading and Exploring FTS Data R CodeDocument11 pagesDownloading and Exploring FTS Data R CodeBevNo ratings yet
- Modelos Lineales y Modelos Lineales GeneralizadosDocument5 pagesModelos Lineales y Modelos Lineales Generalizadosanita34621No ratings yet
- Nthu BacshwDocument8 pagesNthu Bacshw黃淑菱No ratings yet
- K5 (20) - GLM - PC - B: 1. Logistic RegressionDocument15 pagesK5 (20) - GLM - PC - B: 1. Logistic RegressionKornelija JanušytėNo ratings yet
- StaticsTestDocument6 pagesStaticsTestSOWMIA R 2248056No ratings yet
- Kinh tế lượng code RDocument10 pagesKinh tế lượng code RNgọc Quỳnh Anh NguyễnNo ratings yet
- Entregable1: Leidy Naranjo - Juan Pablo Pelaez 2022-03-17Document7 pagesEntregable1: Leidy Naranjo - Juan Pablo Pelaez 2022-03-17eduardoNo ratings yet
- Name: Reg. No.: Lab Exercise:: Shivam Batra 19BPS1131Document10 pagesName: Reg. No.: Lab Exercise:: Shivam Batra 19BPS1131Shivam Batra100% (1)
- LabNote 3Document3 pagesLabNote 3CHAI TZE ANNNo ratings yet
- Machine LeaarningDocument32 pagesMachine LeaarningLuis Eduardo Calderon CantoNo ratings yet
- Dam CheatsheetDocument4 pagesDam CheatsheetMradulNo ratings yet
- Data Science Comp 2Document13 pagesData Science Comp 2tobiasNo ratings yet
- Home ConstructionDocument8 pagesHome Constructionphatakpriya108No ratings yet
- Taller RDocument37 pagesTaller RHuevo SapeNo ratings yet
- H-311 Linear Regression Analysis With RDocument71 pagesH-311 Linear Regression Analysis With RNat Boltu100% (1)
- Cia DoeDocument2 pagesCia Doeshathriya.narayananNo ratings yet
- Control Flow - LoopingDocument18 pagesControl Flow - LoopingNur SyazlianaNo ratings yet
- Ancova: R MarkdownDocument6 pagesAncova: R Markdownapi-285833118No ratings yet
- Individual Variable Data Analysis: WarningDocument38 pagesIndividual Variable Data Analysis: WarningNikhil YadatiNo ratings yet
- Multiple Linear RegressionDocument14 pagesMultiple Linear RegressionNamdev100% (1)
- Chapter 9 Cox Proportional Hazards: Library (Survival)Document10 pagesChapter 9 Cox Proportional Hazards: Library (Survival)Yosef GUEVARA SALAMANCANo ratings yet
- Image ClassifactionDocument17 pagesImage Classifactionmk10octNo ratings yet
- Shivam Batra (19BPS1131) 21/01/2022: ListDocument5 pagesShivam Batra (19BPS1131) 21/01/2022: ListShivam BatraNo ratings yet
- ch12bt20 GDP-updateDocument15 pagesch12bt20 GDP-updateNguyễn OanhNo ratings yet
- A1Document8 pagesA1DASHPAGALNo ratings yet
- Ex 10 - Decision Tree With Rpart and Fancy Plot and Cardio DataDocument4 pagesEx 10 - Decision Tree With Rpart and Fancy Plot and Cardio DataNopeNo ratings yet
- PlottingDocument21 pagesPlottingTonyNo ratings yet
- Coding Analisis SpasialDocument9 pagesCoding Analisis SpasialRochmanto_HaniNo ratings yet
- PCA and FA CommandsDocument13 pagesPCA and FA CommandsNguyễn OanhNo ratings yet
- Chemo Mortality AnalysisDocument5 pagesChemo Mortality AnalysisAyu HutamiNo ratings yet
- Assignment-1 80501Document6 pagesAssignment-1 80501rishabh7aroraNo ratings yet
- PracticalDocument22 pagesPractical786chetanNo ratings yet
- Practical Machine LearningDocument11 pagesPractical Machine Learningminhajur rahmanNo ratings yet
- 20BCE1205 Lab4Document7 pages20BCE1205 Lab4SHUBHAM OJHANo ratings yet
- Bda AssignDocument15 pagesBda AssignAishwarya BiradarNo ratings yet
- 20BCE1205 Lab4Document7 pages20BCE1205 Lab4SHUBHAM OJHANo ratings yet
- 20BCE1205 Lab3Document9 pages20BCE1205 Lab3SHUBHAM OJHANo ratings yet
- Assignment 11-17-15: Michael Petzold November 19, 2015Document4 pagesAssignment 11-17-15: Michael Petzold November 19, 2015mikey pNo ratings yet
- Lab-9 RMDDocument5 pagesLab-9 RMDMaira SulaimanovaNo ratings yet
- Antlion bs2460Document3 pagesAntlion bs2460calvinleow1205No ratings yet
- STA2050 Assignment 2Document10 pagesSTA2050 Assignment 2gugugagaNo ratings yet
- Kickstarter Success PredictionDocument17 pagesKickstarter Success PredictionTianhui XuNo ratings yet
- MBA19141Document14 pagesMBA19141Ankur TulsyanNo ratings yet
- Shark Tank Deal Prediction - Uudhya - Dec 2019Document16 pagesShark Tank Deal Prediction - Uudhya - Dec 2019usoramaNo ratings yet
- Count Models in JAGSDocument16 pagesCount Models in JAGS18rosa18No ratings yet
- Pricing FormulaesDocument15 pagesPricing Formulaesravi_uppalamurthy100% (1)
- PID Controller Design For Two Tanks Liquid Level Control System Using MatlabDocument7 pagesPID Controller Design For Two Tanks Liquid Level Control System Using MatlabJoko SantosoNo ratings yet
- General Mathematics AssignmentDocument2 pagesGeneral Mathematics AssignmentAudreyNo ratings yet
- Twist RateDocument3 pagesTwist RateFernando ParabellumNo ratings yet
- Chapter 4Document7 pagesChapter 4yared gebrewoldNo ratings yet
- HKIMO 2020 S1 Semi-Final Set 9Document3 pagesHKIMO 2020 S1 Semi-Final Set 9Saung Ei Shoon LeiNo ratings yet
- Solution To Assignment 1Document3 pagesSolution To Assignment 1uyenthuc16No ratings yet
- RSCH2122 Inquiries ExamDocument5 pagesRSCH2122 Inquiries ExamJonel BautistaNo ratings yet
- #Analysis Done in LPILE Plus v5 0Document9 pages#Analysis Done in LPILE Plus v5 0Marko AdamovićNo ratings yet
- CBSE Class 10 Pair of Linear Equations in 2 VariablesDocument7 pagesCBSE Class 10 Pair of Linear Equations in 2 VariablesSandyaNo ratings yet
- 8 Project Risk ManagementDocument43 pages8 Project Risk ManagementMUHAMAD TARUNA PRAMUDHITANo ratings yet
- Mark Scheme (Final) January 2009: GCE Chemistry (6244/01)Document20 pagesMark Scheme (Final) January 2009: GCE Chemistry (6244/01)Aaisha AfaNo ratings yet
- Ken Black QA ch17Document58 pagesKen Black QA ch17Rushabh Vora100% (1)
- Postman Quick Reference GuideDocument22 pagesPostman Quick Reference GuideDanBoRu100% (4)
- Kubios HRV 2.2 Users GuideDocument44 pagesKubios HRV 2.2 Users GuideSimon HayekNo ratings yet
- TE13xx TwinCAT 3 ScopeView enDocument118 pagesTE13xx TwinCAT 3 ScopeView engalahan66No ratings yet
- La Salle 2015-2016 Mid Year Exam F3 Math Paper 1Document20 pagesLa Salle 2015-2016 Mid Year Exam F3 Math Paper 120211d051No ratings yet
- 3.1 Instantaneous and Average Power Instantaneous PowerDocument9 pages3.1 Instantaneous and Average Power Instantaneous PowerJohn Steven Aala100% (1)
- SPT Convertion To N60 and N1,60Document2 pagesSPT Convertion To N60 and N1,60Clement Onwordi100% (1)
- MergedDocument352 pagesMergedUsama malikNo ratings yet
- Notes On Elementary Probability and StatisticsDocument125 pagesNotes On Elementary Probability and StatisticsMarrianne Joie TalosigNo ratings yet
- Soltuion - Chapter 14 Practical Gemetry-UnlockedDocument20 pagesSoltuion - Chapter 14 Practical Gemetry-UnlockedESWARAN SANTHOSHNo ratings yet
- UT Dallas Syllabus For Se2370.501 05s Taught by Weichen Wong (Wew021000)Document1 pageUT Dallas Syllabus For Se2370.501 05s Taught by Weichen Wong (Wew021000)UT Dallas Provost's Technology GroupNo ratings yet
- Fractions, Decimals, ApproximationsDocument4 pagesFractions, Decimals, ApproximationsEbube KennethNo ratings yet
- StatisticsDocument16 pagesStatisticsshiraj_sgNo ratings yet
- QP PB-2 Stand Set-4Document8 pagesQP PB-2 Stand Set-4cartooncompany73No ratings yet
- Axial and Centrifugal Compressor Mean Line Flow Analysis MethodDocument38 pagesAxial and Centrifugal Compressor Mean Line Flow Analysis Methodtadele10No ratings yet
- Assignment For Dynamic ProgrammingDocument5 pagesAssignment For Dynamic Programmingnikhil anandNo ratings yet