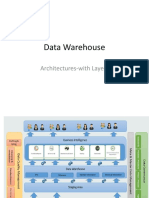
You might also like
- Data Architect or ETL Architect or BI Architect or Data WarehousDocument4 pagesData Architect or ETL Architect or BI Architect or Data Warehousapi-77236210No ratings yet
- Informatica Data Quality Products OverviewDocument43 pagesInformatica Data Quality Products OverviewjbeatoflNo ratings yet
- Performance Tuning On DWSDocument146 pagesPerformance Tuning On DWSRabindra P.SinghNo ratings yet
- Services BrochureDocument3 pagesServices BrochureHarshal GuravNo ratings yet
- Data Mining and WarehousingDocument16 pagesData Mining and WarehousingAshwathy MNNo ratings yet
- Data Quality MigrationDocument4 pagesData Quality MigrationsyfreelanceNo ratings yet
- Big Query Optimization DocumentDocument10 pagesBig Query Optimization DocumentAshishNo ratings yet
- Blue PrismDocument5 pagesBlue PrismRamKumar GNo ratings yet
- Chapter 9 Fundamentals of An ETL ArchitectureDocument8 pagesChapter 9 Fundamentals of An ETL Architecturebhaskarp23No ratings yet
- Best Practices in Data Modeling PDFDocument31 pagesBest Practices in Data Modeling PDFleeanntoto1118No ratings yet
- Software Risk ManagementDocument35 pagesSoftware Risk ManagementDr. Hitesh MohapatraNo ratings yet
- Introduction to Data WarehousingDocument14 pagesIntroduction to Data WarehousingNikhil GajendraNo ratings yet
- BIGuidebook Templates - BI Project PlanDocument14 pagesBIGuidebook Templates - BI Project Planhieu leNo ratings yet
- Introduction To Data WarehousingDocument74 pagesIntroduction To Data WarehousingsvdonthaNo ratings yet
- MSBIDocument30 pagesMSBISuresh MupparajuNo ratings yet
- Cloud Data Warehouse: Streamsets For SnowflakeDocument6 pagesCloud Data Warehouse: Streamsets For SnowflakeJohn RhoNo ratings yet
- The Politics of Data WarehousingDocument9 pagesThe Politics of Data WarehousingVaibhav C GandhiNo ratings yet
- System Manual Surgico 60DHFDocument83 pagesSystem Manual Surgico 60DHFSukrisdianto Dianto100% (2)
- Online Post Graduate Program in Big Data EngineeringDocument17 pagesOnline Post Graduate Program in Big Data EngineeringvenkivlrNo ratings yet
- HOL Informatica DataQuality 9.1Document48 pagesHOL Informatica DataQuality 9.1vvmexNo ratings yet
- Snowflake - Data Warehouse Development - Five Best PracticesDocument14 pagesSnowflake - Data Warehouse Development - Five Best PracticesChaitya BobbaNo ratings yet
- Data Warehouse Essentials for Business IntelligenceDocument23 pagesData Warehouse Essentials for Business IntelligencewanderaNo ratings yet
- SSIS Package Naming StandardsDocument6 pagesSSIS Package Naming StandardskodandaNo ratings yet
- MDM 104HF3 ConfigurationGuide enDocument700 pagesMDM 104HF3 ConfigurationGuide enManoj YanalaNo ratings yet
- Design of E-Commerce Information System On Web-Based Online ShoppingDocument11 pagesDesign of E-Commerce Information System On Web-Based Online ShoppingHARINo ratings yet
- Erp Comparison v4 0Document118 pagesErp Comparison v4 0vatsal shahNo ratings yet
- My SQL For BeginnersDocument3 pagesMy SQL For BeginnersPallavi SinghNo ratings yet
- BI ProjectDocument114 pagesBI ProjectBharath Nalluri100% (1)
- Cloud Cost Monitoring and Management ServiceDocument3 pagesCloud Cost Monitoring and Management ServiceCloud VerseNo ratings yet
- Power BI VisualsDocument30 pagesPower BI Visualssree lekhaNo ratings yet
- White Paper - Data Warehouse Documentation RoadmapDocument28 pagesWhite Paper - Data Warehouse Documentation RoadmapSergey MelekhinNo ratings yet
- Data Mining and Data Warehouse BYDocument12 pagesData Mining and Data Warehouse BYapi-19799369100% (1)
- 04 - Modern Data Lake Powered by Data Virtualization & AI - Le Bui HungDocument19 pages04 - Modern Data Lake Powered by Data Virtualization & AI - Le Bui HungDinh ThongNo ratings yet
- ETL (Extract, Transform, and Load) Process in Data WarehouseDocument6 pagesETL (Extract, Transform, and Load) Process in Data WarehouseDivya guptaNo ratings yet
- Data Mesh A Business Oriented Framework For Quicker Insights HCL WhitepapersDocument16 pagesData Mesh A Business Oriented Framework For Quicker Insights HCL WhitepapersptanhtanhNo ratings yet
- Eb Cloud Data Warehouse Comparison Ebook enDocument10 pagesEb Cloud Data Warehouse Comparison Ebook enali ramezaniNo ratings yet
- Datastage On Ibm Cloud Pak For DataDocument6 pagesDatastage On Ibm Cloud Pak For Dataterra_zgNo ratings yet
- AnalytiX DS - Master DeckDocument56 pagesAnalytiX DS - Master DeckAnalytiXDSNo ratings yet
- Data Warehousing ConceptsDocument9 pagesData Warehousing ConceptsVikram ReddyNo ratings yet
- PPTDocument15 pagesPPTMbade NDONGNo ratings yet
- The Teradata Database - Part 3 Usage Fundamentals PDFDocument20 pagesThe Teradata Database - Part 3 Usage Fundamentals PDFshrikanchi rathiNo ratings yet
- Installation Guide Apache KylinDocument17 pagesInstallation Guide Apache KylinJose100% (1)
- Data Warehouse ArchitectureDocument11 pagesData Warehouse ArchitectureAbish HaridasanNo ratings yet
- Guidewire Data Conversion Approach PaperDocument5 pagesGuidewire Data Conversion Approach PaperSowbhagya VaderaNo ratings yet
- SCD Types and Tracking Changes in DWH DimensionsDocument26 pagesSCD Types and Tracking Changes in DWH DimensionsPavanNo ratings yet
- Business Intelligence Competency Center PDFDocument21 pagesBusiness Intelligence Competency Center PDFAsalia ZavalaNo ratings yet
- SSIS Operational and Tuning GuideDocument50 pagesSSIS Operational and Tuning GuideEnguerran DELAHAIENo ratings yet
- Web-Enable Rental DVD Data WarehouseDocument2 pagesWeb-Enable Rental DVD Data WarehouseAdeel MEMONNo ratings yet
- ETL Testing in Less TimeDocument16 pagesETL Testing in Less TimeShiva CHNo ratings yet
- Bi Project Implementation Life CycleDocument5 pagesBi Project Implementation Life CycleRajesh GlrNo ratings yet
- Big Data TestingDocument10 pagesBig Data TestingminalNo ratings yet
- Mysap HealthcareDocument41 pagesMysap HealthcareHot_sergioNo ratings yet
- Data Warehouse Architecture LayersDocument21 pagesData Warehouse Architecture LayersAdil Bin KhalidNo ratings yet
- Notes On Dimension and FactsDocument32 pagesNotes On Dimension and FactsVamsi KarthikNo ratings yet
- IT Infrastructure Deployment A Complete Guide - 2020 EditionFrom EverandIT Infrastructure Deployment A Complete Guide - 2020 EditionNo ratings yet
- Client Server Architecture A Complete Guide - 2020 EditionFrom EverandClient Server Architecture A Complete Guide - 2020 EditionNo ratings yet
- Google Cloud Architect with expertise in Data pipelines and Cloud ModernizationDocument2 pagesGoogle Cloud Architect with expertise in Data pipelines and Cloud ModernizationbittuankitNo ratings yet
- Vinay Lokwani: GCP Data EngineerDocument4 pagesVinay Lokwani: GCP Data EngineerbittuankitNo ratings yet
- GCP Training: © 2020 Coforge © 2020 CoforgeDocument17 pagesGCP Training: © 2020 Coforge © 2020 CoforgebittuankitNo ratings yet
- Cloud Digital LeaderDocument7 pagesCloud Digital LeadersnehithaNo ratings yet
- UNIX Helpful Commands: Brush Up Basic CommandsDocument12 pagesUNIX Helpful Commands: Brush Up Basic CommandsbittuankitNo ratings yet
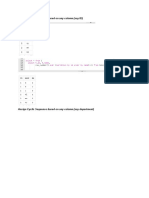
- Assign Cyclic Sequence Based On Any Column (Say ID)Document7 pagesAssign Cyclic Sequence Based On Any Column (Say ID)bittuankitNo ratings yet
- The Best Python Interview GuideDocument35 pagesThe Best Python Interview GuidebittuankitNo ratings yet
- SQL NotesDocument1 pageSQL NotesbittuankitNo ratings yet
- Difference Between Varchar and Varchar2 Data Types?: Salary Decimal (9,2) Constraint Sal - CK Check (Salary 10000)Document4 pagesDifference Between Varchar and Varchar2 Data Types?: Salary Decimal (9,2) Constraint Sal - CK Check (Salary 10000)bittuankitNo ratings yet
- Machine Learning and Artificial Intelligence As A Complement To Condition Monitoring in A Predictive Maintenance SettingDocument20 pagesMachine Learning and Artificial Intelligence As A Complement To Condition Monitoring in A Predictive Maintenance SettingHoa Dinh NguyenNo ratings yet
- Varun TyagiDocument10 pagesVarun TyagiSurinderNo ratings yet
- Iim Lucknow Hepp & Final Placements 2020-21: Job Description FormDocument1 pageIim Lucknow Hepp & Final Placements 2020-21: Job Description FormmanishNo ratings yet
- WP EN DI Talend DefinitiveGuide DataIntegrationDocument78 pagesWP EN DI Talend DefinitiveGuide DataIntegrationNischal reddyNo ratings yet
- Personal Profile: Senior BPM ConsultantDocument3 pagesPersonal Profile: Senior BPM ConsultantJJNo ratings yet
- Bpo2 PPT 3Document12 pagesBpo2 PPT 3Mary Lynn Dela PeñaNo ratings yet
- Power BI As A Service Client Success StoriesDocument3 pagesPower BI As A Service Client Success StoriesAshish PathaniaNo ratings yet
- Factors Influencing The Usage of MobileDocument20 pagesFactors Influencing The Usage of MobileSofi KetemaNo ratings yet
- S&P/KRX Exchanges Index: MethodologyDocument15 pagesS&P/KRX Exchanges Index: MethodologyEdwin ChanNo ratings yet
- Product Change Notice: Huawei PCN ALD-20160005 Antenna Connector ChangeDocument17 pagesProduct Change Notice: Huawei PCN ALD-20160005 Antenna Connector ChangeAnonymous CGk2roNo ratings yet
- 10.1007@978 3 030 27615 7Document458 pages10.1007@978 3 030 27615 7Abdillah AzulNo ratings yet
- CSR Management Solution ProviderDocument27 pagesCSR Management Solution ProviderGidafianNo ratings yet
- TarisaDocument39 pagesTarisaRyan AdicandraNo ratings yet
- How Industries ChangeDocument11 pagesHow Industries ChangeashishNo ratings yet
- IOP Conf. Series: Materials Science and Engineering explores the Role of IT AuditDocument7 pagesIOP Conf. Series: Materials Science and Engineering explores the Role of IT AuditAnnie TranNo ratings yet
- Baroda Paypoint - PresentationDocument5 pagesBaroda Paypoint - PresentationRajkot academyNo ratings yet
- Angular Certification Training20220401180227Document14 pagesAngular Certification Training20220401180227Akshay RahaneNo ratings yet
- TBBN P/N Dtna P/N Dtna DrawingDocument1 pageTBBN P/N Dtna P/N Dtna DrawingsebastianNo ratings yet
- Technique Guide 4 Working AgreementsDocument4 pagesTechnique Guide 4 Working AgreementspranavvikasNo ratings yet
- McAfee Solidcore Reviewers GuideDocument70 pagesMcAfee Solidcore Reviewers Guideamoin786No ratings yet
- Prototyping Models Throughout DesignDocument12 pagesPrototyping Models Throughout DesignKrishnendu KuttappanNo ratings yet
- Module 9: E-Business Systems: ReadingsDocument5 pagesModule 9: E-Business Systems: ReadingsasimNo ratings yet
- 23 - Technology and Innovation Report 2021Document1 page23 - Technology and Innovation Report 2021Aprndz AprendizNo ratings yet
- Student Attendance Management System Use Case Diagram PDFDocument3 pagesStudent Attendance Management System Use Case Diagram PDFMekonnen SolomonNo ratings yet