You might also like
- Data Governance PlaybookDocument168 pagesData Governance PlaybookVinh Tran100% (13)
- Quality Is FreeDocument3 pagesQuality Is FreeAlexander Tunggal100% (1)
- Big Data Analytics Seminar Report 2020-21Document21 pagesBig Data Analytics Seminar Report 2020-21Bangkok Dude75% (20)
- CRISC Practice TestDocument23 pagesCRISC Practice Testjuancedenog100% (3)
- Chapter 9 Business Analytics AssignementsDocument7 pagesChapter 9 Business Analytics Assignementschris waltersNo ratings yet
- Knowledge Management and Predictive Analytics in IT Project RisksDocument8 pagesKnowledge Management and Predictive Analytics in IT Project RisksEditor IJTSRDNo ratings yet
- Brand ManagementDocument40 pagesBrand Managementحسيب مرتضي100% (773)
- Gap AnalysisDocument4 pagesGap AnalysisATTALLH100% (2)
- Big Data Quality Eval RGDocument8 pagesBig Data Quality Eval RGNatalia FernandesNo ratings yet
- Data Qualityin Big Data Processing Issues Solutionsand Open ProblemsDocument9 pagesData Qualityin Big Data Processing Issues Solutionsand Open ProblemsmarksalaoNo ratings yet
- Data Quality: The Other Face of Big Data: Barna Saha Divesh SrivastavaDocument4 pagesData Quality: The Other Face of Big Data: Barna Saha Divesh Srivastavausman dilawarNo ratings yet
- Soft v10 n12 2017 1Document20 pagesSoft v10 n12 2017 1Bisyron WahyudiNo ratings yet
- Quality Assurance For Big Data Application - Issues, Challenges, and NeedsDocument7 pagesQuality Assurance For Big Data Application - Issues, Challenges, and NeedsAhmed M. HashimNo ratings yet
- Data Quality Considerations for Big Data and Machine LearningDocument21 pagesData Quality Considerations for Big Data and Machine Learninghideki hidekiNo ratings yet
- Chapter 1 - Introduction: Agile Big Data AnalyticsDocument30 pagesChapter 1 - Introduction: Agile Big Data AnalyticsRishabh DwivediNo ratings yet
- The Deal With Big DataDocument8 pagesThe Deal With Big DataHirvin AliagaNo ratings yet
- An Iterative Methodology For Defining Big DataDocument20 pagesAn Iterative Methodology For Defining Big DataGUSTAVO ADOLFO MELGAREJO ZELAYANo ratings yet
- Big Data AnalyticsDocument7 pagesBig Data AnalyticsMohd JunaidNo ratings yet
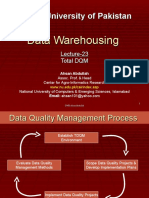
- Virtual University of Pakistan - Data Warehousing Lecture-23 Total DQMDocument12 pagesVirtual University of Pakistan - Data Warehousing Lecture-23 Total DQMAhmed MaherNo ratings yet
- Challenges in Big Data Analytics TechniquesDocument6 pagesChallenges in Big Data Analytics TechniquesIshabelle Marie BalanayNo ratings yet
- Big Data A Survey DineshDocument9 pagesBig Data A Survey DineshdineshgomberNo ratings yet
- Sustainability 14 13038Document23 pagesSustainability 14 13038vivinoswaltNo ratings yet
- JSS D 18 00868 QualityAttributesintheContextofBigDataSystemsDocument26 pagesJSS D 18 00868 QualityAttributesintheContextofBigDataSystemsDavid SalgadoNo ratings yet
- Real-Time Data Quality Monitoring System For Data Cleansing: January 2012Document12 pagesReal-Time Data Quality Monitoring System For Data Cleansing: January 2012Ardian SNo ratings yet
- Evaluations of Big Data Processing PDFDocument10 pagesEvaluations of Big Data Processing PDFd_aparigrahaNo ratings yet
- Ipc2022-87872 Structured, Systematic Threat Based Approach To Evaluate and ImproveDocument8 pagesIpc2022-87872 Structured, Systematic Threat Based Approach To Evaluate and ImproveOswaldo MontenegroNo ratings yet
- Comparative Study on Data Quality Management in Data WarehousesDocument10 pagesComparative Study on Data Quality Management in Data WarehousesAwais SultanNo ratings yet
- Big Data Analytics Seminar Report SummaryDocument17 pagesBig Data Analytics Seminar Report SummaryVanditNo ratings yet
- An Extensible Framework For Data Reliability Assessment: Óscar Oliveira and Bruno OliveiraDocument8 pagesAn Extensible Framework For Data Reliability Assessment: Óscar Oliveira and Bruno OliveiraBruno OliveiraNo ratings yet
- How To Conduct A Big Data Maturity Assessment?: by J.W. MiddelburgDocument10 pagesHow To Conduct A Big Data Maturity Assessment?: by J.W. MiddelburgstudentNo ratings yet
- Big Data Benchmarking RequirementsDocument7 pagesBig Data Benchmarking RequirementsNadeem KhanNo ratings yet
- A Big Data Analytics Study Challenges, Unresolved Research Issues, and TechniquesDocument8 pagesA Big Data Analytics Study Challenges, Unresolved Research Issues, and TechniquesSagar ManjareNo ratings yet
- Big Data Computing and Clouds: Trends and Future DirectionsDocument44 pagesBig Data Computing and Clouds: Trends and Future DirectionsJobi VijayNo ratings yet
- Importance of Process Mining For Big Data Requirements EngineeringDocument12 pagesImportance of Process Mining For Big Data Requirements EngineeringAnonymous Gl4IRRjzNNo ratings yet
- Challenging Tools On Research Issues in Big Data Analytics: Althaf Rahaman - SK, Sai Rajesh.K .Girija Rani KDocument8 pagesChallenging Tools On Research Issues in Big Data Analytics: Althaf Rahaman - SK, Sai Rajesh.K .Girija Rani KKarthi VijayNo ratings yet
- Introduction & ChallengesDocument3 pagesIntroduction & ChallengesmydhiliNo ratings yet
- Chapter 2 External Analysis Big DataDocument20 pagesChapter 2 External Analysis Big DataardadiNo ratings yet
- A Study of Big Data Characteristics: October 2016Document5 pagesA Study of Big Data Characteristics: October 2016Johnny AndreatyNo ratings yet
- Towards A Conceptual Approach of Analytical Engineering For Big DataDocument9 pagesTowards A Conceptual Approach of Analytical Engineering For Big DataJulian RojasNo ratings yet
- A Semiotic Approach To Investigate Quality Issues of Open Big Data EcosystemsDocument10 pagesA Semiotic Approach To Investigate Quality Issues of Open Big Data EcosystemsManuel HerreraNo ratings yet
- AFramework For Data Quality in Data WarehousingDocument7 pagesAFramework For Data Quality in Data WarehousingSarah Jean TrajanoNo ratings yet
- Bigdata DocumentationDocument20 pagesBigdata DocumentationBabu GiriNo ratings yet
- Paper Icic Reza 2019 PDFDocument6 pagesPaper Icic Reza 2019 PDFMohammad RezaNo ratings yet
- Big Data: How To Handle: A Survey: Dinesh MCA Deptt. PDM University, Bahadurgarh ABC MCA DepttDocument8 pagesBig Data: How To Handle: A Survey: Dinesh MCA Deptt. PDM University, Bahadurgarh ABC MCA DepttdineshNo ratings yet
- Measuring Data Quality With Weighted Metrics: Total Quality Management & Business ExcellenceDocument14 pagesMeasuring Data Quality With Weighted Metrics: Total Quality Management & Business ExcellenceSamaneh MardiNo ratings yet
- Data Quality Setting Organizational PoliciesDocument9 pagesData Quality Setting Organizational PoliciesSamaneh MardiNo ratings yet
- 184.big Data Analytics A Classification of Data Quality Assessment and Improvement MethodsDocument8 pages184.big Data Analytics A Classification of Data Quality Assessment and Improvement MethodsDivi DivyaNo ratings yet
- Architecture and Design For Regression Test Framework To Fuse Big Data StackDocument9 pagesArchitecture and Design For Regression Test Framework To Fuse Big Data StackIJRASETPublicationsNo ratings yet
- Ey Reporting Big Data Transform AuditDocument5 pagesEy Reporting Big Data Transform AuditTHUY NGUYEN THANHNo ratings yet
- Challenging Tools On Research Issues in Big Data AnalyticsDocument4 pagesChallenging Tools On Research Issues in Big Data AnalyticsPriyaNo ratings yet
- (IJCST-V5I2P73) :supriya Haribhau Pawar, Prof. Dr. Devendrasingh ThakoreDocument4 pages(IJCST-V5I2P73) :supriya Haribhau Pawar, Prof. Dr. Devendrasingh ThakoreEighthSenseGroupNo ratings yet
- A Mechanism of Maturity Improvement For Data Quality Management in PT. ABCDocument6 pagesA Mechanism of Maturity Improvement For Data Quality Management in PT. ABCRizki RomodhonNo ratings yet
- Big Data Understanding Big DataDocument9 pagesBig Data Understanding Big DataIulia TNo ratings yet
- Big Data Analytics in Cloud ComputingDocument10 pagesBig Data Analytics in Cloud ComputingParag BhangaleNo ratings yet
- Lee, Y. Et Al. (2014)Document18 pagesLee, Y. Et Al. (2014)jacobNo ratings yet
- Machine Learning Big Data Challenges ApproachesDocument22 pagesMachine Learning Big Data Challenges ApproachesVipin GeorgeNo ratings yet
- Theory FirstDocument33 pagesTheory FirstJyNo ratings yet
- The - UAE - Employees - Perceptions - Towards - Factors - For - 230811 - 225711Document19 pagesThe - UAE - Employees - Perceptions - Towards - Factors - For - 230811 - 225711rakshitha1509No ratings yet
- Big Data PaperDocument8 pagesBig Data PaperNazira SardarNo ratings yet
- Rasool 2021 MBE Digital Supply Chain Performance Metrics - A Literature ReviewDocument15 pagesRasool 2021 MBE Digital Supply Chain Performance Metrics - A Literature ReviewAbdul HafeezNo ratings yet
- ArticleDocument3 pagesArticleAhmad HafiyNo ratings yet
- 125986548Document11 pages125986548maryamNo ratings yet
- Navigating The Quality Quandaries: Big Data Applications' Challenges in Supply Chain ManagementDocument7 pagesNavigating The Quality Quandaries: Big Data Applications' Challenges in Supply Chain ManagementInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Cncec Quality Policy StatementDocument4 pagesCncec Quality Policy Statementchao gaoNo ratings yet
- Alhola JuhoDocument32 pagesAlhola JuhoSuresh AnandNo ratings yet
- Jurnal Analisis Pengendalian Mutu Pada Proses Pembekuan Udang Vaname (Litopenaeus Vannamei) Dengan Six SigmaDocument12 pagesJurnal Analisis Pengendalian Mutu Pada Proses Pembekuan Udang Vaname (Litopenaeus Vannamei) Dengan Six SigmaIrham FadhillaNo ratings yet
- RHB R6.2 Point Release PDFDocument14 pagesRHB R6.2 Point Release PDFRaju ValiyaNo ratings yet
- Cbme Chap 9 FinallllDocument28 pagesCbme Chap 9 FinallllKirk Rumar ClavelNo ratings yet
- Nuclear, Safety and Protection Catalogue - English 2012Document96 pagesNuclear, Safety and Protection Catalogue - English 2012Indra UchihaNo ratings yet
- MPS 3lpeDocument11 pagesMPS 3lpeabhishek_me03No ratings yet
- PPAM Final NotesDocument51 pagesPPAM Final NotesShimels ShitayeNo ratings yet
- Fire Service Valves CatalogueDocument76 pagesFire Service Valves Cataloguearvint_1999No ratings yet
- Tuv Rheinland Iso 3834 Certification enDocument2 pagesTuv Rheinland Iso 3834 Certification enAdrewhassTechnicaNo ratings yet
- Irqb Guideline 6 Special Processes Rev01Document22 pagesIrqb Guideline 6 Special Processes Rev01Delong KongNo ratings yet
- QA QC Ques BANK CIE 1Document21 pagesQA QC Ques BANK CIE 1Rajha RajeswaranNo ratings yet
- Al Burraq Aluminium LLC, A UAE Based Aluminium-Glass CompanyDocument46 pagesAl Burraq Aluminium LLC, A UAE Based Aluminium-Glass CompanyShakeel Ahmad100% (1)
- Supplier - Quality - Manual - F4033735-Jan 2021Document31 pagesSupplier - Quality - Manual - F4033735-Jan 2021Ritesh DevrajNo ratings yet
- Operations and Information Management CHECK, FORMAT AND NUMBERDocument13 pagesOperations and Information Management CHECK, FORMAT AND NUMBERShahnewaj SharanNo ratings yet
- TQM Final 0Document7 pagesTQM Final 0Njoroge IkonyeNo ratings yet
- 1 - 安徽聚力 柱塞泵目录册Document66 pages1 - 安徽聚力 柱塞泵目录册WEI SHANGNo ratings yet
- CH 05Document41 pagesCH 05pravyramNo ratings yet
- Fishbone Ishikawa Diagram TemplateDocument1 pageFishbone Ishikawa Diagram TemplateKathryn AllenNo ratings yet
- QM BBP PDFDocument34 pagesQM BBP PDFErBikasKumarPathakNo ratings yet
- ISO 9001 Internal Audit Checklist GuideDocument22 pagesISO 9001 Internal Audit Checklist GuidePCNo ratings yet
- DMC Quality ManualDocument58 pagesDMC Quality ManualDMINFRANo ratings yet
- Gen San OrgMan-SLM-MODULE-1Document31 pagesGen San OrgMan-SLM-MODULE-1Julius Caesar MacusiNo ratings yet
- Epas Modules of InsDocument74 pagesEpas Modules of InsMelba33% (3)
- Name: Tamil Chelvi D/O Muniandy MATRIC NUM: MC210413305Document9 pagesName: Tamil Chelvi D/O Muniandy MATRIC NUM: MC210413305parnellaNo ratings yet
- Iso 9004-1-1994Document31 pagesIso 9004-1-1994Davood OkhovatNo ratings yet