You might also like
- Nintendo 64 Architecture: Architecture of Consoles: A Practical Analysis, #8From EverandNintendo 64 Architecture: Architecture of Consoles: A Practical Analysis, #8No ratings yet
- Flow 1 2020 PDFDocument21 pagesFlow 1 2020 PDFJay Jaber100% (1)
- Practical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationFrom EverandPractical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationNo ratings yet
- Alif Baa Assessment TestDocument5 pagesAlif Baa Assessment TestJay JaberNo ratings yet
- Preliminary Specifications: Programmed Data Processor Model Three (PDP-3) October, 1960From EverandPreliminary Specifications: Programmed Data Processor Model Three (PDP-3) October, 1960No ratings yet
- Computer Organization and Architecture: Cache MemoryDocument57 pagesComputer Organization and Architecture: Cache MemoryRyan R. Sarco100% (1)
- 7 Requirements of Data Loss PreventionDocument8 pages7 Requirements of Data Loss PreventionJawaid IqbalNo ratings yet
- TOGAF 9 Template - Compliance AssessmentDocument5 pagesTOGAF 9 Template - Compliance AssessmentMansyur ,No ratings yet
- Cache MemoryDocument72 pagesCache MemoryMaroun Bejjany67% (3)
- COSS - Contact Session - 4 - With AnnotatonDocument44 pagesCOSS - Contact Session - 4 - With Annotatonnotes.chandanNo ratings yet
- Chapter 5Document87 pagesChapter 5supersibas11No ratings yet
- Module 4: Memory System Organization & ArchitectureDocument97 pagesModule 4: Memory System Organization & ArchitectureSurya SunderNo ratings yet
- COSS - Contact Session - 4Document34 pagesCOSS - Contact Session - 4Prasana VenkateshNo ratings yet
- The Motivation For Caches: Memory SystemDocument9 pagesThe Motivation For Caches: Memory SystemNarender KumarNo ratings yet
- S1 Sistem Komputer: Universitas DiponegoroDocument27 pagesS1 Sistem Komputer: Universitas Diponegorotanwir01No ratings yet
- ECE4680 Computer Organization and Architecture Memory Hierarchy: Cache SystemDocument25 pagesECE4680 Computer Organization and Architecture Memory Hierarchy: Cache SystemNarender KumarNo ratings yet
- Cache MappingDocument44 pagesCache MappingxoeaeoxNo ratings yet
- William Stallings Computer Organization and Architecture 7th Edition Chapter 4 Cache Memory CharacteristicsDocument57 pagesWilliam Stallings Computer Organization and Architecture 7th Edition Chapter 4 Cache Memory CharacteristicsDurairajan AasaithambaiNo ratings yet
- William Stallings Computer Organization and Architecture 7th Edition Cache MemoryDocument57 pagesWilliam Stallings Computer Organization and Architecture 7th Edition Cache MemorySumaiya KhanNo ratings yet
- Chap 6Document48 pagesChap 6siddhiNo ratings yet
- 9장 캐시Document65 pages9장 캐시민규No ratings yet
- William Stallings Computer Organization and Architecture 7th Edition Cache MemoryDocument67 pagesWilliam Stallings Computer Organization and Architecture 7th Edition Cache Memorydilshadsabir8911No ratings yet
- 04_Cache MemoryDocument47 pages04_Cache MemoryuabdulgwadNo ratings yet
- 04 - Cache Memory (Compatibility Mode)Document12 pages04 - Cache Memory (Compatibility Mode)John PhanNo ratings yet
- Cache MemoryDocument10 pagesCache MemoryasrNo ratings yet
- Computer Org and Arch: R.MageshDocument48 pagesComputer Org and Arch: R.Mageshmage9999No ratings yet
- Cache Memory Mapping TechniquesDocument43 pagesCache Memory Mapping TechniquesLalala LandNo ratings yet
- Stallings Computer Organization and Architecture 6th Edition Chapter 4 Cache MemoryDocument55 pagesStallings Computer Organization and Architecture 6th Edition Chapter 4 Cache Memorydarwinvargas2011No ratings yet
- 5 1Document39 pages5 1tinni09112003No ratings yet
- 4.1 Computer Memory System OverviewDocument12 pages4.1 Computer Memory System Overviewmtenay1No ratings yet
- Cache MemoryDocument39 pagesCache MemoryhariprasathkNo ratings yet
- COSS - Lecture - 5 - With AnnotationDocument23 pagesCOSS - Lecture - 5 - With Annotationnotes.chandanNo ratings yet
- Cache Memory - Mapping FunctionsDocument36 pagesCache Memory - Mapping FunctionsMajety S LskshmiNo ratings yet
- Cache Memory-Associative MappingDocument23 pagesCache Memory-Associative MappingEswin AngelNo ratings yet
- COA Lecture 25 26Document13 pagesCOA Lecture 25 26Chhaveesh AgnihotriNo ratings yet
- 04 Cache MemoryDocument75 pages04 Cache MemorySangeetha ShankaranNo ratings yet
- The Memory Hierarchy: - Ideally One Would Desire An Indefinitely Large Memory Capacity SuchDocument23 pagesThe Memory Hierarchy: - Ideally One Would Desire An Indefinitely Large Memory Capacity SuchHarshitaSharmaNo ratings yet
- Memory Hierarchy DesignDocument115 pagesMemory Hierarchy Designshivu96No ratings yet
- William Stallings Computer Organization and Architecture 6th Edition Cache MemoryDocument45 pagesWilliam Stallings Computer Organization and Architecture 6th Edition Cache MemoryFatima ZehraNo ratings yet
- Computer memory mappingDocument15 pagesComputer memory mappingAndualem YismawNo ratings yet
- Memory Hierarchy Design UNIT-V - Reducing Cache Miss Penalty and Rate via ParallelismDocument54 pagesMemory Hierarchy Design UNIT-V - Reducing Cache Miss Penalty and Rate via ParallelismmannanabdulsattarNo ratings yet
- William Stallings Computer Organization and Architecture 8th Edition Cache MemoryDocument71 pagesWilliam Stallings Computer Organization and Architecture 8th Edition Cache MemoryBum TumNo ratings yet
- Cache Memory - January 2014Document90 pagesCache Memory - January 2014Dare DevilNo ratings yet
- 13 MemoryDocument13 pages13 MemoryNishanthoraNo ratings yet
- Computer Arch 06Document41 pagesComputer Arch 06NaheedNo ratings yet
- Lec 5Document35 pagesLec 5Mohamed HelmyNo ratings yet
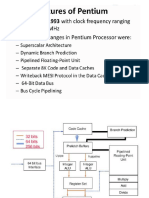
- Pentium RNM FinalDocument81 pagesPentium RNM FinalRajNo ratings yet
- Lecture 4Document35 pagesLecture 4Meena ShahNo ratings yet
- Cache + Associations Ch-4Document52 pagesCache + Associations Ch-4ahsan2020azizNo ratings yet
- CH 06Document58 pagesCH 06Yohannes DerejeNo ratings yet
- Course Code: CS 283 Course Title: Computer Architecture: Class Day: Friday Timing: 12:00 To 1:30Document23 pagesCourse Code: CS 283 Course Title: Computer Architecture: Class Day: Friday Timing: 12:00 To 1:30Niaz Ahmed KhanNo ratings yet
- Caching: AcknowledgementsDocument6 pagesCaching: Acknowledgementsbob smithNo ratings yet
- William Stallings Computer Organization and Architecture 8th Edition Cache MemoryDocument71 pagesWilliam Stallings Computer Organization and Architecture 8th Edition Cache MemoryRudi GunawanNo ratings yet
- CS 333 Reading Assignment and Sample ProblemsDocument6 pagesCS 333 Reading Assignment and Sample ProblemsKaruppanan KomathyNo ratings yet
- William Stallings Computer Organization and Architecture 8th Edition Cache MemoryDocument71 pagesWilliam Stallings Computer Organization and Architecture 8th Edition Cache MemoryRehman HazratNo ratings yet
- UNIT2 Cahe-OptDocument134 pagesUNIT2 Cahe-OptDhananjay JahagirdarNo ratings yet
- Memory Hierarchies (Part 2) Review: The Memory HierarchyDocument7 pagesMemory Hierarchies (Part 2) Review: The Memory HierarchyhuyquyNo ratings yet
- Random Access MemoryDocument3 pagesRandom Access MemoryJi Rawat JiNo ratings yet
- Characteristics Location Capacity Unit of Transfer Access Method Performance Physical Type Physical Characteristics OrganisationDocument53 pagesCharacteristics Location Capacity Unit of Transfer Access Method Performance Physical Type Physical Characteristics OrganisationMarkNo ratings yet
- Stallings Computer Architecture 8th Edition Cache Memory CharacteristicsDocument71 pagesStallings Computer Architecture 8th Edition Cache Memory CharacteristicsDoc TelNo ratings yet
- CS140 Computer Organization: Chapter 6: MemoryDocument81 pagesCS140 Computer Organization: Chapter 6: MemoryG Srilatha G SrilathaNo ratings yet
- wk10a-Cache (PDF)(1)Document25 pageswk10a-Cache (PDF)(1)V SwaythaNo ratings yet
- Pointers and ArraysDocument94 pagesPointers and ArraysJay JaberNo ratings yet
- MIPS Processor DesignDocument70 pagesMIPS Processor DesignJay JaberNo ratings yet
- System ViewDocument54 pagesSystem ViewJay JaberNo ratings yet
- Functions and The StackDocument43 pagesFunctions and The StackJay JaberNo ratings yet
- Machine LanguageDocument51 pagesMachine LanguageJay JaberNo ratings yet
- 450 California History IntroductionDocument25 pages450 California History IntroductionJay JaberNo ratings yet
- 450 de Jure vs. de Facto Segregation.Document37 pages450 de Jure vs. de Facto Segregation.Jay JaberNo ratings yet
- 450 Chinese ExperienceDocument18 pages450 Chinese ExperienceJay JaberNo ratings yet
- College Works EssayDocument1 pageCollege Works EssayJay JaberNo ratings yet
- 317 Unit 01 - Setup PDFDocument35 pages317 Unit 01 - Setup PDFJay JaberNo ratings yet
- Midterm Exam Winter 2020Document2 pagesMidterm Exam Winter 2020Jay JaberNo ratings yet
- RICE CEMLI TerminologyDocument2 pagesRICE CEMLI TerminologyNavneet KasulkarNo ratings yet
- ITH24 ReactJS Modelpaper MoodleDocument2 pagesITH24 ReactJS Modelpaper MoodleThrinadhNo ratings yet
- IoT ELE Model Question Paper 1Document2 pagesIoT ELE Model Question Paper 1Sathish SinghNo ratings yet
- Android Based Idir Information Management SystemDocument90 pagesAndroid Based Idir Information Management Systemabdellahnuredin03No ratings yet
- Long-Exam-SHS-Sir-Emman-Empowerment-MIL - ALL STRANDDocument2 pagesLong-Exam-SHS-Sir-Emman-Empowerment-MIL - ALL STRANDsimeon tayawaNo ratings yet
- Digital Literacy and CybersecurityDocument17 pagesDigital Literacy and Cybersecurityswapniljnv08No ratings yet
- MAQUE - M1 (Information and Communications Technology pt.1)Document8 pagesMAQUE - M1 (Information and Communications Technology pt.1)Kenneth Laraño MaqueNo ratings yet
- Bangalore Higher Income Mobile Only 2Document2,142 pagesBangalore Higher Income Mobile Only 2postofficeNo ratings yet
- Configuring Telnet Using An Username & Password: Khawar Butt Ccie # 12353 (R/S, Security, SP, DC, Voice, Storage & Ccde)Document7 pagesConfiguring Telnet Using An Username & Password: Khawar Butt Ccie # 12353 (R/S, Security, SP, DC, Voice, Storage & Ccde)madanmohan22No ratings yet
- Pre Sales Systems Solution Engineer in Los Angeles CA Resume Oleg ChaikovskyDocument3 pagesPre Sales Systems Solution Engineer in Los Angeles CA Resume Oleg ChaikovskyolegchaikovskyNo ratings yet
- Zend Server PDFDocument308 pagesZend Server PDFIvan HorvatNo ratings yet
- Site Save of CodeSlinger - Co.uk - GameBoy Emulator Programming in C++ - MemoryDocument3 pagesSite Save of CodeSlinger - Co.uk - GameBoy Emulator Programming in C++ - MemoryRyanNo ratings yet
- Smart Implementation - Intergraph's Latest ApproachDocument4 pagesSmart Implementation - Intergraph's Latest ApproachLogeswaran AppaduraiNo ratings yet
- Broker and Universal Messaging - Editions Comparison Sep 2016Document15 pagesBroker and Universal Messaging - Editions Comparison Sep 2016Sowmya NagarajaNo ratings yet
- DXP RTL Reference Tr0126 DxprtlreferenceDocument1,144 pagesDXP RTL Reference Tr0126 DxprtlreferenceieadrianNo ratings yet
- Database Design for Ordering and Delivery Management SystemDocument11 pagesDatabase Design for Ordering and Delivery Management SystemVrushabh KunkavalekarNo ratings yet
- Paper 88-Analysis About Benefits of Software Defined Wide Area NetworkDocument11 pagesPaper 88-Analysis About Benefits of Software Defined Wide Area NetworkAkbar aliNo ratings yet
- Itil Managing Digital Information AssetsDocument17 pagesItil Managing Digital Information Assetsjcordova8879No ratings yet
- Implementation Document - Pengadaan Perangkat HPE Aruba Dan Fortinet + ImplementasiDocument55 pagesImplementation Document - Pengadaan Perangkat HPE Aruba Dan Fortinet + ImplementasiROY LISTON PANAHATAN PANJAITANNo ratings yet
- Bank Account Management in SAP S - 4HANA - SAP BlogsDocument14 pagesBank Account Management in SAP S - 4HANA - SAP BlogsKapadia MritulNo ratings yet
- AIM KTDocument29 pagesAIM KTNikitha ReddyNo ratings yet
- DBMS Interview Questions and Answers: Sindhuja HariDocument71 pagesDBMS Interview Questions and Answers: Sindhuja HariDeepak SinghNo ratings yet
- IT Practical File Main 2023-24Document45 pagesIT Practical File Main 2023-24GagandeepNo ratings yet
- Assignment Text File HandlingDocument7 pagesAssignment Text File HandlingAshish KumarNo ratings yet
- Grade 12 Security Requirement TriadDocument12 pagesGrade 12 Security Requirement TriadLeslie PerezNo ratings yet
- Comandos Palo AltoDocument3 pagesComandos Palo AltogochorneaNo ratings yet
- Lec 2 - SrsDocument12 pagesLec 2 - SrsUsman YousafNo ratings yet
- Net Suite APIDocument1,382 pagesNet Suite APIycaredNo ratings yet