You might also like
- Biostat and Research - PSS Sunder RaoDocument279 pagesBiostat and Research - PSS Sunder RaoPrincy Varghese67% (9)
- Ora Laboratory ManualDocument26 pagesOra Laboratory ManualshrikantmsdNo ratings yet
- CFA Level 1 Review - Quantitative MethodsDocument10 pagesCFA Level 1 Review - Quantitative MethodsAamirx6450% (2)
- Statistics For Managers Using Microsoft® Excel 5th Edition: Some Important Discrete Probability DistributionsDocument48 pagesStatistics For Managers Using Microsoft® Excel 5th Edition: Some Important Discrete Probability Distributionshasan jabrNo ratings yet
- Simplified Statistics For Small Numbers of Observations: R. B. Dean, and W. J. DixonDocument4 pagesSimplified Statistics For Small Numbers of Observations: R. B. Dean, and W. J. Dixonmanuelq9No ratings yet
- Do You Have Leptokurtophobia - WheelerDocument8 pagesDo You Have Leptokurtophobia - Wheelertehky63No ratings yet
- 4 Key Aspects To VariographyDocument14 pages4 Key Aspects To Variographysupri100% (2)
- 1-2-Graph ToolsDocument26 pages1-2-Graph ToolsDavid DonosoNo ratings yet
- Introduction To Predictive Modeling With Examples: David A. Dickey, N. Carolina State U., Raleigh, NCDocument14 pagesIntroduction To Predictive Modeling With Examples: David A. Dickey, N. Carolina State U., Raleigh, NCtempla73No ratings yet
- Overdetermined Systems Regression Analysis: Least Value, ADocument26 pagesOverdetermined Systems Regression Analysis: Least Value, AAdela CalotescuNo ratings yet
- Chapter 3 DispersionDocument12 pagesChapter 3 DispersionElan JohnsonNo ratings yet
- Midterm Self TestsDocument4 pagesMidterm Self TestsWalter GoldenNo ratings yet
- In Statistics and MathematicsDocument5 pagesIn Statistics and MathematicsEtsegenet TafesseNo ratings yet
- Notes Chapter2Document24 pagesNotes Chapter2sundari_muraliNo ratings yet
- Applied Statistics SummaryDocument9 pagesApplied Statistics SummaryRutger WentzelNo ratings yet
- Reference Manual LeapfrogDocument107 pagesReference Manual LeapfrogBoris Alarcón HasanNo ratings yet
- StatisticsDocument211 pagesStatisticsHasan Hüseyin Çakır100% (6)
- VariogramaDocument16 pagesVariogramaIvan Ramirez CaqueoNo ratings yet
- Variogramtutorial PDFDocument23 pagesVariogramtutorial PDFYo GoldNo ratings yet
- Statistical Application Da 2 SrishtiDocument7 pagesStatistical Application Da 2 SrishtiSimran MannNo ratings yet
- 1984 IBP 17 Chapter 8 StatisticsDocument71 pages1984 IBP 17 Chapter 8 StatisticsBabitha DhanaNo ratings yet
- MODULE IN STATISTICS Frequency Distribution and GraphDocument13 pagesMODULE IN STATISTICS Frequency Distribution and GraphFarah Mae Mosquite-GonzagaNo ratings yet
- Ken Black QA 5th Chapter 3 SolutionDocument47 pagesKen Black QA 5th Chapter 3 SolutionRushabh VoraNo ratings yet
- الثامنةDocument14 pagesالثامنةameerel3tma77No ratings yet
- Solution 1Document14 pagesSolution 1Mahesh JainNo ratings yet
- Introduction To Statistics and Data Analysis: Measure of Location, Variability and Graphical RepresentationDocument24 pagesIntroduction To Statistics and Data Analysis: Measure of Location, Variability and Graphical RepresentationFaizy GiiNo ratings yet
- 3.4.2 InstabilityDocument3 pages3.4.2 InstabilityFebry Roma RioNo ratings yet
- Answers Review Questions EconometricsDocument59 pagesAnswers Review Questions EconometricsZX Lee84% (25)
- Error Bars in Experimental BiologyDocument5 pagesError Bars in Experimental BiologyEsliMoralesRechyNo ratings yet
- Notes On Forecasting With Moving Averages - Robert NauDocument28 pagesNotes On Forecasting With Moving Averages - Robert Naupankaj.webmaster1218No ratings yet
- Revisiting A 90-Year-Old Debate: The Advantages of The Mean DeviationDocument14 pagesRevisiting A 90-Year-Old Debate: The Advantages of The Mean DeviationlacisagNo ratings yet
- Graphs and Digrams Used in PresentationDocument17 pagesGraphs and Digrams Used in Presentationnat70sha50No ratings yet
- The Chart For Individual Values by Don WheelerDocument7 pagesThe Chart For Individual Values by Don WheelerPetterNo ratings yet
- 2 Pengenalan GeostatistikDocument59 pages2 Pengenalan GeostatistikSAEF MAULANA DZIKRINo ratings yet
- And Estimation Sampling Distributions: Learning OutcomesDocument12 pagesAnd Estimation Sampling Distributions: Learning OutcomesDaniel SolhNo ratings yet
- Robability and TatisticsDocument43 pagesRobability and TatisticsNguyên Hạnh KhươngNo ratings yet
- Visualization - Hist and BoxDocument23 pagesVisualization - Hist and BoxAAKASHNo ratings yet
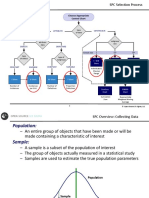
- What Is Sampling?: PopulationDocument4 pagesWhat Is Sampling?: PopulationFarhaNo ratings yet
- Photon StatisticsDocument11 pagesPhoton StatisticsyoitssmeNo ratings yet
- Lecture 2B Random Uncertainty in Physical MeasurementsDocument7 pagesLecture 2B Random Uncertainty in Physical Measurementsilet09No ratings yet
- SPC 0002Document14 pagesSPC 0002Deepa DhilipNo ratings yet
- Revisiting A 90-Year-Old Debate - The Advantages of The Mean DeviationDocument10 pagesRevisiting A 90-Year-Old Debate - The Advantages of The Mean DeviationAreem AbbasiNo ratings yet
- CE 459 Statistics: Assistant Prof. Muhammet Vefa AKPINARDocument211 pagesCE 459 Statistics: Assistant Prof. Muhammet Vefa AKPINARGhulam ShabirNo ratings yet
- Estadistica (Solucionario) - DevoreDocument483 pagesEstadistica (Solucionario) - DevoreJean Carlos RodríguezNo ratings yet
- Unit - 4 Subject: Business Research Methods: What Is Sampling?Document10 pagesUnit - 4 Subject: Business Research Methods: What Is Sampling?FarhaNo ratings yet
- EU Administrator Exams Workbook - Volume IDocument6 pagesEU Administrator Exams Workbook - Volume IeuinmotionNo ratings yet
- Outlier and NormalityDocument17 pagesOutlier and NormalityAnna Riana PutriyaNo ratings yet
- Interpret All Statistics and Graphs For Display Descriptive StatisticsDocument22 pagesInterpret All Statistics and Graphs For Display Descriptive StatisticsShenron InamoratoNo ratings yet
- Statistics Sample and Population Measure of Central TendencyDocument24 pagesStatistics Sample and Population Measure of Central TendencyyehnafarNo ratings yet
- Rules For GraphingDocument4 pagesRules For GraphingJack6994No ratings yet
- Resumen Gujarati EconometriaDocument8 pagesResumen Gujarati EconometriaJuventudes Provincia VallecaucanaNo ratings yet
- Chapter 3Document27 pagesChapter 3Hiruna ViduminaNo ratings yet
- Histograms: Construction, Analysis and Understanding: What Is A Histogram?Document3 pagesHistograms: Construction, Analysis and Understanding: What Is A Histogram?nixen99_gellaNo ratings yet
- Chapter10 Re ExpressingDataDocument26 pagesChapter10 Re ExpressingDataAmani ModiNo ratings yet
- Mathematics Statistical Square Root Mean SquaresDocument5 pagesMathematics Statistical Square Root Mean SquaresLaura TaritaNo ratings yet
- Basic StatisticsDocument23 pagesBasic StatisticsZAKAYO NJONYNo ratings yet
- Costa Etal 2018 GEBDocument14 pagesCosta Etal 2018 GEBpcorgoNo ratings yet
- 1433 ArticleText 6261 1 10 20210712Document63 pages1433 ArticleText 6261 1 10 20210712pcorgoNo ratings yet
- 2021gomezcorgosinhorivera Sanchez2021euroopeanjtax77886 89Document5 pages2021gomezcorgosinhorivera Sanchez2021euroopeanjtax77886 89pcorgoNo ratings yet
- Lundberg Etal 1998Document37 pagesLundberg Etal 1998pcorgoNo ratings yet
- 2358 2936 Nau 29 E2021015Document27 pages2358 2936 Nau 29 E2021015pcorgoNo ratings yet
- Barredo and DeGennaro 2020 - Not Just From Blood - Mosquito Nutrient Acquisition From Nectar SourcesDocument12 pagesBarredo and DeGennaro 2020 - Not Just From Blood - Mosquito Nutrient Acquisition From Nectar SourcespcorgoNo ratings yet
- Size, Shape, and Form Concepts of Allometry in Geometric MorphometricsDocument25 pagesSize, Shape, and Form Concepts of Allometry in Geometric MorphometricspcorgoNo ratings yet
- Classification and Ordination Methods As A Tool For Analyzing of Plant CommunitiesDocument34 pagesClassification and Ordination Methods As A Tool For Analyzing of Plant CommunitiespcorgoNo ratings yet
- Revision of The Genus Murunducaris Copepoda HarpacDocument22 pagesRevision of The Genus Murunducaris Copepoda HarpacpcorgoNo ratings yet
- Pnas 1804388115Document6 pagesPnas 1804388115pcorgoNo ratings yet
- Canuellidae (Copepoda, Harpacticoida) From The Bohai Sea, ChinaDocument37 pagesCanuellidae (Copepoda, Harpacticoida) From The Bohai Sea, ChinapcorgoNo ratings yet
- Chatterjee Et Al 2022 - Zootaxa - Ciliates Oxygen Minimum ZoneDocument9 pagesChatterjee Et Al 2022 - Zootaxa - Ciliates Oxygen Minimum ZonepcorgoNo ratings yet
- Chapter 6: How To Avoid Accumulating Risk in Simple ComparisonsDocument9 pagesChapter 6: How To Avoid Accumulating Risk in Simple ComparisonspcorgoNo ratings yet
- Chapter 4: How Much Evidence Is Enough?Document7 pagesChapter 4: How Much Evidence Is Enough?pcorgoNo ratings yet
- Chapter 2 - Flow Charts and Scientific QuestionsDocument9 pagesChapter 2 - Flow Charts and Scientific QuestionspcorgoNo ratings yet
- Chapter 5: When Highly Improbable Means Very LikelyDocument11 pagesChapter 5: When Highly Improbable Means Very LikelypcorgoNo ratings yet
- Archeolourinia Shermani A New Genus and Species ofDocument8 pagesArcheolourinia Shermani A New Genus and Species ofpcorgoNo ratings yet
- A New Species of Parameiropsis Becker 1974 CopepodDocument12 pagesA New Species of Parameiropsis Becker 1974 CopepodpcorgoNo ratings yet
- Uncertainty Analysis PDFDocument17 pagesUncertainty Analysis PDFYazeed HamadNo ratings yet
- Tax Avoidance and Evasion As A Factor Influencing Creative Accounting Practice' Among Companies in KenyaDocument8 pagesTax Avoidance and Evasion As A Factor Influencing Creative Accounting Practice' Among Companies in KenyaCharles Guandaru KamauNo ratings yet
- Method Development and Validation of Afatinib in Bulk and Pharmaceutical Dosage Form by Uvspectroscopic MethodDocument7 pagesMethod Development and Validation of Afatinib in Bulk and Pharmaceutical Dosage Form by Uvspectroscopic MethodBaru Chandrasekhar RaoNo ratings yet
- Active Learning Task 12Document8 pagesActive Learning Task 12haptyNo ratings yet
- bt21R0716 16 11 09rahulDocument35 pagesbt21R0716 16 11 09rahulsreekar56No ratings yet
- Examples On Linear Combinations of Normal VariablesDocument1 pageExamples On Linear Combinations of Normal VariablesboNo ratings yet
- Normal Dist and CIDocument3 pagesNormal Dist and CINimra AzherNo ratings yet
- Lec 21Document14 pagesLec 21deepanshuNo ratings yet
- Statistical Quality ControlDocument82 pagesStatistical Quality ControlShahmirBalochNo ratings yet
- Attitudes Toward Career CounselingDocument9 pagesAttitudes Toward Career CounselingKuSya KuYieNo ratings yet
- Street SweepersDocument10 pagesStreet SweepersPriyanka PatilNo ratings yet
- Applied Design of Experiments and Taguchi Methods 1Document371 pagesApplied Design of Experiments and Taguchi Methods 1Ammad NadeemNo ratings yet
- Uncertainty of Measurements Part II Other Than Compliance Testing PDFDocument6 pagesUncertainty of Measurements Part II Other Than Compliance Testing PDFParkhomyukNo ratings yet
- Control - Statistical Process Control SPCDocument22 pagesControl - Statistical Process Control SPCHalimNo ratings yet
- Managing For Quality and Performance Excellence 10th Edition Evans Solutions Manual DownloadDocument43 pagesManaging For Quality and Performance Excellence 10th Edition Evans Solutions Manual DownloadZackary Ferguson100% (21)
- Random Offset CMOS IC Design CU Lecture Art Zirger PDFDocument46 pagesRandom Offset CMOS IC Design CU Lecture Art Zirger PDFgr8minds4allNo ratings yet
- Activity 1 (Activity Guide)Document3 pagesActivity 1 (Activity Guide)Ronel AlbanNo ratings yet
- HTCI SolutionsDocument7 pagesHTCI Solutionsleftpaw123No ratings yet
- Measures of DispersionDocument6 pagesMeasures of DispersionAri GaryanNo ratings yet
- ERIDocument16 pagesERIJosé Manuel García MartínNo ratings yet
- Design of Experiments (SS)Document4 pagesDesign of Experiments (SS)Sudipta SarangiNo ratings yet
- 3 BIOMETRY For ABG-730Document18 pages3 BIOMETRY For ABG-730Shahzad akramNo ratings yet
- WWC Dreambox 121013Document13 pagesWWC Dreambox 121013api-299398831No ratings yet
- Tests of SignificanceDocument40 pagesTests of SignificanceRahul Goel100% (1)
- 5479 29278 2 PBDocument10 pages5479 29278 2 PBAndre CoelhoNo ratings yet
- BTI Induced DispersionDocument6 pagesBTI Induced DispersionrakeshshenoyNo ratings yet
- Green Belt Certification SyllabusDocument4 pagesGreen Belt Certification SyllabusNeelam SamdaniNo ratings yet