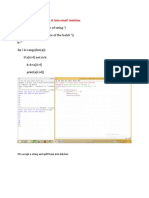
You might also like
- Project On World University RankingsDocument21 pagesProject On World University RankingsSumit PanthiNo ratings yet
- Cs ActivityDocument29 pagesCs Activityhariharan97gNo ratings yet
- PyDocument92 pagesPyShravan Apte25% (4)
- Python - Module Test - Jupyter NotebookDocument6 pagesPython - Module Test - Jupyter NotebookPawan GosaviNo ratings yet
- Python Tutorial 2Document7 pagesPython Tutorial 2queen setiloNo ratings yet
- QP 2-20th Shift 1Document18 pagesQP 2-20th Shift 1Bhavan KumarNo ratings yet
- R SolutionDocument6 pagesR SolutionRoyal ShivNo ratings yet
- Programs With Outputs - Cycle 1Document9 pagesPrograms With Outputs - Cycle 1Akhil Chowdary MaddineniNo ratings yet
- Assignment # 3Document8 pagesAssignment # 3Bushi BaloochNo ratings yet
- Litcoder Final Modules OnlyDocument9 pagesLitcoder Final Modules Onlynaveen kumarNo ratings yet
- PythonDocument16 pagesPythonsajal agarwalNo ratings yet
- Parth Khandelwal J XI-S J 34Document12 pagesParth Khandelwal J XI-S J 34Parth KhandelwalNo ratings yet
- Python Class7Document18 pagesPython Class7KrishnaprasadNo ratings yet
- System Programming Lab File: Amity School of Engineering & TechnologyDocument22 pagesSystem Programming Lab File: Amity School of Engineering & TechnologyMohit AroraNo ratings yet
- AOADocument12 pagesAOANaman jainNo ratings yet
- Practical Xii 11-25Document14 pagesPractical Xii 11-25ain't MohitNo ratings yet
- School of Computer Engineering: Lab RecordsDocument28 pagesSchool of Computer Engineering: Lab RecordsAhmad AlsharefNo ratings yet
- Python Test Series EightDocument36 pagesPython Test Series Eightmahesh palemNo ratings yet
- School of Computer Engineering: Lab RecordsDocument28 pagesSchool of Computer Engineering: Lab RecordsAhmad AlsharefNo ratings yet
- Project IpDocument51 pagesProject IpDwarkesh savaliaNo ratings yet
- Excel 2Document37 pagesExcel 2SHIVAM ASHISHNo ratings yet
- Python Final Lab 2019Document35 pagesPython Final Lab 2019vanithaNo ratings yet
- SolutionDocument11 pagesSolutionPatrick Browne100% (1)
- IP PracDocument37 pagesIP PracScribd Dot ComNo ratings yet
- Computer Project FullDocument23 pagesComputer Project FullZainab NaginaNo ratings yet
- 8th Feb ProgramsDocument5 pages8th Feb ProgramsVishwambhar KulkarniNo ratings yet
- Module of User Deined Function3Document30 pagesModule of User Deined Function3Vinayak SharmaNo ratings yet
- PDFDocument13 pagesPDFsahib.singh.arora69No ratings yet
- DocumentDocument55 pagesDocumentMayankNo ratings yet
- List of FunctionsDocument7 pagesList of FunctionsCyd DuqueNo ratings yet
- Python BuiltInListDocument4 pagesPython BuiltInListroy.scar2196No ratings yet
- Python GTU Study Material E-Notes 3 16012021061619AMDocument36 pagesPython GTU Study Material E-Notes 3 16012021061619AMZainab KhatriNo ratings yet
- Python PracticalDocument35 pagesPython PracticalRahul VermaNo ratings yet
- Python BuiltInListDocument4 pagesPython BuiltInListroy.scar2196No ratings yet
- Lab 4Document4 pagesLab 4Muhammad MukarrumNo ratings yet
- Practical File Class - Xii Informatics Practices (New) : 1. How To Create A Series From A List, Numpy Array and Dict?Document17 pagesPractical File Class - Xii Informatics Practices (New) : 1. How To Create A Series From A List, Numpy Array and Dict?AHMED NAEEM 2No ratings yet
- Basics of Statistics and Probability - FP: Statistical MeasuresDocument12 pagesBasics of Statistics and Probability - FP: Statistical MeasuresShafieul MohammadNo ratings yet
- Python Lab3 Excercise SolutionsDocument6 pagesPython Lab3 Excercise Solutionsakm998800hjNo ratings yet
- Vivek C++Document71 pagesVivek C++Jaymin SheladiaNo ratings yet
- CS2311 Midterm SolutionDocument7 pagesCS2311 Midterm Solutionanish.tionneNo ratings yet
- Aman Singh Samant Sec:H 1918198Document16 pagesAman Singh Samant Sec:H 1918198Divesh SinghNo ratings yet
- SPCC Printout AlokDocument23 pagesSPCC Printout Alokbihod71717No ratings yet
- CodeQuotient SolutionsDocument5 pagesCodeQuotient SolutionsRajveer singh chouhan100% (1)
- DS Lab ManualDocument110 pagesDS Lab ManualKumar AdityaNo ratings yet
- Cs Journal DhruvalDocument53 pagesCs Journal DhruvalDakshNo ratings yet
- Computer Practical File-Siddhartha Patwal 12 FDocument31 pagesComputer Practical File-Siddhartha Patwal 12 FAnkit SoniNo ratings yet
- R Programing BhaguDocument40 pagesR Programing BhaguBhagyalaxmi TambadNo ratings yet
- Class Xii CS Practical File 2Document63 pagesClass Xii CS Practical File 2Arza KaurNo ratings yet
- Computer Science Practical NotesDocument35 pagesComputer Science Practical NotesSelvakumardxbNo ratings yet
- Data Structures and Algorithms LAB Assignment-1 Register Number: 20BCE2285 Name: Namish DevarajDocument33 pagesData Structures and Algorithms LAB Assignment-1 Register Number: 20BCE2285 Name: Namish DevarajNamish DevarajNo ratings yet
- Practical FileDocument50 pagesPractical FileVishalNo ratings yet
- Bucles ForDocument13 pagesBucles Forrosa maria carbajoNo ratings yet
- Computer PracticalDocument129 pagesComputer PracticalsachinprasadNo ratings yet
- Practical MainDocument22 pagesPractical MainCORPSENo ratings yet
- STUDENT'S NAME - Manish Kumar Student'S Uid - 20Bcs7420 Class and Group - 20cse10 - B Semester - 2Document19 pagesSTUDENT'S NAME - Manish Kumar Student'S Uid - 20Bcs7420 Class and Group - 20cse10 - B Semester - 2Manish KumarNo ratings yet
- Table 1Document30 pagesTable 1Akanksha BokareNo ratings yet
- Print (1) X 2 Print (X) OutputDocument20 pagesPrint (1) X 2 Print (X) OutputKidrah 2.0No ratings yet
- SPCC AdheeshDocument16 pagesSPCC Adheeshbihod71717No ratings yet
- ENROLLMENT NO.:-160280107033 PYTHON PROGRAMMING (2180711) : Be - Comp. - Sem-8 - Ldce PageDocument23 pagesENROLLMENT NO.:-160280107033 PYTHON PROGRAMMING (2180711) : Be - Comp. - Sem-8 - Ldce PageupendraNo ratings yet
- Practical - 1: ScreenshotsDocument15 pagesPractical - 1: Screenshotsvraj patelNo ratings yet
- Practical - 2: VRAJ PATEL (20162171034) (CS) Practical - 2Document11 pagesPractical - 2: VRAJ PATEL (20162171034) (CS) Practical - 2vraj patelNo ratings yet
- Practical - 4: VRAJ PATEL (20162171034) (CS) Practical - 4Document17 pagesPractical - 4: VRAJ PATEL (20162171034) (CS) Practical - 4vraj patelNo ratings yet
- Practical - 2: VRAJ PATEL (20162171034) (CS) Practical - 2Document11 pagesPractical - 2: VRAJ PATEL (20162171034) (CS) Practical - 2vraj patelNo ratings yet
- Practical - 1: ScreenshotsDocument15 pagesPractical - 1: Screenshotsvraj patelNo ratings yet
- Practical - 4: VRAJ PATEL (20162171034) (CS) Practical - 4Document16 pagesPractical - 4: VRAJ PATEL (20162171034) (CS) Practical - 4vraj patelNo ratings yet
- Practical - 14: Code - Home - JSPDocument8 pagesPractical - 14: Code - Home - JSPvraj patelNo ratings yet
- Practical - 14: Code - Home - JSPDocument8 pagesPractical - 14: Code - Home - JSPvraj patelNo ratings yet
- High Intermediate 2 Workbook AnswerDocument23 pagesHigh Intermediate 2 Workbook AnswernikwNo ratings yet
- 4.1.1.6 Packet Tracer - Explore The Smart Home - ILM - 51800835Document4 pages4.1.1.6 Packet Tracer - Explore The Smart Home - ILM - 51800835Viet Quoc100% (1)
- Policy Implementation NotesDocument17 pagesPolicy Implementation NoteswubeNo ratings yet
- SchedulingDocument47 pagesSchedulingKonark PatelNo ratings yet
- New Regular and Irregular Verb List and Adjectives 1-Ix-2021Document11 pagesNew Regular and Irregular Verb List and Adjectives 1-Ix-2021MEDALITH ANEL HUACRE SICHANo ratings yet
- A Mini-Review On New Developments in Nanocarriers and Polymers For Ophthalmic Drug Delivery StrategiesDocument21 pagesA Mini-Review On New Developments in Nanocarriers and Polymers For Ophthalmic Drug Delivery StrategiestrongndNo ratings yet
- Computer Science HandbookDocument50 pagesComputer Science HandbookdivineamunegaNo ratings yet
- Datasheet of STS 6000K H1 GCADocument1 pageDatasheet of STS 6000K H1 GCAHome AutomatingNo ratings yet
- COACHING TOOLS Mod4 TGOROWDocument6 pagesCOACHING TOOLS Mod4 TGOROWZoltan GZoltanNo ratings yet
- Purchasing and Supply Chain Management (The Mcgraw-Hill/Irwin Series in Operations and Decision)Document14 pagesPurchasing and Supply Chain Management (The Mcgraw-Hill/Irwin Series in Operations and Decision)Abd ZouhierNo ratings yet
- Dreizler EDocument265 pagesDreizler ERobis OliveiraNo ratings yet
- 3114 Entrance-Door-Sensor 10 18 18Document5 pages3114 Entrance-Door-Sensor 10 18 18Hamilton Amilcar MirandaNo ratings yet
- ETSI EG 202 057-4 Speech Processing - Transmission and Quality Aspects (STQ) - Umbrales de CalidaDocument34 pagesETSI EG 202 057-4 Speech Processing - Transmission and Quality Aspects (STQ) - Umbrales de Calidat3rdacNo ratings yet
- N164.UCPE12B LANmark - OF - UC - 12x - Singlemode - 9 - 125 - OS2 - PE - BlackDocument2 pagesN164.UCPE12B LANmark - OF - UC - 12x - Singlemode - 9 - 125 - OS2 - PE - BlackRaniaTortueNo ratings yet
- Libel Arraignment Pre Trial TranscriptDocument13 pagesLibel Arraignment Pre Trial TranscriptAnne Laraga LuansingNo ratings yet
- Quadratic SDocument20 pagesQuadratic SAnubastNo ratings yet
- The Story of An Hour QuestionpoolDocument5 pagesThe Story of An Hour QuestionpoolAKM pro player 2019No ratings yet
- Market Structure and TrendDocument10 pagesMarket Structure and TrendbillNo ratings yet
- Advantages of The CapmDocument3 pagesAdvantages of The Capmdeeparaghu6No ratings yet
- Submitted By: S.M. Tajuddin Group:245Document18 pagesSubmitted By: S.M. Tajuddin Group:245KhurshidbuyamayumNo ratings yet
- Corporate Members List Iei Mysore Local CentreDocument296 pagesCorporate Members List Iei Mysore Local CentreNagarjun GowdaNo ratings yet
- Facts About The TudorsDocument3 pagesFacts About The TudorsRaluca MuresanNo ratings yet
- Using Ms-Dos 6.22Document1,053 pagesUsing Ms-Dos 6.22lorimer78100% (3)
- ISP SFD PDFDocument73 pagesISP SFD PDFNamo SlimanyNo ratings yet
- Sip Poblacion 2019 2021 Revised Latest UpdatedDocument17 pagesSip Poblacion 2019 2021 Revised Latest UpdatedANNALLENE MARIELLE FARISCALNo ratings yet
- Solitax SCDocument8 pagesSolitax SCprannoyNo ratings yet
- JLPT Application Form Method-December 2023Document3 pagesJLPT Application Form Method-December 2023Sajiri KamatNo ratings yet
- KPJ Healthcare Berhad (NUS ANalyst)Document11 pagesKPJ Healthcare Berhad (NUS ANalyst)noniemoklasNo ratings yet
- Study of Subsonic Wind Tunnel and Its Calibration: Pratik V. DedhiaDocument8 pagesStudy of Subsonic Wind Tunnel and Its Calibration: Pratik V. DedhiaPratikDedhia99No ratings yet
- Aits 2122 PT I Jeea 2022 TD Paper 2 SolDocument14 pagesAits 2122 PT I Jeea 2022 TD Paper 2 SolSoumodeep NayakNo ratings yet