You might also like
- Data Models: Answers To Review QuestionsDocument13 pagesData Models: Answers To Review QuestionsRosh SibalNo ratings yet
- Design of Reinforced Concrete Shear WallDocument8 pagesDesign of Reinforced Concrete Shear WallklynchelleNo ratings yet
- An Orthogonality Property of Legendre Polynomials: ResearchDocument13 pagesAn Orthogonality Property of Legendre Polynomials: ResearchRivaldo Cifuentes MonroyNo ratings yet
- QM Notes: The Wave FunctionDocument11 pagesQM Notes: The Wave Functionmiyuki shiroganeNo ratings yet
- Assignment2Statement 1Document2 pagesAssignment2Statement 1Sasan GhasaeiNo ratings yet
- On A Nonlocal Nonlinear Schrödinger Equation With Self-Induced Parity-Time-Symmetric PotentialDocument10 pagesOn A Nonlocal Nonlinear Schrödinger Equation With Self-Induced Parity-Time-Symmetric PotentialMuhammad IkhwanNo ratings yet
- Chapter 1. The Euclidean Space.2016-2Document19 pagesChapter 1. The Euclidean Space.2016-2Mena SaNo ratings yet
- Gram Charlier and Edgeworth Expansion For Sample VarianceDocument14 pagesGram Charlier and Edgeworth Expansion For Sample VarianceEric BenhamouNo ratings yet
- Lec8h2 OptimalControl PDFDocument83 pagesLec8h2 OptimalControl PDFAnonymous WkbmWCa8MNo ratings yet
- Fourier Analysis and The Zeta FunctionDocument6 pagesFourier Analysis and The Zeta FunctionCreative MathNo ratings yet
- Chapter 02Document50 pagesChapter 02Jack Ignacio NahmíasNo ratings yet
- Notes On Newton-Cotes QuadratureDocument5 pagesNotes On Newton-Cotes QuadratureMatija VasilevNo ratings yet
- Lecture7 PDFDocument16 pagesLecture7 PDFMato KankarašNo ratings yet
- Good McqsDocument4 pagesGood McqsJason DrakeNo ratings yet
- Ch41. Atomic Structure 41.1 - Schrodinger's Equa:on in 3 - D 41.2 - Par:cular in A "3 - D Box" With Infinite Poten:al WallDocument7 pagesCh41. Atomic Structure 41.1 - Schrodinger's Equa:on in 3 - D 41.2 - Par:cular in A "3 - D Box" With Infinite Poten:al Walltarek mahmoudNo ratings yet
- Sec Order ProblemsDocument10 pagesSec Order ProblemsyerraNo ratings yet
- Second Order Odes: Koushik ViswanathanDocument17 pagesSecond Order Odes: Koushik ViswanathanAbhiyan PaudelNo ratings yet
- MATH 219: Spring 2021-22Document7 pagesMATH 219: Spring 2021-22HesapNo ratings yet
- Successive Quadratic ProgrammingDocument33 pagesSuccessive Quadratic Programmingsathish22No ratings yet
- Lec40 - 210102096 - VEDIKA GARGDocument5 pagesLec40 - 210102096 - VEDIKA GARGvasu sainNo ratings yet
- PDE Elementary PDE TextDocument152 pagesPDE Elementary PDE TextThumper KatesNo ratings yet
- Quantum Mechanics Course PostulatesDocument7 pagesQuantum Mechanics Course PostulatesjlbalbNo ratings yet
- Lecture 6: Introduction To Linear Dynamical Systems and ODE ReviewDocument12 pagesLecture 6: Introduction To Linear Dynamical Systems and ODE ReviewBabiiMuffinkNo ratings yet
- Lecture 6: Introduction To Linear Dynamical Systems and ODE ReviewDocument13 pagesLecture 6: Introduction To Linear Dynamical Systems and ODE ReviewBabiiMuffinkNo ratings yet
- A Study of Goldbach's Conjecture and Polignac's Conjecture Equivalence IssuesDocument8 pagesA Study of Goldbach's Conjecture and Polignac's Conjecture Equivalence IssuesGeorge AthanasioyNo ratings yet
- 2 DSystemsDocument14 pages2 DSystemsSaujatya MandalNo ratings yet
- Segmentacin de Venas: 1 Fixed-Period Problems: The Sublinear CaseDocument6 pagesSegmentacin de Venas: 1 Fixed-Period Problems: The Sublinear CaseFer AgrazNo ratings yet
- Assignment2 (SuggestedAnswers)Document10 pagesAssignment2 (SuggestedAnswers)yihong920204No ratings yet
- PDE17 FDocument3 pagesPDE17 FJordan Johm MallillinNo ratings yet
- MIT18 152F11 Lec 05Document11 pagesMIT18 152F11 Lec 05Sanko KosanNo ratings yet
- Assignment 1 - SolutionDocument9 pagesAssignment 1 - SolutionscribdllNo ratings yet
- Ch1 Random Variables and Probability Distributions 0Document25 pagesCh1 Random Variables and Probability Distributions 0Gladzangel LoricabvNo ratings yet
- Finite Difference Methods: MSC Course in Mathematics and Finance Imperial College London, 2010-11Document40 pagesFinite Difference Methods: MSC Course in Mathematics and Finance Imperial College London, 2010-11Muhammad FahimNo ratings yet
- Mathematical Association of AmericaDocument9 pagesMathematical Association of AmericathonguyenNo ratings yet
- 10.34: Numerical Methods Applied To Chemical Engineering Prof. K. BeersDocument24 pages10.34: Numerical Methods Applied To Chemical Engineering Prof. K. Beersdt5632No ratings yet
- 2 Predlog NotesDocument10 pages2 Predlog Noteshihello5679No ratings yet
- Chem 373 - Lecture 2: The Born Interpretation of The WavefunctionDocument29 pagesChem 373 - Lecture 2: The Born Interpretation of The WavefunctionNuansak3No ratings yet
- HW 7 SolsDocument17 pagesHW 7 SolsAmal MendisNo ratings yet
- DiffusionDocument2 pagesDiffusionGunnar CalvertNo ratings yet
- The Heat Equation On RDocument8 pagesThe Heat Equation On RElohim Ortiz CaballeroNo ratings yet
- Exercise 06 PDFDocument2 pagesExercise 06 PDFGulrez MNo ratings yet
- Answer 2016Document8 pagesAnswer 2016John ChanNo ratings yet
- Essay DraftDocument6 pagesEssay DraftEdgars VītiņšNo ratings yet
- Entropy 20 00182Document20 pagesEntropy 20 00182chang lichangNo ratings yet
- MA 201: One Dimensional Wave Equation Lecture - 13Document16 pagesMA 201: One Dimensional Wave Equation Lecture - 13Sahrish AsifNo ratings yet
- MTH401 Final Term Solved Subjective FileDocument5 pagesMTH401 Final Term Solved Subjective FileMuhammad HanzalaNo ratings yet
- 11 Aop719Document19 pages11 Aop719AYMANE JAMALNo ratings yet
- Lecture 25-26Document8 pagesLecture 25-26Kenya LevyNo ratings yet
- Final 13Document3 pagesFinal 13Sutirtha SenguptaNo ratings yet
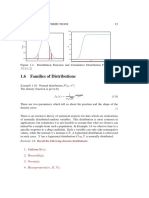
- 1.6. Families of DistributionsDocument9 pages1.6. Families of DistributionsNogs MujeebNo ratings yet
- Placement ExamDocument2 pagesPlacement ExamJeremyWang100% (2)
- Math F211 - Compre - QaDocument1 pageMath F211 - Compre - Qaf20221235No ratings yet
- Diffunderint Leibniz Rule and IntegralsDocument28 pagesDiffunderint Leibniz Rule and Integralsab cNo ratings yet
- DiffunderintDocument26 pagesDiffunderintY SalahNo ratings yet
- Lecture 4: Diffusion: Fick's Second Law: DX X DC) ADocument7 pagesLecture 4: Diffusion: Fick's Second Law: DX X DC) ALloyd R. PonceNo ratings yet
- Common Probability Distributions: 1.1 Bernoulli DistributionDocument6 pagesCommon Probability Distributions: 1.1 Bernoulli DistributionMathew Carl WaniwanNo ratings yet
- H2-Optimal Control - Lec8Document83 pagesH2-Optimal Control - Lec8stara123warNo ratings yet
- Picard's Existence and Uniqueness Theorem: 0 0 0 @F @y 0 0 0 0 X NDocument7 pagesPicard's Existence and Uniqueness Theorem: 0 0 0 @F @y 0 0 0 0 X NadligumelarNo ratings yet
- ELEC301 - Fall 2019 Homework 4: F (x (t) p (t) ) = 1 2π X (ω) ∗ P (ω)Document4 pagesELEC301 - Fall 2019 Homework 4: F (x (t) p (t) ) = 1 2π X (ω) ∗ P (ω)Rıdvan BalamurNo ratings yet
- 1 Review of Key Concepts From Previous Lectures: Lecture Notes - Amber Habib - December 1Document4 pages1 Review of Key Concepts From Previous Lectures: Lecture Notes - Amber Habib - December 1Christopher BellNo ratings yet
- Week 10 - Differential EntropyDocument22 pagesWeek 10 - Differential EntropyLOmesh SaHuNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Andamo Vs IAC DigestDocument1 pageAndamo Vs IAC DigestJotmu SolisNo ratings yet
- GRADES 1 To 12 Daily Lesson LogDocument10 pagesGRADES 1 To 12 Daily Lesson LogJing ReginaldoNo ratings yet
- Urodynamic Testing ReportDocument25 pagesUrodynamic Testing Reportzharah180% (1)
- Resume 2Document1 pageResume 2api-375513943No ratings yet
- Sample of Competency Framework in GEDocument34 pagesSample of Competency Framework in GEPareshNo ratings yet
- Brazilian Wine Industry PDFDocument16 pagesBrazilian Wine Industry PDFKuntal ChowdhuryNo ratings yet
- The Extent of COVID-19 Pandemic Socio-Economic Impact On Global Poverty. A Global Integrative Multidisciplinary ReviewDocument13 pagesThe Extent of COVID-19 Pandemic Socio-Economic Impact On Global Poverty. A Global Integrative Multidisciplinary ReviewtechNo ratings yet
- Relative Clause 1001Document5 pagesRelative Clause 1001NganNo ratings yet
- GEOGRAPHY LESSON NotesDocument2 pagesGEOGRAPHY LESSON NotesLeelaammaNo ratings yet
- Risk Assessment CalculatorDocument2 pagesRisk Assessment Calculatornale988No ratings yet
- 04 Diamond Taxi v. Llamas Jr.Document3 pages04 Diamond Taxi v. Llamas Jr.Gigi Amparo MartinNo ratings yet
- Your Basic Guide To Excel As A Data Analyst 1681461448Document9 pagesYour Basic Guide To Excel As A Data Analyst 1681461448Robin ZubererNo ratings yet
- QCMDL 21 57987 Beltran Karen Villavicensio 1Document1 pageQCMDL 21 57987 Beltran Karen Villavicensio 1lemuel clausNo ratings yet
- Radar PerformanceDocument30 pagesRadar PerformanceHarbinder Singh100% (3)
- Two Sample T Right Tailed Equal Variance TemplateDocument3 pagesTwo Sample T Right Tailed Equal Variance TemplateLSSI LEANNo ratings yet
- BIWS REIT Projection ReferenceDocument3 pagesBIWS REIT Projection ReferenceLisaNo ratings yet
- Intro To Philo Week 8 DLPDocument9 pagesIntro To Philo Week 8 DLPAnne Rivero100% (1)
- Herrera Jose DISC and MotivatorsDocument11 pagesHerrera Jose DISC and MotivatorsJose HerreraNo ratings yet
- Digital Image Processing and Computer Vision: Course WebsiteDocument46 pagesDigital Image Processing and Computer Vision: Course WebsiteAastha HandaNo ratings yet
- Success Test 8 - TensesDocument9 pagesSuccess Test 8 - TensesArun KumarNo ratings yet
- Memorandum PauigDocument17 pagesMemorandum PauigEm MalenabNo ratings yet
- Microsoft Word - Dose Table 904nm For Low Level Laser Therapy WALT 2010Document1 pageMicrosoft Word - Dose Table 904nm For Low Level Laser Therapy WALT 2010Guilherme FisioNo ratings yet
- Tempest - PlayDocument17 pagesTempest - PlaySharmila Kumari RNo ratings yet
- Catharsis by Devapriya MukherjeeDocument9 pagesCatharsis by Devapriya MukherjeeCinnamonTeal PublishingNo ratings yet
- Individual Assignment Bui Van Thanh MMDocument9 pagesIndividual Assignment Bui Van Thanh MMThanh BuiNo ratings yet
- in Mechanics, The Is Done by A Force As It Acts Upon A Body Moving in The Direction of The Force. This Work Is CalledDocument20 pagesin Mechanics, The Is Done by A Force As It Acts Upon A Body Moving in The Direction of The Force. This Work Is CalledSivateja NallamothuNo ratings yet
- Deutsche Bank Ag Manila Branch v. CirDocument3 pagesDeutsche Bank Ag Manila Branch v. Circhappy_leigh118No ratings yet
- 671MX Series-manual-MultiV1.0 PDFDocument44 pages671MX Series-manual-MultiV1.0 PDFSofyan RiyadinNo ratings yet