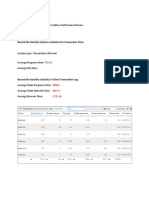
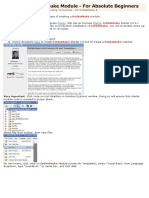
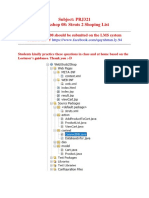
You might also like
- BW Guide and Best PracticesDocument41 pagesBW Guide and Best PracticesAsk Satwaliya100% (1)
- Arcserve UDP Network Ports - Draft - v6 PDFDocument6 pagesArcserve UDP Network Ports - Draft - v6 PDFrccNo ratings yet
- Mimix PDFDocument46 pagesMimix PDFNikith TulasiNo ratings yet
- Working With Triggers in A MySQL Database PDFDocument8 pagesWorking With Triggers in A MySQL Database PDFI Made Dwijaya MalehNo ratings yet
- Using Rails Shortcuts For HTML Controls: Text - Field - TagDocument34 pagesUsing Rails Shortcuts For HTML Controls: Text - Field - TagsundharNo ratings yet
- Cs 502 Lab Manual FinalDocument27 pagesCs 502 Lab Manual FinalAmit Kumar SahuNo ratings yet
- 1-MongoDB (3 Files Merged)Document7 pages1-MongoDB (3 Files Merged)papapawan2018No ratings yet
- Service Oriented Architecture LabDocument39 pagesService Oriented Architecture LabpjxrajNo ratings yet
- Data Base Security PDFDocument38 pagesData Base Security PDFBharathiNo ratings yet
- Eee MCT Mech Dbms CIA 2 QBDocument9 pagesEee MCT Mech Dbms CIA 2 QBSukhee SakthivelNo ratings yet
- Stored Procedure in SQLDocument20 pagesStored Procedure in SQLMuhammad NazirNo ratings yet
- 3rd Year3Sim DB Group Assignment Biruk Ermiast ID 0059-15 WeekendDocument13 pages3rd Year3Sim DB Group Assignment Biruk Ermiast ID 0059-15 WeekendAyele MitkuNo ratings yet
- Working With Triggers in A MySQL Database PDFDocument10 pagesWorking With Triggers in A MySQL Database PDFI Made Dwijaya MalehNo ratings yet
- NGT PracticalDocument18 pagesNGT PracticalShreya KaleNo ratings yet
- Practice 14 - Using Module J Action J and Client Identifier AttributesDocument13 pagesPractice 14 - Using Module J Action J and Client Identifier AttributesRamy AlyNo ratings yet
- University Database QueriesDocument14 pagesUniversity Database QueriesTHALAPATHY THALAPATHYNo ratings yet
- SQL TestDocument10 pagesSQL TestGautam KatlaNo ratings yet
- ServiceNow Performance ReviewDocument26 pagesServiceNow Performance ReviewRizwanNo ratings yet
- Question Paper About ProcedureDocument9 pagesQuestion Paper About ProcedureBIDHU BHUSAN KARNo ratings yet
- Lesson9 Linq 2019Document48 pagesLesson9 Linq 2019Zain Alabeeden AlarejiNo ratings yet
- Stored Procedure & TFDocument19 pagesStored Procedure & TFKarthik MNo ratings yet
- Essentials of Information and Technology File: Submittedto: SubmittedbyDocument30 pagesEssentials of Information and Technology File: Submittedto: SubmittedbySK KashyapNo ratings yet
- Mehak DbmsDocument21 pagesMehak Dbmsbmehak154No ratings yet
- Add Default ListItem to DropDownList in ASP.NETDocument6 pagesAdd Default ListItem to DropDownList in ASP.NETSonal WaliaNo ratings yet
- Linq 2019 PDFDocument47 pagesLinq 2019 PDFZain Alabeeden AlarejiNo ratings yet
- Creating A DNN ModuleDocument23 pagesCreating A DNN ModuleTiago BarbosaNo ratings yet
- Custom Validators in ASPDocument133 pagesCustom Validators in ASPRaghu GowdaNo ratings yet
- Filters in angularJS PDFDocument11 pagesFilters in angularJS PDFBella andyNo ratings yet
- DBMS Lab FileDocument43 pagesDBMS Lab Fileprabhu bhaktiNo ratings yet
- TestDocument22 pagesTestsurendharNo ratings yet
- Final ExamDocument33 pagesFinal ExamLidia MartaNo ratings yet
- Lab #11 WorksheetDocument3 pagesLab #11 WorksheetMehdi TalbiNo ratings yet
- PL/SQL - TriggersDocument15 pagesPL/SQL - TriggersSheba ParimalaNo ratings yet
- ADO.netDocument64 pagesADO.netKumar AnupamNo ratings yet
- DBS Ia2Document10 pagesDBS Ia2Calvin JoshuaNo ratings yet
- Chapter 7 PDFDocument67 pagesChapter 7 PDFosama mallohNo ratings yet
- Simulado para o Exame 70 Pt1Document11 pagesSimulado para o Exame 70 Pt1momonarikunNo ratings yet
- Dbms Lab FileDocument31 pagesDbms Lab Filesaqlain4462No ratings yet
- Dot Net Core - LabDocument30 pagesDot Net Core - LabSashank BogatiNo ratings yet
- MCQ3 15thDocument71 pagesMCQ3 15thDONA MONDALNo ratings yet
- Creating Configuration Manager 2007 Reports in SQL Server Management StudioDocument12 pagesCreating Configuration Manager 2007 Reports in SQL Server Management Studiopmk78No ratings yet
- Rdbms FinalDocument22 pagesRdbms FinalSriji VijayNo ratings yet
- Team 1 Report-1Document16 pagesTeam 1 Report-1Pervaiz AkhterNo ratings yet
- Mern NotesDocument10 pagesMern NotesAysha HarisNo ratings yet
- Teradata Advanced SQL Part1 PDFDocument38 pagesTeradata Advanced SQL Part1 PDFBiswadip Seth100% (2)
- Workshop08 PRJ321 Tran PDFDocument20 pagesWorkshop08 PRJ321 Tran PDFHà Nguyễn HậuNo ratings yet
- Stored ProcedureDocument6 pagesStored ProcedureNikunj Jhala100% (1)
- Q1 What Is The Difference Between @HTML - Textbox, @HTML - Textboxfor & @HTML - EditorforDocument7 pagesQ1 What Is The Difference Between @HTML - Textbox, @HTML - Textboxfor & @HTML - EditorforSilent SeekerNo ratings yet
- MVC MaterialDocument58 pagesMVC MaterialSrikant GummadiNo ratings yet
- SQL Server Interview StoryDocument6 pagesSQL Server Interview Storydesmond999No ratings yet
- What Is A DatabaseDocument4 pagesWhat Is A DatabaseJohn HeilNo ratings yet
- TreeView Control From The DatabaseDocument5 pagesTreeView Control From The DatabaseJayant ChouguleNo ratings yet
- K L University Department of Computer Science & Engineering II/IV B.Tech Semester II Database Management Systems (13CS204) TEST-2 KeyDocument8 pagesK L University Department of Computer Science & Engineering II/IV B.Tech Semester II Database Management Systems (13CS204) TEST-2 KeyRami ReddyNo ratings yet
- K L University Department of Computer Science & Engineering II/IV B.Tech Semester II Database Management Systems (13CS204) TEST-2 KeyDocument8 pagesK L University Department of Computer Science & Engineering II/IV B.Tech Semester II Database Management Systems (13CS204) TEST-2 KeyRami ReddyNo ratings yet
- Informatica LabDocument34 pagesInformatica Lab20pandey27100% (2)
- Worklight - DB2 - Database Connectivity With CRUD OperationsDocument13 pagesWorklight - DB2 - Database Connectivity With CRUD Operationsbhuvangates100% (1)
- STORED PROCEDURE INSERTDocument5 pagesSTORED PROCEDURE INSERTAhmed SartajNo ratings yet
- OGG HandsOnLabDocument11 pagesOGG HandsOnLabnt29No ratings yet
- Let's Code CRUDQ and Function Import Oper PDFDocument23 pagesLet's Code CRUDQ and Function Import Oper PDFPrashanth KumarNo ratings yet
- Chapter 6 Distributed System ManagementDocument12 pagesChapter 6 Distributed System ManagementabrehamNo ratings yet
- Oracle Goldengate Online TrainingDocument13 pagesOracle Goldengate Online TrainingVeronikaNo ratings yet
- C - Bobip - 42 Sap Certified Application Associate - Sap Businessobjects Business Intelligence Platform 4.2Document18 pagesC - Bobip - 42 Sap Certified Application Associate - Sap Businessobjects Business Intelligence Platform 4.2Bach MrNo ratings yet
- Web Based Distributed SystemDocument25 pagesWeb Based Distributed Systemkimchen edenelleNo ratings yet
- Distributed Database - Unit 5Document4 pagesDistributed Database - Unit 5PreethiVenkateswaranNo ratings yet
- HP Sssu CommandsDocument11 pagesHP Sssu Commandspega_001No ratings yet
- 1 IntroductionDocument42 pages1 IntroductionAnime StudioNo ratings yet
- ESGS Software UMN v2.1 PDFDocument364 pagesESGS Software UMN v2.1 PDFcross_of_northNo ratings yet
- 3.3 ERP Configuration For Replication: SAP Best PracticesDocument7 pages3.3 ERP Configuration For Replication: SAP Best PracticesSai BodduNo ratings yet
- A Guide To SQL Server 2000 Transactional and Snapshot ReplicationDocument86 pagesA Guide To SQL Server 2000 Transactional and Snapshot ReplicationIsmail Adha KesumaNo ratings yet
- Attunity Reference Guide PDFDocument686 pagesAttunity Reference Guide PDFTarigNo ratings yet
- Galera Cluster Best Practices for Multi-Master ReplicationDocument115 pagesGalera Cluster Best Practices for Multi-Master ReplicationJackey LinNo ratings yet
- Best Practices For Scaling Java Applications With Distributed CachingDocument84 pagesBest Practices For Scaling Java Applications With Distributed CachingAravind.rapuruNo ratings yet
- Top 10 Best Practices Vsphere BackupsDocument13 pagesTop 10 Best Practices Vsphere BackupsCarlos MezaNo ratings yet
- FSA Server ConsolidationDocument19 pagesFSA Server ConsolidationKarelmeuletrekkerNo ratings yet
- Hitachi Replication ManagerDocument604 pagesHitachi Replication Managerharishkanand9350No ratings yet
- h10741 VNX Data Movers WP PDFDocument28 pagesh10741 VNX Data Movers WP PDFChristian CutaranNo ratings yet
- SLT in SAP HANA SAP SOURCE SYSTEMDocument7 pagesSLT in SAP HANA SAP SOURCE SYSTEMamcreddyNo ratings yet
- Q Rep DB2 OracleDocument34 pagesQ Rep DB2 OracleRamchandra RaikarNo ratings yet
- EMC VNX Series: Release 7.1Document66 pagesEMC VNX Series: Release 7.1Hernan RaviolNo ratings yet
- Fact Sheets - Data DirectorDocument2 pagesFact Sheets - Data DirectorthisisonlygoingtobeatestNo ratings yet
- Azure Resiliency - Business Continuity - Disaster Rec PDFDocument31 pagesAzure Resiliency - Business Continuity - Disaster Rec PDFDavid F MartinezNo ratings yet
- SnapMirror SE TrainingDocument121 pagesSnapMirror SE TrainingtungNo ratings yet
- E20-393.examcollection - Premium.exam.69q: Number: E20-393 Passing Score: 800 Time Limit: 120 Min File Version: 1.0Document43 pagesE20-393.examcollection - Premium.exam.69q: Number: E20-393 Passing Score: 800 Time Limit: 120 Min File Version: 1.0EndeeeNo ratings yet
- Datasheet SharePlexDocument2 pagesDatasheet SharePlexBruno PóvoaNo ratings yet
- Mastering OpenStack - Sample ChapterDocument43 pagesMastering OpenStack - Sample ChapterPackt PublishingNo ratings yet
- DDBMS True FalseDocument7 pagesDDBMS True FalseAbdul WaheedNo ratings yet
- Hints Computer System DesignDocument27 pagesHints Computer System Designgeorgiua100% (1)