You might also like
- Malicious Url Detection Based On Machine LearningDocument52 pagesMalicious Url Detection Based On Machine Learningkruthi reddyNo ratings yet
- An Automated Framework For Real-Time Phishing URL Detection:, Raghav Kaul, Shahriar Badsha, Shamik SenguptaDocument7 pagesAn Automated Framework For Real-Time Phishing URL Detection:, Raghav Kaul, Shahriar Badsha, Shamik SenguptaKiran MudaliyarNo ratings yet
- Robust Ensemble Machine Learning Model For Filtering Phishing URLs Expandable Random Gradient Stacked Voting Classifier ERG-SVCDocument20 pagesRobust Ensemble Machine Learning Model For Filtering Phishing URLs Expandable Random Gradient Stacked Voting Classifier ERG-SVCNexgen TechnologyNo ratings yet
- Phishing URL Detection Using LSTM Based Ensemble Learning ApproachesDocument17 pagesPhishing URL Detection Using LSTM Based Ensemble Learning ApproachesAIRCC - IJCNCNo ratings yet
- 20mis0106 VL2023240102875 Pe003Document42 pages20mis0106 VL2023240102875 Pe003Kartik SoniNo ratings yet
- Detecting Phishing Websites Using Optimal Feature Selection and Neural Networks (OFS-NNDocument14 pagesDetecting Phishing Websites Using Optimal Feature Selection and Neural Networks (OFS-NNlikhithNo ratings yet
- EFFICIENT PREDICTION OF PHISHING WEBSITES USING MULTILAYER PERCEPTRON (MLP)Document12 pagesEFFICIENT PREDICTION OF PHISHING WEBSITES USING MULTILAYER PERCEPTRON (MLP)Abel DemelashNo ratings yet
- Fraudulent Website DetectionDocument3 pagesFraudulent Website DetectionInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Review: Phishing Detection Approaches: October 2019Document7 pagesReview: Phishing Detection Approaches: October 2019Monisha djNo ratings yet
- Deep learning and multidimensional features for fast phishing website detectionDocument14 pagesDeep learning and multidimensional features for fast phishing website detectionlikhithNo ratings yet
- Phishing Websites Classification Using Hybrid SVMDocument7 pagesPhishing Websites Classification Using Hybrid SVMMon Gabriel LagustanNo ratings yet
- Machine Learning Approach To Phishing Detection: Arvind Rekha Sura Jyoti Kini Kishan AthreyDocument7 pagesMachine Learning Approach To Phishing Detection: Arvind Rekha Sura Jyoti Kini Kishan AthreyRed NyNo ratings yet
- Detecting AI & Human-Crafted Phishing URLs in Real-Time With PhishHavenDocument19 pagesDetecting AI & Human-Crafted Phishing URLs in Real-Time With PhishHavenlikhithNo ratings yet
- Phishing Detection Using Heuristic BasedDocument6 pagesPhishing Detection Using Heuristic BasedArun PanikarNo ratings yet
- 11 V May 2023Document6 pages11 V May 2023swetha rNo ratings yet
- Detection of Phishing WebsiteDocument12 pagesDetection of Phishing WebsiteOm RautNo ratings yet
- Expert Systems With Applications: Ozgur Koray Sahingoz, Ebubekir Buber, Onder Demir, Banu DiriDocument13 pagesExpert Systems With Applications: Ozgur Koray Sahingoz, Ebubekir Buber, Onder Demir, Banu DiriSantosh KBNo ratings yet
- Paper 19-Malicious URL Detection Based On Machine LearningDocument6 pagesPaper 19-Malicious URL Detection Based On Machine LearningNguyễn Hà PhươngNo ratings yet
- Fin Irjmets1682919970Document5 pagesFin Irjmets1682919970swetha rNo ratings yet
- PUMMP: Phishing URL Detection Using Machine Learning With Monomorphic and Polymorphic Treatment of FeaturesDocument20 pagesPUMMP: Phishing URL Detection Using Machine Learning With Monomorphic and Polymorphic Treatment of FeaturesAIRCC - IJCNCNo ratings yet
- Detection of Malicious Websites Using Machine LearningDocument4 pagesDetection of Malicious Websites Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Detection of Phishing Websites Using Machine Learning: Specialusis Ugdymas / Special Education 2022 1Document7 pagesDetection of Phishing Websites Using Machine Learning: Specialusis Ugdymas / Special Education 2022 1cristo555625No ratings yet
- Based On URL Feature ExtractionDocument6 pagesBased On URL Feature ExtractionYusuf Mohammed KhanNo ratings yet
- Linear Support Vector Machine and Deep Learning Approaches For Cyber Security in The Edge of Big DataDocument9 pagesLinear Support Vector Machine and Deep Learning Approaches For Cyber Security in The Edge of Big DataInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Raika ShahLJdADocument8 pagesRaika ShahLJdAYashwanth B KNo ratings yet
- User Behaviour Based Phishing Websites Detection: November 2008Document9 pagesUser Behaviour Based Phishing Websites Detection: November 2008Onsa piarusNo ratings yet
- PHISHING WEBSITE DETECTION USING MACHINE LEARNING - COMPLETED (1) FullDocument73 pagesPHISHING WEBSITE DETECTION USING MACHINE LEARNING - COMPLETED (1) Fullpkaentertainment2905No ratings yet
- Kumar 2018Document6 pagesKumar 2018roliho3769No ratings yet
- Detecting Malicious Urls Using Lexical Analysis: (Msi - Mamun, Mahmad - Rathore, A.Habibi.L, Natalia, Ghorbani) @unb - CaDocument16 pagesDetecting Malicious Urls Using Lexical Analysis: (Msi - Mamun, Mahmad - Rathore, A.Habibi.L, Natalia, Ghorbani) @unb - Cadipankar mondalNo ratings yet
- ISAA Report PDFDocument24 pagesISAA Report PDFsparsh jainNo ratings yet
- Application of Malicious URL Detection in Data MiningDocument6 pagesApplication of Malicious URL Detection in Data MiningIJAFRCNo ratings yet
- Malicious Websites Classification Using Machine Learning Techniques A Survey PaperDocument7 pagesMalicious Websites Classification Using Machine Learning Techniques A Survey PaperIJRASETPublicationsNo ratings yet
- A Novel Method To Prevent Phishing by Using OCR Technology: Yunjia Wang Ishbel DuncanDocument5 pagesA Novel Method To Prevent Phishing by Using OCR Technology: Yunjia Wang Ishbel DuncanKiran MudaliyarNo ratings yet
- AlgorithmDocument7 pagesAlgorithmAgnes ChengNo ratings yet
- Paper 7AdvancesinEngineeringSoftwareDocument6 pagesPaper 7AdvancesinEngineeringSoftwaresimbaboi07No ratings yet
- Detecting Malicious Urls Using Machine Learning Techniques: A Comparative Literature ReviewDocument5 pagesDetecting Malicious Urls Using Machine Learning Techniques: A Comparative Literature ReviewNguyễn Hà PhươngNo ratings yet
- Intelligent Phishing Website Detection and Prevention System by Using Link Guard AlgorithmDocument9 pagesIntelligent Phishing Website Detection and Prevention System by Using Link Guard AlgorithmInternational Organization of Scientific Research (IOSR)No ratings yet
- IJCRT2106008Document6 pagesIJCRT2106008vssNo ratings yet
- A Novel Algorithm To Detect Phishing URLs - 2016Document5 pagesA Novel Algorithm To Detect Phishing URLs - 2016Frank VillaNo ratings yet
- Mahajan 2018 Ijca 918026Document3 pagesMahajan 2018 Ijca 918026swetha rNo ratings yet
- 1 s2.0 S0957417423016858 MainDocument13 pages1 s2.0 S0957417423016858 Mainrahmat setiadiNo ratings yet
- Detecting E-Banking Phishing WebsitesDocument12 pagesDetecting E-Banking Phishing WebsitesMuhammad Faraz SaleemNo ratings yet
- IEEEDocument12 pagesIEEEChintha LalithaNo ratings yet
- Classification of Phishing Website Using Hybrid Machine Learning TechniquesDocument6 pagesClassification of Phishing Website Using Hybrid Machine Learning TechniquesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Ajcse 192 22 20230207 V1Document5 pagesAjcse 192 22 20230207 V1BRNSS Publication Hub InfoNo ratings yet
- Detect Phishing Attacks OnlineDocument6 pagesDetect Phishing Attacks OnlineSai SrinivasNo ratings yet
- Journal Pone 0258361Document17 pagesJournal Pone 0258361Nguyễn Quốc AnNo ratings yet
- Phishing Website Detection Using Machine Learning AlgorithmsDocument4 pagesPhishing Website Detection Using Machine Learning AlgorithmsTrịnh Văn ThoạiNo ratings yet
- Review On Phishing Attack Detection Using Recurrent Neural NetworkDocument6 pagesReview On Phishing Attack Detection Using Recurrent Neural NetworkIJRASETPublicationsNo ratings yet
- Detection of Phishing AttackDocument46 pagesDetection of Phishing Attacksuresh mpNo ratings yet
- Phishing Detection Based On Machine Learning and Feature Selection MethodsDocument13 pagesPhishing Detection Based On Machine Learning and Feature Selection Methodsshresthabishal721No ratings yet
- An Ideal Approach For Detection and Prevention ofDocument11 pagesAn Ideal Approach For Detection and Prevention ofBhargavi YerramNo ratings yet
- Detection of PhishingDocument7 pagesDetection of Phishingpriya manasaNo ratings yet
- Safeguarding Your Data From Malicious URLs Using Machine LearningDocument7 pagesSafeguarding Your Data From Malicious URLs Using Machine LearningIJRASETPublicationsNo ratings yet
- Malicious Url DetectionDocument14 pagesMalicious Url DetectionSANKALP MUKIM 20BDS0128No ratings yet
- Dap Guang Xiang - 1458611671284 PDFDocument32 pagesDap Guang Xiang - 1458611671284 PDFCelex VargheseNo ratings yet
- Robust IP Spoof Control Mechanism Through Packet FiltersDocument6 pagesRobust IP Spoof Control Mechanism Through Packet Filterssurendiran123100% (1)
- Web Browser To Prevent Phishing and Sybil AttacksDocument4 pagesWeb Browser To Prevent Phishing and Sybil AttacksInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Anti-Phishing System Using LSTM and CNNDocument6 pagesAnti-Phishing System Using LSTM and CNNrahul dandonaNo ratings yet
- Motivación y Desempeño 1Document14 pagesMotivación y Desempeño 1Corporacion H21No ratings yet
- Costos Contabilidad 2023Document16 pagesCostos Contabilidad 2023Corporacion H21No ratings yet
- Gestión de Inventario 2021Document10 pagesGestión de Inventario 2021Corporacion H21No ratings yet
- The Role of Corporate Social ResponsibilityDocument20 pagesThe Role of Corporate Social ResponsibilityFahem IBKANo ratings yet
- A Comparative Study of The Inventory Management Tools of Textile Manufacturing FirmsDocument11 pagesA Comparative Study of The Inventory Management Tools of Textile Manufacturing FirmsAktaruzzaman MintuNo ratings yet
- Research On High Security of IP Tunnel in Virtual Private NetworkDocument6 pagesResearch On High Security of IP Tunnel in Virtual Private NetworkCorporacion H21No ratings yet
- Administración 1Document15 pagesAdministración 1Corporacion H21No ratings yet
- Market Research and The New Product Development PRDocument25 pagesMarket Research and The New Product Development PRCorporacion H21No ratings yet
- Enterprise Integration, Networking and Virtual CommunicationsDocument4 pagesEnterprise Integration, Networking and Virtual CommunicationsCorporacion H21No ratings yet
- A Novel Approach For Phishing Emails Real Time Classification Using K-Means AlgorithmDocument8 pagesA Novel Approach For Phishing Emails Real Time Classification Using K-Means AlgorithmCorporacion H21No ratings yet
- Yadav 2017Document13 pagesYadav 2017Corporacion H21No ratings yet
- Wren 2021Document13 pagesWren 2021Corporacion H21No ratings yet
- Huang Chino 2022Document13 pagesHuang Chino 2022Corporacion H21No ratings yet
- Nurse Practitioner Job Satisfaction: Looking For Successful OutcomesDocument12 pagesNurse Practitioner Job Satisfaction: Looking For Successful OutcomesCorporacion H21No ratings yet
- Forest Fire Disaster ManagementDocument50 pagesForest Fire Disaster ManagementCorporacion H21No ratings yet
- Forest Fire Disaster Management 2Document50 pagesForest Fire Disaster Management 2Corporacion H21No ratings yet
- A Novel Approach To Protect Against Phishing Attacks at Client Side Using Auto-Updated White-ListDocument11 pagesA Novel Approach To Protect Against Phishing Attacks at Client Side Using Auto-Updated White-ListCorporacion H21No ratings yet
- Cyber Risks in IoT SystemsDocument27 pagesCyber Risks in IoT SystemsCorporacion H21No ratings yet
- A Method To Measure The Efficiency of Phishing Emails Detection FeaturesDocument5 pagesA Method To Measure The Efficiency of Phishing Emails Detection FeaturesCorporacion H21No ratings yet
- Augmented Reality As A Teaching Tool in Higher EducationDocument9 pagesAugmented Reality As A Teaching Tool in Higher EducationCorporacion H21No ratings yet
- The Value of Personal Data in Iot: Industry Perspectives On Consumer Conceptions of ValueDocument11 pagesThe Value of Personal Data in Iot: Industry Perspectives On Consumer Conceptions of ValueCorporacion H21No ratings yet
- A Comparative Performance Evaluation of Content Based Spam and Malicious URL Detection in E-MailDocument6 pagesA Comparative Performance Evaluation of Content Based Spam and Malicious URL Detection in E-MailCorporacion H21No ratings yet
- 01 Antecedente Internacional 2020 ChinaDocument2 pages01 Antecedente Internacional 2020 ChinaCorporacion H21No ratings yet
- Factores Críticos de Éxito en El Comercio Digital de Las Pymes Exportadoras CostarricensesDocument16 pagesFactores Críticos de Éxito en El Comercio Digital de Las Pymes Exportadoras CostarricensesCorporacion H21No ratings yet
- Information Systems and Computer EngineeringDocument101 pagesInformation Systems and Computer EngineeringCorporacion H21No ratings yet
- 02 Antecedente Internacional 2020Document13 pages02 Antecedente Internacional 2020Corporacion H21No ratings yet
- Analysis of The Methodologies For Evaluation of E-Government PoliciesDocument12 pagesAnalysis of The Methodologies For Evaluation of E-Government PoliciesCorporacion H21No ratings yet
- Impact of IT Service Management Frameworks On The IT OrganizationDocument15 pagesImpact of IT Service Management Frameworks On The IT OrganizationCorporacion H21No ratings yet
- Information Technology Governance and Innovation Adoption in Varying Organizational ContextsDocument313 pagesInformation Technology Governance and Innovation Adoption in Varying Organizational ContextsCorporacion H21No ratings yet
- Week 4 Gen EconDocument10 pagesWeek 4 Gen EconGenner RazNo ratings yet
- Ringkasan LaguDocument4 pagesRingkasan LaguJoe PyNo ratings yet
- GKInvest Market ReviewDocument66 pagesGKInvest Market ReviewjhonxracNo ratings yet
- Laws of ThermocoupleDocument3 pagesLaws of ThermocoupleMourougapragash SubramanianNo ratings yet
- Phaseo Abl7 Abl8 Abl8rps24100Document9 pagesPhaseo Abl7 Abl8 Abl8rps24100Magda DiazNo ratings yet
- Final Annotated BibiliographyDocument4 pagesFinal Annotated Bibiliographyapi-491166748No ratings yet
- 3 - Content - Introduction To Java, JVM, JDK PDFDocument8 pages3 - Content - Introduction To Java, JVM, JDK PDFAnonymous zdY202lgZYNo ratings yet
- ACL GRC Risk Manager - Usage Guide V1.1Document28 pagesACL GRC Risk Manager - Usage Guide V1.1Rohit ShettyNo ratings yet
- Presepsi Khalayak Terhadap Program Acara Televise Reality Show "Jika Aku Menjadi" Di Trans TVDocument128 pagesPresepsi Khalayak Terhadap Program Acara Televise Reality Show "Jika Aku Menjadi" Di Trans TVAngga DianNo ratings yet
- Banu Maaruf of The LevantDocument6 pagesBanu Maaruf of The LevantMotiwala AbbasNo ratings yet
- Medicinal PlantDocument13 pagesMedicinal PlantNeelum iqbalNo ratings yet
- Fehniger Steve-Pump VibrationDocument35 pagesFehniger Steve-Pump VibrationSheikh Shoaib100% (1)
- One - Pager - SOGEVAC SV 320 BDocument2 pagesOne - Pager - SOGEVAC SV 320 BEOLOS COMPRESSORS LTDNo ratings yet
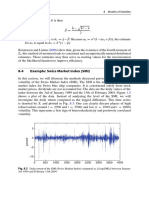
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- Hanwha Engineering & Construction - Brochure - enDocument48 pagesHanwha Engineering & Construction - Brochure - enAnthony GeorgeNo ratings yet
- SolarBright MaxBreeze Solar Roof Fan Brochure Web 1022Document4 pagesSolarBright MaxBreeze Solar Roof Fan Brochure Web 1022kewiso7811No ratings yet
- CBT QuestionsDocument20 pagesCBT Questionsmohammed amjad ali100% (1)
- 266 009-336Document327 pages266 009-336AlinaE.BarbuNo ratings yet
- Copy Resit APLC MiniAssignmentDocument5 pagesCopy Resit APLC MiniAssignmentChong yaoNo ratings yet
- Power Team PE55 ManualDocument13 pagesPower Team PE55 ManualTitanplyNo ratings yet
- XXCCCDocument17 pagesXXCCCwendra adi pradanaNo ratings yet
- 4 TheEulerianFunctions - 000 PDFDocument16 pages4 TheEulerianFunctions - 000 PDFShorouk Al- IssaNo ratings yet
- The Unbounded MindDocument190 pagesThe Unbounded MindXtof ErNo ratings yet
- Daily Assessment RecordDocument4 pagesDaily Assessment Recordapi-342236522100% (2)
- Ek Pardesi Mera Dil Le Gaya Lyrics English Translation - Lyrics GemDocument1 pageEk Pardesi Mera Dil Le Gaya Lyrics English Translation - Lyrics Gemmahsa.molaiepanahNo ratings yet
- Business EnvironmentDocument12 pagesBusiness EnvironmentAbhinav GuptaNo ratings yet
- Icelandic Spells and SigilsDocument16 pagesIcelandic Spells and SigilsSimonida Mona Vulić83% (6)
- Body Shaming Among School Going AdolesceDocument5 pagesBody Shaming Among School Going AdolesceClara Widya Mulya MNo ratings yet
- Serendipity - A Sociological NoteDocument2 pagesSerendipity - A Sociological NoteAmlan BaruahNo ratings yet
- 1 PBDocument11 pages1 PBAnggita Wulan RezkyanaNo ratings yet