You might also like
- Big Data AnalyticsDocument5 pagesBig Data AnalyticsDatatools GYE-ECNo ratings yet
- Strategic Business AnalysisDocument14 pagesStrategic Business AnalysisEdu Villanueva Jr.100% (1)
- Data Lake and Data WarehouseDocument24 pagesData Lake and Data WarehouseTấn Tỷ Huỳnh100% (1)
- Big Data Anlaytics: Unit 1 & 2 - Question Bank MCQ'sDocument4 pagesBig Data Anlaytics: Unit 1 & 2 - Question Bank MCQ'sujyNo ratings yet
- Big Data Analytics Methods and Applications Jovan PehcevskiDocument430 pagesBig Data Analytics Methods and Applications Jovan Pehcevskihizem chaima100% (2)
- Data Visualization Techniques Traditional Data To Big DataDocument23 pagesData Visualization Techniques Traditional Data To Big DataaghnetNo ratings yet
- Rao 2018Document81 pagesRao 2018Sultan AlmaghrabiNo ratings yet
- Big Data: Presented by J.Jitendra KumarDocument14 pagesBig Data: Presented by J.Jitendra KumarJitendra KumarNo ratings yet
- Camm 3e Ch01 PPT PDFDocument41 pagesCamm 3e Ch01 PPT PDFRhigene SolanaNo ratings yet
- ICT Maritime Opportunities 2030 - Maritime Connected and Automated Transport - Maritime Europe Strategic ActionDocument11 pagesICT Maritime Opportunities 2030 - Maritime Connected and Automated Transport - Maritime Europe Strategic ActionPrimus Pandumudita100% (2)
- Big Data Solution For Tourism PDFDocument10 pagesBig Data Solution For Tourism PDFprave19No ratings yet
- Big Data Research PaperDocument10 pagesBig Data Research PaperMeraj AlamNo ratings yet
- A Survey On Big Data Analytics Challenges, Open Research Issues and ToolsDocument11 pagesA Survey On Big Data Analytics Challenges, Open Research Issues and ToolsIJRASETPublicationsNo ratings yet
- A Blue Ocean StrategyDocument22 pagesA Blue Ocean StrategyNaru TosNo ratings yet
- Benefits, Challenges and Tools of Big Data Management PDFDocument9 pagesBenefits, Challenges and Tools of Big Data Management PDFFrancisco Javier Medina VillarrealNo ratings yet
- Azure Synapse E-BookDocument21 pagesAzure Synapse E-BookZohoNo ratings yet
- Leaders and Innovators: How Data-Driven Organizations Are Winning with AnalyticsFrom EverandLeaders and Innovators: How Data-Driven Organizations Are Winning with AnalyticsRating: 1 out of 5 stars1/5 (1)
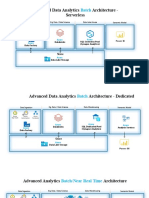
- Advanced Data Analytics Architecture - Serverless: BatchDocument4 pagesAdvanced Data Analytics Architecture - Serverless: BatchAngelo Cardenas M.No ratings yet
- Big Data Analysis For Data Visualization: A Review: January 2021Document13 pagesBig Data Analysis For Data Visualization: A Review: January 2021Famous TVNo ratings yet
- Big Data A ReviewDocument7 pagesBig Data A ReviewEditor IJTSRDNo ratings yet
- 975 ArticleText 3963 1 10 20221008Document12 pages975 ArticleText 3963 1 10 20221008blackfnbirdNo ratings yet
- BBRC Vol 14 No 04 2021-93Document7 pagesBBRC Vol 14 No 04 2021-93Dr Sharique AliNo ratings yet
- The Challenges of Big Data Visual Analytics and Recent PlatformsDocument6 pagesThe Challenges of Big Data Visual Analytics and Recent PlatformsWorld of Computer Science and Information Technology Journal100% (1)
- Dendrogram Clustering For 3D Data Analytics in Smart CityDocument7 pagesDendrogram Clustering For 3D Data Analytics in Smart CitypandalovetacoNo ratings yet
- Business Intelligence ToolsDocument16 pagesBusiness Intelligence ToolsGurdeep KaurNo ratings yet
- Machine Learning With Big Data: Challenges and ApproachesDocument22 pagesMachine Learning With Big Data: Challenges and ApproachesVipin GeorgeNo ratings yet
- Data-Driven Decision Making in The Public Sector: A Systematic ReviewDocument13 pagesData-Driven Decision Making in The Public Sector: A Systematic ReviewIJAERS JOURNALNo ratings yet
- BIMBigDataCF-K F IbrahimDocument8 pagesBIMBigDataCF-K F IbrahimMichele TenediniNo ratings yet
- Big Data Management Challenges: ArticleDocument8 pagesBig Data Management Challenges: ArticleAhmed Adel SharafaniNo ratings yet
- Handling Uncertainty in The Big Data ProcessingDocument6 pagesHandling Uncertainty in The Big Data ProcessingVIVA-TECH IJRINo ratings yet
- A Big Data Analytics Study Challenges, Unresolved Research Issues, and TechniquesDocument8 pagesA Big Data Analytics Study Challenges, Unresolved Research Issues, and TechniquesSagar ManjareNo ratings yet
- Necessity of Big Data and Analytics For Good E-Governance: September 2017Document11 pagesNecessity of Big Data and Analytics For Good E-Governance: September 2017ArunNo ratings yet
- SCM and Outsourcing Postponement DecisionDocument21 pagesSCM and Outsourcing Postponement DecisionJorge Abrahim Concha RomeroNo ratings yet
- Crime PDFDocument12 pagesCrime PDFRohit ChandranNo ratings yet
- A.D. Patel Institute of TechnologyDocument17 pagesA.D. Patel Institute of TechnologyVanditNo ratings yet
- 5 Surbakti (2022) Understanding Effective Use of Big Data Challenges and CapabilitiesDocument14 pages5 Surbakti (2022) Understanding Effective Use of Big Data Challenges and CapabilitiesFeliks SejahteraNo ratings yet
- The Future of Big Data Analytics and Its Progress: November 2022Document10 pagesThe Future of Big Data Analytics and Its Progress: November 2022arul mamceNo ratings yet
- Stacked Generalization of Random Forest and Decision Tree Techniques For Library Data VisualizationDocument9 pagesStacked Generalization of Random Forest and Decision Tree Techniques For Library Data VisualizationIJEACS UKNo ratings yet
- Survey On Big Data AnalyticsDocument5 pagesSurvey On Big Data AnalyticsIJEACS UKNo ratings yet
- Ijercse BigdataDocument5 pagesIjercse BigdataDivi DivyaNo ratings yet
- Ls 5 Big Data VisualizationDocument7 pagesLs 5 Big Data VisualizationNikita MandhanNo ratings yet
- Data Modeling OverviewDocument18 pagesData Modeling OverviewAnonymous PmIBWPEw67No ratings yet
- Proposed System Using HadoopDocument13 pagesProposed System Using Hadooppratima depaNo ratings yet
- A Study On Big Data Modeling Techniques: ArticleDocument9 pagesA Study On Big Data Modeling Techniques: Articlesoffian hj usopNo ratings yet
- C - 6 Journal of Critical Reviews CLOUD COMPUTING AND BIG DATA A COMPREHENSIVE ANALYSISDocument6 pagesC - 6 Journal of Critical Reviews CLOUD COMPUTING AND BIG DATA A COMPREHENSIVE ANALYSISNazima BegumNo ratings yet
- Business Intelligence & Big Data Analytics-CSE3124YDocument25 pagesBusiness Intelligence & Big Data Analytics-CSE3124YsplokbovNo ratings yet
- Dont Do ThatDocument30 pagesDont Do ThatAmit SinghNo ratings yet
- Data Mining Applications and Feature Scope SurveyDocument5 pagesData Mining Applications and Feature Scope SurveyNIET Journal of Engineering & Technology(NIETJET)No ratings yet
- Big Data Tools-An Overview: ArticleDocument16 pagesBig Data Tools-An Overview: ArticleAdzan YogaNo ratings yet
- Journal of Business Research: Uthayasankar Sivarajah, Muhammad Mustafa Kamal, Zahir Irani, Vishanth WeerakkodyDocument24 pagesJournal of Business Research: Uthayasankar Sivarajah, Muhammad Mustafa Kamal, Zahir Irani, Vishanth Weerakkodyreshma k.sNo ratings yet
- Visual Informatics: Aindrila Ghosh, Mona Nashaat, James Miller, Shaikh Quader, Chad MarstonDocument19 pagesVisual Informatics: Aindrila Ghosh, Mona Nashaat, James Miller, Shaikh Quader, Chad MarstonFatima NoorNo ratings yet
- Next Generation Smart Manufacturing and Service Systems Using Big Data AnalyticsDocument13 pagesNext Generation Smart Manufacturing and Service Systems Using Big Data AnalyticsaliNo ratings yet
- FAIR Machine Learning Model Pipeline ImplementatioDocument32 pagesFAIR Machine Learning Model Pipeline ImplementatioAli MondayNo ratings yet
- A Study of Big Data Characteristics: October 2016Document5 pagesA Study of Big Data Characteristics: October 2016Johnny AndreatyNo ratings yet
- RoleofBigDataandPredictiveAnalyticsV1 60-RevisedDocument34 pagesRoleofBigDataandPredictiveAnalyticsV1 60-RevisedJon ChanNo ratings yet
- An Iterative Methodology For Defining Big DataDocument20 pagesAn Iterative Methodology For Defining Big DataGUSTAVO ADOLFO MELGAREJO ZELAYANo ratings yet
- Business Research JournalDocument24 pagesBusiness Research Journalzeeshan761No ratings yet
- Proposal (BigData)Document9 pagesProposal (BigData)Chanakya ResearchNo ratings yet
- Evolution of Big Data and Tools For Big DataDocument9 pagesEvolution of Big Data and Tools For Big Datalu09No ratings yet
- C - B D A - A S C R F D: Loud Based IG ATA Nalytics Urvey of Urrent Esearch and Uture IrectionsDocument12 pagesC - B D A - A S C R F D: Loud Based IG ATA Nalytics Urvey of Urrent Esearch and Uture Irectionsprayas jhariyaNo ratings yet
- Big Data Analytics Importance, Challenges, Categories, Techniques, and Tools (Article) Author Sarah Alswedani, Mostafa SalehDocument9 pagesBig Data Analytics Importance, Challenges, Categories, Techniques, and Tools (Article) Author Sarah Alswedani, Mostafa SalehVar arpNo ratings yet
- Introduction To Big Data Analytics: Welcome Intro To BDA !Document39 pagesIntroduction To Big Data Analytics: Welcome Intro To BDA !galge turoNo ratings yet
- Ogbuke N 2022, 28, Big DataDocument16 pagesOgbuke N 2022, 28, Big DataQuynh MyNo ratings yet
- 10 1108 - MD 09 2021 1199Document28 pages10 1108 - MD 09 2021 1199JULIO TORREJON CASTILLONo ratings yet
- Big Data and Five V's CharacteristicsDocument9 pagesBig Data and Five V's CharacteristicsFrancisco AraújoNo ratings yet
- Big Data PaperDocument8 pagesBig Data PaperNazira SardarNo ratings yet
- Performance Analysis of Machine Learning Algorithms For Big Data Classification ML and AI Based Algorithms For Big Data AnalysisDocument16 pagesPerformance Analysis of Machine Learning Algorithms For Big Data Classification ML and AI Based Algorithms For Big Data AnalysisAaditya Prabal ChawlaNo ratings yet
- The Impact of Bonuses and Increments On Employees Retention: April 2020Document20 pagesThe Impact of Bonuses and Increments On Employees Retention: April 2020dhruvin bhanushaliNo ratings yet
- Web User Experience and Consumer Behaviour: The in Uence of Colour, Usability and Aesthetics On The Consumer Buying BehaviourDocument10 pagesWeb User Experience and Consumer Behaviour: The in Uence of Colour, Usability and Aesthetics On The Consumer Buying Behaviourdhruvin bhanushaliNo ratings yet
- The Impact of Internal Marketing On Internal Service Quality: A Case Study in A Jordanian Pharmaceutical CompanyDocument13 pagesThe Impact of Internal Marketing On Internal Service Quality: A Case Study in A Jordanian Pharmaceutical Companydhruvin bhanushaliNo ratings yet
- Data Science, Big Data and Statistics: Test April 2019Document44 pagesData Science, Big Data and Statistics: Test April 2019dhruvin bhanushaliNo ratings yet
- FULLTEXT02Document142 pagesFULLTEXT02dhruvin bhanushaliNo ratings yet
- Global Production Networks Realizing The PotentialDocument44 pagesGlobal Production Networks Realizing The Potentialdhruvin bhanushaliNo ratings yet
- KPMG's JP en Asean M&a 2019Document5 pagesKPMG's JP en Asean M&a 2019VINA FAUZIA NURAININo ratings yet
- Big Data Oman PDFDocument6 pagesBig Data Oman PDFAshwiniNo ratings yet
- Fixing The Insurance Industry - CCDocument13 pagesFixing The Insurance Industry - CCManish KumarNo ratings yet
- Final - Huawei - ProjectDocument87 pagesFinal - Huawei - ProjectSheraz KhanNo ratings yet
- (ME Computer Science and Engineering) : Structure of Post GraduateDocument43 pages(ME Computer Science and Engineering) : Structure of Post GraduatePiyush BhatiaNo ratings yet
- Risk AnalysisDocument13 pagesRisk Analysisdawood sadiq janjuaNo ratings yet
- Big Data AnalyticsDocument8 pagesBig Data AnalyticsNoamanNo ratings yet
- The Rise of Big Data On Cloud ComputingDocument18 pagesThe Rise of Big Data On Cloud ComputingLaiNo ratings yet
- Big Data Dan Cloud ComputingDocument19 pagesBig Data Dan Cloud ComputingKarenNo ratings yet
- Machine Learning and OLAP On Big COVID-19 DataDocument10 pagesMachine Learning and OLAP On Big COVID-19 DatasamadNo ratings yet
- Amudhan VenkatesanDocument6 pagesAmudhan Venkatesanramesh158No ratings yet
- Crim Digests Article 12Document18 pagesCrim Digests Article 12Lee Dumalaga CarinanNo ratings yet
- Book ListDocument6 pagesBook ListAnagha PranjapeNo ratings yet
- PEF2019 - AVEVA - Sebastien Ory - Panel 3Document20 pagesPEF2019 - AVEVA - Sebastien Ory - Panel 3Nina KonitatNo ratings yet
- CSE121Document8 pagesCSE121Vedanth PradhanNo ratings yet
- What Is Big Data?: EnterDocument20 pagesWhat Is Big Data?: EnterDaniela StaciNo ratings yet
- Java Major - Ieee - 2023-24Document5 pagesJava Major - Ieee - 2023-24Devi Reddy Maheswara ReddyNo ratings yet
- 01 IntroductionDocument71 pages01 IntroductionRahul VenkatNo ratings yet
- 1.01 - Guardium Data Protection OverviewDocument20 pages1.01 - Guardium Data Protection OverviewishtiaqNo ratings yet
- Private EMR China Business PlanDocument81 pagesPrivate EMR China Business PlanDelelegn EmwodewNo ratings yet