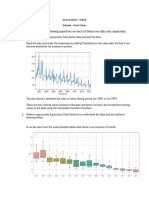
You might also like
- Business Report Project Machine Learning Rupesh Kumar DSBA-A5-21C-2021Document77 pagesBusiness Report Project Machine Learning Rupesh Kumar DSBA-A5-21C-2021Rupesh GaurNo ratings yet
- Time Series Forecasting Project ReportDocument62 pagesTime Series Forecasting Project Reportpradeep100% (3)
- Project - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)Document15 pagesProject - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)guillermo cocoNo ratings yet
- QUIZ Week 2 CART Practice PDFDocument10 pagesQUIZ Week 2 CART Practice PDFNagarajan ThandayuthamNo ratings yet
- Business ReportDocument12 pagesBusiness Reportcrispin anthonyNo ratings yet
- MRA-Milestone 1 - Report - UMESHKUMARHASIJADocument22 pagesMRA-Milestone 1 - Report - UMESHKUMARHASIJAumesh hasija100% (1)
- SMDM ProjectDocument22 pagesSMDM ProjectNandini GuptaNo ratings yet
- Marketing & Retail Analytics - Report - Part ADocument18 pagesMarketing & Retail Analytics - Report - Part AAshish Agrawal100% (2)
- Business Report TSF - Rose DataSetDocument52 pagesBusiness Report TSF - Rose DataSetCharit Sharma100% (2)
- Assignment Report - Data MiningDocument24 pagesAssignment Report - Data MiningRahulNo ratings yet
- Machine Learning Project - HTML PDFDocument72 pagesMachine Learning Project - HTML PDFRaveena100% (3)
- Project ReportDocument36 pagesProject ReportAkshaya Kennedy100% (3)
- WSMA SharkTankDocument33 pagesWSMA SharkTankPradeep RamadasNo ratings yet
- Southwest Airlines PresentationDocument35 pagesSouthwest Airlines Presentationmterry04100% (1)
- REport Time SeriesDocument57 pagesREport Time SeriesAkshaya Kennedy100% (2)
- LifiDocument16 pagesLifiAnkita Mishra100% (1)
- Business Report - Predictive Modelling 23.01.2022Document56 pagesBusiness Report - Predictive Modelling 23.01.2022Divjyot100% (1)
- Time Series Forecasting - Rose - Buisness ReportDocument69 pagesTime Series Forecasting - Rose - Buisness ReportPriyanka Patil100% (1)
- State Wise Health Income Clustering 18th December 2021 PDFDocument29 pagesState Wise Health Income Clustering 18th December 2021 PDFAnkita Mishra100% (1)
- Girish Chadha - 29th December 2022Document35 pagesGirish Chadha - 29th December 2022Girish Chadha100% (3)
- NIrupam Agarwal Business Report-MLDocument23 pagesNIrupam Agarwal Business Report-MLNirupam AgarwalNo ratings yet
- Insurance Car Claim Project Data VisualisationDocument12 pagesInsurance Car Claim Project Data VisualisationPurva Soni50% (2)
- Answer Book - Rose WinesDocument11 pagesAnswer Book - Rose WinesAshish Agrawal100% (1)
- Time-series-Forecasting Time Series Forecasting Jupyter Code - Ipynb at Main Chetandudhane Time-series-Forecasting GitHubDocument162 pagesTime-series-Forecasting Time Series Forecasting Jupyter Code - Ipynb at Main Chetandudhane Time-series-Forecasting GitHubArun Kumar100% (1)
- Business Report: Predictive ModellingDocument37 pagesBusiness Report: Predictive Modellinghepzi selvam100% (1)
- Business Report: Advanced Statistics Module Project IDocument5 pagesBusiness Report: Advanced Statistics Module Project IPrasad Mohan100% (1)
- PM - ExtendedProject - Business ReportDocument35 pagesPM - ExtendedProject - Business ReportROHINI ROKDE100% (2)
- Anshul Dyundi Predictive Modelling Alternate Project July 2022Document11 pagesAnshul Dyundi Predictive Modelling Alternate Project July 2022Anshul DyundiNo ratings yet
- MRA Project - Shehroz KhanDocument19 pagesMRA Project - Shehroz KhanShehroz Khan67% (3)
- Business Report Data MiningDocument29 pagesBusiness Report Data Mininghepzi selvamNo ratings yet
- MRA - Project - Puvya - RaviDocument46 pagesMRA - Project - Puvya - RaviPuvya Ravi100% (2)
- Ritesh Tandon - Time Series ForecastingDocument32 pagesRitesh Tandon - Time Series ForecastingRitesh Tandon100% (2)
- DM Gopala Satish Kumar Business Report G8 DSBADocument26 pagesDM Gopala Satish Kumar Business Report G8 DSBASatish Kumar100% (2)
- Time Series Rose Shehroz ArfeenDocument42 pagesTime Series Rose Shehroz ArfeenShehroz Khan100% (1)
- SMDM Project Report: Submitted By: Kratika VijayvergiyaDocument15 pagesSMDM Project Report: Submitted By: Kratika VijayvergiyaKratika Vijayvergiya100% (1)
- Linear RegressionDocument15 pagesLinear RegressionAnil Bera67% (3)
- Machine Learning Business Report - Compress (AutoRecovered)Document69 pagesMachine Learning Business Report - Compress (AutoRecovered)Deepanshu Parashar100% (2)
- As ProjectDocument39 pagesAs ProjectAnshul Mendhekar100% (1)
- Data Mining Case Study PDFDocument21 pagesData Mining Case Study PDFDeepali Kumar100% (1)
- Shoe SalesDocument105 pagesShoe SalesRemyaRS100% (3)
- Frank Lloyd WrightDocument66 pagesFrank Lloyd Wrightvikesh100% (1)
- Final Project ML Nikita Chaturvedi 03.10.2021 Text AnalyticsDocument32 pagesFinal Project ML Nikita Chaturvedi 03.10.2021 Text AnalyticsNikita ChaturvediNo ratings yet
- Education - Post 12th Standard - CSVDocument11 pagesEducation - Post 12th Standard - CSVRuhee's KitchenNo ratings yet
- Predictive Model: Submitted byDocument27 pagesPredictive Model: Submitted byAnkita Mishra100% (1)
- Great Learning: SMDM Final AssignmentDocument16 pagesGreat Learning: SMDM Final AssignmentAditya Hajare100% (1)
- Time Series ProjectDocument45 pagesTime Series ProjectKhursheed Khan100% (3)
- Palash Bhai - Machine Learning AssignmentDocument18 pagesPalash Bhai - Machine Learning AssignmentPalashKulshrestha100% (1)
- Machine Learning SolutionDocument12 pagesMachine Learning Solutionprabu2125100% (1)
- Project Time Series ForecastingDocument53 pagesProject Time Series Forecastingharish kumar100% (1)
- Business Report Project - Sheetal - SMDMDocument20 pagesBusiness Report Project - Sheetal - SMDMSheetal Mayanale100% (1)
- Statisitics Project 6Document48 pagesStatisitics Project 6AMAN PRAKASH100% (2)
- Machine Learning Project: Raghul HarishDocument46 pagesMachine Learning Project: Raghul HarishARUNKUMAR S100% (1)
- Capstone Project SubmissionDocument31 pagesCapstone Project Submissionguruss604684No ratings yet
- 004 Annexure D Job Safety SAnalysis JSADocument3 pages004 Annexure D Job Safety SAnalysis JSAAvoor Khan75% (4)
- Project Predictive Modeling PDFDocument58 pagesProject Predictive Modeling PDFAYUSH AWASTHINo ratings yet
- Clustering Analysis: Prepared by Muralidharan NDocument16 pagesClustering Analysis: Prepared by Muralidharan Nrakesh sandhyapoguNo ratings yet
- LDA KNN LogisticDocument29 pagesLDA KNN Logisticshruti gujar100% (1)
- Data Mining Project - 27.06.2021Document6 pagesData Mining Project - 27.06.2021vansh guptaNo ratings yet
- Data Mining Business ReportDocument38 pagesData Mining Business ReportThaku SinghNo ratings yet
- Sunira - Predictive ModelingDocument65 pagesSunira - Predictive ModelingDeepanshu ParasharNo ratings yet
- Mini Project Time SeriesDocument55 pagesMini Project Time Seriessumit kumarNo ratings yet
- Ashish BR 19-12-21Document65 pagesAshish BR 19-12-21Ashish Pavan Kumar KNo ratings yet
- VijayalakshmiDocument17 pagesVijayalakshmiVijayalakshmi PalaniappanNo ratings yet
- Weed Eater 96112011602 User ManualDocument2 pagesWeed Eater 96112011602 User ManualShouzab AbbasNo ratings yet
- Dreams and PhilosophyDocument2 pagesDreams and PhilosophyМай ТриNo ratings yet
- History of Electronics: Year Person WorksDocument2 pagesHistory of Electronics: Year Person WorksRoy AngelesNo ratings yet
- Nursery Raising of Vegetables CropsDocument7 pagesNursery Raising of Vegetables Cropsronalit malintad100% (2)
- Multilink N Primer A/B: Instructions For UseDocument20 pagesMultilink N Primer A/B: Instructions For UseStephani CastilloNo ratings yet
- Digital Axis Control HNC100 Component Series 2XDocument16 pagesDigital Axis Control HNC100 Component Series 2XHoang Duy100% (1)
- Infectious Coryza: Presenter: Dr. Bikash PuriDocument15 pagesInfectious Coryza: Presenter: Dr. Bikash Puripracholi lampNo ratings yet
- LTO Application FormDocument7 pagesLTO Application Formemma alingasa67% (3)
- Isotope Practice QuestionsDocument5 pagesIsotope Practice QuestionsocNo ratings yet
- World War 1 NotesDocument49 pagesWorld War 1 NotesMohammed YasserNo ratings yet
- Informational EssayDocument4 pagesInformational Essayapi-241238726No ratings yet
- Operating Instructions: N - R 472C en 05.12Document42 pagesOperating Instructions: N - R 472C en 05.12Long HuynhNo ratings yet
- Wi-Fi Fingerprinting-Based Floor Detection Using Adaptive Scaling and Weighted Autoencoder Extreme Learning MachineDocument12 pagesWi-Fi Fingerprinting-Based Floor Detection Using Adaptive Scaling and Weighted Autoencoder Extreme Learning MachineCSIT iaesprimeNo ratings yet
- DOWSIL™ 33 Additive: Features & BenefitsDocument3 pagesDOWSIL™ 33 Additive: Features & BenefitsNiranjan GoriwaleNo ratings yet
- Masjid Option2 PDFDocument2 pagesMasjid Option2 PDFUmerNo ratings yet
- Transmission Mercedes LF 408 G&NBSP (309055)Document1 pageTransmission Mercedes LF 408 G&NBSP (309055)jehklaassenNo ratings yet
- Design of Solar Powered Drainage Cleaning MachineDocument56 pagesDesign of Solar Powered Drainage Cleaning MachineNazeema TTNo ratings yet
- Pachawo Kudakwashe S. KAG112-1Document15 pagesPachawo Kudakwashe S. KAG112-1Ashley Tanya GilbertNo ratings yet
- Fraser MapDocument1 pageFraser MapbackdoorburpNo ratings yet
- Rotary History 1700-1900Document7 pagesRotary History 1700-1900Nigel RamosNo ratings yet
- Abdul Rauf CV UpdatedDocument4 pagesAbdul Rauf CV Updatedwaqasfarooq75_396423No ratings yet
- Content Area Reading Teaching and Learning For College and Career Readiness 2nd Edition Mclaughlin Solutions ManualDocument25 pagesContent Area Reading Teaching and Learning For College and Career Readiness 2nd Edition Mclaughlin Solutions ManualEugeneMurraywnmbNo ratings yet
- CaseStudiesStatistics 2009Document10 pagesCaseStudiesStatistics 2009sachy24No ratings yet
- Modelling and Analysis of Induction Motor Using LabviewDocument11 pagesModelling and Analysis of Induction Motor Using LabviewNituNo ratings yet
- Sport - Cardiology Course - Program PDFDocument4 pagesSport - Cardiology Course - Program PDFNico IonaşcuNo ratings yet
- Static and Dynamic BalancingDocument13 pagesStatic and Dynamic BalancingTuanbk NguyenNo ratings yet
- Desalination +GF+Document31 pagesDesalination +GF+ahumadaliraNo ratings yet