You might also like
- Clean Architecture A Craftsmans Guide To PDFDocument7 pagesClean Architecture A Craftsmans Guide To PDFMelesio Roldan20% (10)
- Iec 61000-2-5-2017 TR PDFDocument150 pagesIec 61000-2-5-2017 TR PDFMehdi MakarovNo ratings yet
- A Decision Making MCQDocument18 pagesA Decision Making MCQcik siti89% (9)
- Sign Language Recognition Using Machine Learning A SurveyDocument5 pagesSign Language Recognition Using Machine Learning A SurveyInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- CoderByte Challange 7 Soucre CodeDocument1 pageCoderByte Challange 7 Soucre Codedejan_032No ratings yet
- DamathDocument3 pagesDamathLeigh Yah100% (1)
- Continuous Arabic Sign Language Recognition in User Dependent ModeDocument9 pagesContinuous Arabic Sign Language Recognition in User Dependent ModeTaipe Lopez AndyNo ratings yet
- Hand Gesture RecognitionDocument10 pagesHand Gesture RecognitionJaseel CNo ratings yet
- Recognition of Static Hand Gestures of Alphabet in Bangla Sign LanguageDocument7 pagesRecognition of Static Hand Gestures of Alphabet in Bangla Sign LanguageInternational Organization of Scientific Research (IOSR)No ratings yet
- Multi-Sign Language Glove Based Hand Talking SysteDocument12 pagesMulti-Sign Language Glove Based Hand Talking SysteAland AkoNo ratings yet
- Real-Time Arabic Sign Language (Arsl) Recognition: January 2012Document6 pagesReal-Time Arabic Sign Language (Arsl) Recognition: January 2012Abdurrahman AlmhjeriNo ratings yet
- Final Year Project ProposalDocument13 pagesFinal Year Project ProposalAdrian ZayasNo ratings yet
- Static Sign Language Recognition Using Deep LearningDocument9 pagesStatic Sign Language Recognition Using Deep LearningMelissa MokNo ratings yet
- Sign Language TranslationDocument23 pagesSign Language Translation陳子彤No ratings yet
- Selfie Video Based Continuous Indian Sign Language Recognition System PDFDocument11 pagesSelfie Video Based Continuous Indian Sign Language Recognition System PDFShrusti SavantNo ratings yet
- Speaking System For Mute PeopleDocument4 pagesSpeaking System For Mute PeopleInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Neural Network Based Static Hand Gesture RecognitionDocument5 pagesNeural Network Based Static Hand Gesture RecognitionInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Machine Learning and Ai (Eaepcpc09) : Project: Sign Language RecognitionDocument20 pagesMachine Learning and Ai (Eaepcpc09) : Project: Sign Language RecognitionPragyadityaNo ratings yet
- Design and Implementation of A Convolutional Neural Network On An Edge Computing Smartphone For Human Activity RecognitionDocument12 pagesDesign and Implementation of A Convolutional Neural Network On An Edge Computing Smartphone For Human Activity Recognitionsdjnsj jnjcdejnewNo ratings yet
- Assistive SIGN LANGUAGE Converter For DEAF AND DUMBDocument6 pagesAssistive SIGN LANGUAGE Converter For DEAF AND DUMBGurudev YankanchiNo ratings yet
- Sign Language Recognition Using Deep Learning Through LSTM and CNNDocument5 pagesSign Language Recognition Using Deep Learning Through LSTM and CNNVictorNo ratings yet
- Easychair Preprint: Adnene Noughreche, Sabri Boulouma and Mohammed BenbaghdadDocument8 pagesEasychair Preprint: Adnene Noughreche, Sabri Boulouma and Mohammed BenbaghdadTran Quang Thai B1708908No ratings yet
- A Real-Time ASL Recognition System Using Leap Motion SensorsDocument4 pagesA Real-Time ASL Recognition System Using Leap Motion SensorsMuhammad SulemanNo ratings yet
- 1 SPDocument8 pages1 SPRishi AstasachindraNo ratings yet
- Ijet V3i3p27Document4 pagesIjet V3i3p27International Journal of Engineering and TechniquesNo ratings yet
- Sign Language DetectionDocument5 pagesSign Language DetectionPranay ParekarNo ratings yet
- Speech Recognition Using Neural Networks: A Review: Dhavale Dhanashri, S.B. DhondeDocument4 pagesSpeech Recognition Using Neural Networks: A Review: Dhavale Dhanashri, S.B. Dhondextfr2215hNo ratings yet
- "Asl To Text Conversion": Bachelor of TechnologyDocument15 pages"Asl To Text Conversion": Bachelor of TechnologyGurudev YankanchiNo ratings yet
- Development of A Wearable Device For Sign Language RecognitionDocument9 pagesDevelopment of A Wearable Device For Sign Language RecognitionScott MelgarejoNo ratings yet
- A Model For Real Time Sign Language Recognition SystemDocument7 pagesA Model For Real Time Sign Language Recognition Systemeditor_ijarcsseNo ratings yet
- SynopsisDocument4 pagesSynopsisZishan KhanNo ratings yet
- SLC Doc Final FinalDocument50 pagesSLC Doc Final FinalSowmya LakshmiNo ratings yet
- 2017project PaperDocument5 pages2017project PaperÂjáyNo ratings yet
- SIGNLANGUAGE PPTDocument15 pagesSIGNLANGUAGE PPTvishnuram1436No ratings yet
- Apjmr 2014 2 114 PDFDocument5 pagesApjmr 2014 2 114 PDFKelly De Leon TuliaoNo ratings yet
- Sign Language To Text-Speech Translator Using Machine LearningDocument5 pagesSign Language To Text-Speech Translator Using Machine LearningWARSE JournalsNo ratings yet
- Research 19Document8 pagesResearch 19Deepak SubramaniamNo ratings yet
- Literature ReviewDocument12 pagesLiterature ReviewAlexander CalimlimNo ratings yet
- Sign Language Recognition SystemDocument7 pagesSign Language Recognition SystemIJRASETPublicationsNo ratings yet
- Using Vibrotactile Communication To AssiDocument2 pagesUsing Vibrotactile Communication To AssiAngel Pena GalvãoNo ratings yet
- Realtime Sign Language Gesture Word Recognition From Video Seque 2018Document10 pagesRealtime Sign Language Gesture Word Recognition From Video Seque 2018Ridwan EinsteinsNo ratings yet
- A Wearable Computer Based American Sign Language RecognizerDocument8 pagesA Wearable Computer Based American Sign Language RecognizerJuan Sebastian CifuentesNo ratings yet
- Paper 9004Document4 pagesPaper 9004IJARSCT JournalNo ratings yet
- Indian Sign Language Converter System Using An Android App.: Pranali Loke Juilee Paranjpe Sayli BhabalDocument4 pagesIndian Sign Language Converter System Using An Android App.: Pranali Loke Juilee Paranjpe Sayli BhabalGurudev YankanchiNo ratings yet
- Recognition System of Indonesia Sign Language Based On Sensor and Artificial Neural NetworkDocument7 pagesRecognition System of Indonesia Sign Language Based On Sensor and Artificial Neural NetworkXavierNo ratings yet
- A Survey Paper On Sign Language RecognitionDocument6 pagesA Survey Paper On Sign Language RecognitionIJRASETPublicationsNo ratings yet
- Human Activity RecoDocument17 pagesHuman Activity Reconeeraj12121No ratings yet
- Alphabet Signs Recognition Using Pixels-Based AnalysisDocument8 pagesAlphabet Signs Recognition Using Pixels-Based AnalysisGDC Totakan MalakandNo ratings yet
- Final Chinese LeapMotion A Chinese Sign Language Recognition System Using Leap MotionDocument6 pagesFinal Chinese LeapMotion A Chinese Sign Language Recognition System Using Leap MotionKhushal DasNo ratings yet
- Application of Template Matching Algorithm For Dynamic Gesture Recognition of American Sign Language Finger Spelling and Hand GestureDocument5 pagesApplication of Template Matching Algorithm For Dynamic Gesture Recognition of American Sign Language Finger Spelling and Hand GestureAsia Pacific Journal of Multidisciplinary ResearchNo ratings yet
- 11 IX September 2023Document8 pages11 IX September 2023Pratham DubeyNo ratings yet
- Real Time Sign Language Recognition System For Hearing and Speech Impaired PeopleDocument9 pagesReal Time Sign Language Recognition System For Hearing and Speech Impaired PeopleIJRASETPublicationsNo ratings yet
- Implementation of Hand Gesture Recognition System To Aid Deaf-Dumb PeopleDocument15 pagesImplementation of Hand Gesture Recognition System To Aid Deaf-Dumb PeopleSanjay ShelarNo ratings yet
- Training ANFIS Structure With Modified PSO Algorithm: V.Seydi Ghomsheh, M. Aliyari Shoorehdeli, M. TeshnehlabDocument6 pagesTraining ANFIS Structure With Modified PSO Algorithm: V.Seydi Ghomsheh, M. Aliyari Shoorehdeli, M. TeshnehlabRavi ThejaNo ratings yet
- Wearable Sensor Data Based Human Activity Recognition Using Machine Learning A New ApproachDocument6 pagesWearable Sensor Data Based Human Activity Recognition Using Machine Learning A New ApproachK. AndriantoNo ratings yet
- LS 1Document10 pagesLS 1Ms. Divya KonikkaraNo ratings yet
- Ethiopian Sign Language Recognition Using Artificial Neural NetworkDocument6 pagesEthiopian Sign Language Recognition Using Artificial Neural NetworkJaniNo ratings yet
- A Review of Sign Language Classification TechniquesDocument7 pagesA Review of Sign Language Classification TechniquesBadri RanjanNo ratings yet
- Cabreraetal. 2012 Glove BasedGestureRecognitionSystemDocument8 pagesCabreraetal. 2012 Glove BasedGestureRecognitionSystemJaseel CNo ratings yet
- A Communication Aid System For Deaf and Mute Using Visual and Vibrotactile FeedbackDocument7 pagesA Communication Aid System For Deaf and Mute Using Visual and Vibrotactile FeedbackImamul Ahsan ,144433No ratings yet
- Glide A Communication Aid For Deaf-MuteDocument4 pagesGlide A Communication Aid For Deaf-MuteInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Sign Language Recognition Using Sensor Gloves: December 2002Document5 pagesSign Language Recognition Using Sensor Gloves: December 2002zara KhanNo ratings yet
- Conversion of Sign Language Video To Text andDocument8 pagesConversion of Sign Language Video To Text andIJRASETPublicationsNo ratings yet
- Improve The Recognition Accuracy of Sign Language GestureDocument7 pagesImprove The Recognition Accuracy of Sign Language GestureIJRASETPublicationsNo ratings yet
- Teaching Assistant Tools For NL To Fol Conversion: Isidoros Perikos, Foteini Grivokostopoulou and Ioannis HatzilygeroudisDocument8 pagesTeaching Assistant Tools For NL To Fol Conversion: Isidoros Perikos, Foteini Grivokostopoulou and Ioannis HatzilygeroudisAbdurrahman AlmhjeriNo ratings yet
- Decision 10 MCQDocument2 pagesDecision 10 MCQAbdurrahman AlmhjeriNo ratings yet
- MIS MCQDocument5 pagesMIS MCQJermaineLamboso100% (1)
- Case Studies of Expert System & Research Aspects in Artificial IntelligenceDocument6 pagesCase Studies of Expert System & Research Aspects in Artificial IntelligenceAbdurrahman AlmhjeriNo ratings yet
- Methodology For Developing A Speech Into Sign Language Translation System in A New Semantic DomainDocument11 pagesMethodology For Developing A Speech Into Sign Language Translation System in A New Semantic DomainAnjiNo ratings yet
- Linguistic Modelling and Language-Processing Technologies For Avatar-Based Sign Language PresentationDocument18 pagesLinguistic Modelling and Language-Processing Technologies For Avatar-Based Sign Language PresentationAbdurrahman AlmhjeriNo ratings yet
- Hands To Hands EnglishDocument12 pagesHands To Hands EnglishAbdurrahman AlmhjeriNo ratings yet
- An Avatar Based Translation System From Arabic Speech To Arabic Sign Language For Deaf PeopleDocument8 pagesAn Avatar Based Translation System From Arabic Speech To Arabic Sign Language For Deaf PeopleAbdurrahman AlmhjeriNo ratings yet
- 1 s2.0 S1877050922000485 MainDocument7 pages1 s2.0 S1877050922000485 MainAbdurrahman AlmhjeriNo ratings yet
- Hamnosys2Sigml: Translating Hamnosys Into Sigml: Carolina Neves, Luisa Coheur, Hugo NicolauDocument5 pagesHamnosys2Sigml: Translating Hamnosys Into Sigml: Carolina Neves, Luisa Coheur, Hugo NicolauAbdurrahman AlmhjeriNo ratings yet
- Admin, Journal Manager, JMS-1 (Naeem)Document6 pagesAdmin, Journal Manager, JMS-1 (Naeem)Abdurrahman AlmhjeriNo ratings yet
- Karsl: Arabic Sign Language Database: Ala Addin I. Sidig, Hamzah Luqman, Sabri Mahmoud, and Mohamed MohandesDocument19 pagesKarsl: Arabic Sign Language Database: Ala Addin I. Sidig, Hamzah Luqman, Sabri Mahmoud, and Mohamed MohandesAbdurrahman AlmhjeriNo ratings yet
- With SQL Server With KeyDocument14 pagesWith SQL Server With KeyAbdurrahman AlmhjeriNo ratings yet
- Developments in Business Simulation & Experiential Exercises, Volume 15, 1988Document6 pagesDevelopments in Business Simulation & Experiential Exercises, Volume 15, 1988Abdurrahman AlmhjeriNo ratings yet
- An Avatar Based Approach For Automatically Interpreting A Sign Language NotationDocument4 pagesAn Avatar Based Approach For Automatically Interpreting A Sign Language NotationAbdurrahman AlmhjeriNo ratings yet
- Detecting SQL Injection Attacks Based On Text Analysis: Lu Yu, Senlin Luo, Limin PanDocument7 pagesDetecting SQL Injection Attacks Based On Text Analysis: Lu Yu, Senlin Luo, Limin PanPramono PramonoNo ratings yet
- Sample - China Digital Freight Forwarding Maeket (2020 - 2025) - Mordor IntelligenceDocument47 pagesSample - China Digital Freight Forwarding Maeket (2020 - 2025) - Mordor IntelligenceredejavoeNo ratings yet
- Ball Mill FLSDocument15 pagesBall Mill FLSMudassir RafiqNo ratings yet
- Induction Cooker PDFDocument2 pagesInduction Cooker PDFthienhayenNo ratings yet
- Vs 2400 CDDocument49 pagesVs 2400 CDtatfutureNo ratings yet
- Ijsrp p7967 1Document5 pagesIjsrp p7967 1olumideNo ratings yet
- MyPhp MaterialsDocument233 pagesMyPhp MaterialsJai DanyaNo ratings yet
- Arduino Programming NotebookDocument37 pagesArduino Programming NotebooktihomihoNo ratings yet
- ICT ASD QuestionnaireDocument5 pagesICT ASD QuestionnaireMark ReyesNo ratings yet
- Satellite Interception SolutionsDocument8 pagesSatellite Interception Solutionsalt.fm-fo4iecpuNo ratings yet
- Lab 2 - Isentropic FlowsDocument16 pagesLab 2 - Isentropic FlowsabhijeetNo ratings yet
- ICJ24 Judging Criteria 253f260eb676Document4 pagesICJ24 Judging Criteria 253f260eb676Nguyễn Thu TrangNo ratings yet
- SQLServerGeeks Magazine June 2021Document45 pagesSQLServerGeeks Magazine June 2021rexpanNo ratings yet
- Chapter 12Document12 pagesChapter 12Mut4nt TVNo ratings yet
- Ops MGT SaumuDocument8 pagesOps MGT SaumuSaumu SuleimanNo ratings yet
- Format HIRADocument1 pageFormat HIRAAndi Tri Octavian75% (4)
- Java Q & ADocument57 pagesJava Q & ARAJESH PNo ratings yet
- Workforce Ds 1630 BrochureDocument2 pagesWorkforce Ds 1630 BrochureJoseNo ratings yet
- Design Sprint Methods: Playbook For Start Ups and DesignersDocument46 pagesDesign Sprint Methods: Playbook For Start Ups and DesignersRodrigo NobreNo ratings yet
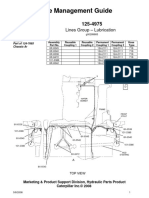
- Hose Management Guide: SN: 4AR Lines Group - LubricationDocument52 pagesHose Management Guide: SN: 4AR Lines Group - LubricationNY DanyNo ratings yet
- Client Satisfaction Surveys: BackgroundDocument9 pagesClient Satisfaction Surveys: BackgroundsumitNo ratings yet
- Optisonic 3400 Optisonic 3400 Optisonic 3400 Optisonic 3400Document52 pagesOptisonic 3400 Optisonic 3400 Optisonic 3400 Optisonic 3400Didik WahyudiNo ratings yet
- High-Speed Permanent Magnet Electrical Machines - Applications, Key Issues and ChallengesDocument11 pagesHigh-Speed Permanent Magnet Electrical Machines - Applications, Key Issues and ChallengesVidhya M PNo ratings yet
- Mathematics: Quarter 2 - Module 4: Algebraic ExpressionsDocument23 pagesMathematics: Quarter 2 - Module 4: Algebraic ExpressionsMa.Cristine Joy Inocentes50% (2)
- C84IE007EN A PDL Haze 3001Document5 pagesC84IE007EN A PDL Haze 3001Mauricio CruzNo ratings yet
- High Performance ALU Design Using Energy Efficient Borrow Select SubtractorDocument65 pagesHigh Performance ALU Design Using Energy Efficient Borrow Select SubtractorKarthiga MuruganNo ratings yet