You might also like
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- 02-Random Variables (2)Document77 pages02-Random Variables (2)AbirhaNo ratings yet
- Lecture03 Discrete Random Variables Ver1Document37 pagesLecture03 Discrete Random Variables Ver1Hongjiang ZhangNo ratings yet
- Random Variables: Presented by in Stochastic Analysis and Inverse ModellingDocument21 pagesRandom Variables: Presented by in Stochastic Analysis and Inverse ModellingAndres Pino100% (1)
- TranscribeDocument5 pagesTranscribeSoumyadip MondalNo ratings yet
- 02-Random VariablesDocument62 pages02-Random VariablesHaftamu HilufNo ratings yet
- 02-Random VariablesDocument62 pages02-Random VariablesAklilu AyeleNo ratings yet
- STAT 342 Statistical Methods For EngineersDocument26 pagesSTAT 342 Statistical Methods For EngineersHamzaBaigNo ratings yet
- Chapter 7 EngDocument59 pagesChapter 7 Engmactar PiotrowskiNo ratings yet
- Probability Distributions.: AMS570 Lecture Notes #2Document7 pagesProbability Distributions.: AMS570 Lecture Notes #2azkaNo ratings yet
- OptimalLinearFilters PDFDocument107 pagesOptimalLinearFilters PDFAbdalmoedAlaiashyNo ratings yet
- 02-Random VariablesDocument51 pages02-Random VariablesGetahun Shanko KefeniNo ratings yet
- 1.017/1.010 Class 11 Multivariate Probability: Multiple Random VariablesDocument3 pages1.017/1.010 Class 11 Multivariate Probability: Multiple Random VariablesDr. Ir. R. Didin Kusdian, MT.No ratings yet
- Business Stat & Emetrics101Document38 pagesBusiness Stat & Emetrics101kasimNo ratings yet
- UNIT II Probability TheoryDocument84 pagesUNIT II Probability TheoryaymanNo ratings yet
- Chapter 5 Functions of Random VariablesDocument29 pagesChapter 5 Functions of Random VariablesAssimi DembéléNo ratings yet
- Discrete, Continuous and Mixed Random VariablesDocument9 pagesDiscrete, Continuous and Mixed Random VariablesIrma DenaNo ratings yet
- Chapter - Two: Random VariablesDocument37 pagesChapter - Two: Random Variablesየእውነት መንገድNo ratings yet
- Multivariate DistributionsDocument8 pagesMultivariate DistributionsArima AckermanNo ratings yet
- Statistics BI: Models of Random Outcomes. What Is A Model?Document22 pagesStatistics BI: Models of Random Outcomes. What Is A Model?Pedro GouvNo ratings yet
- PPT3 - Statistical Models in SimulationDocument38 pagesPPT3 - Statistical Models in SimulationRizky AmandaNo ratings yet
- PROBABILITY 03 Rv-Dist-Moments 5 8Document21 pagesPROBABILITY 03 Rv-Dist-Moments 5 8DeepanshuNo ratings yet
- Continuous Random Variables ExplainedDocument39 pagesContinuous Random Variables ExplainedJose Leonardo Simancas GarciaNo ratings yet
- Chapter 5Document21 pagesChapter 5ashytendaiNo ratings yet
- Chapter 3-2857Document8 pagesChapter 3-2857Kevin FontynNo ratings yet
- ProbabilityDocument28 pagesProbabilitytamann2004No ratings yet
- Random Variables PDFDocument64 pagesRandom Variables PDFdeelipNo ratings yet
- Probability & RV Lec 11 & 12Document58 pagesProbability & RV Lec 11 & 12areebarajpoot0453879No ratings yet
- EE 561 Communication Theory Spring 2003Document27 pagesEE 561 Communication Theory Spring 2003Mohamed Ziad AlezzoNo ratings yet
- Distribution Function of A Random Variable: X If X IfDocument8 pagesDistribution Function of A Random Variable: X If X IfNomad Soul MusicNo ratings yet
- Chapter5 PDFDocument37 pagesChapter5 PDFAreeba AshrafNo ratings yet
- Normal DistributionDocument15 pagesNormal DistributionMarcLorenz OrtegaNo ratings yet
- Chapter II. Random SignalsDocument31 pagesChapter II. Random SignalsXelaNo ratings yet
- MIT18 S096F13 Lecnote3Document7 pagesMIT18 S096F13 Lecnote3Yacim GenNo ratings yet
- Probability Formula SheetDocument11 pagesProbability Formula SheetJake RoosenbloomNo ratings yet
- Digital Communications: Lecture Notes by Y. N. TrivediDocument5 pagesDigital Communications: Lecture Notes by Y. N. Trivedimeet261998No ratings yet
- Random Variable Modified PDFDocument19 pagesRandom Variable Modified PDFIMdad HaqueNo ratings yet
- QueueingPart1 Rev5 WinDocument83 pagesQueueingPart1 Rev5 WinBini YamNo ratings yet
- Parameter EstimationDocument34 pagesParameter EstimationJose Leonardo Simancas GarciaNo ratings yet
- Random Signal Analysis LectureDocument16 pagesRandom Signal Analysis LecturebalkyderNo ratings yet
- Part 2 - Probability Distribution FunctionsDocument31 pagesPart 2 - Probability Distribution FunctionsSabrinaFuschettoNo ratings yet
- Addis Ababa Science & Technology University Department of Electrical & Computer EngineeringDocument63 pagesAddis Ababa Science & Technology University Department of Electrical & Computer EngineeringObsi EliasNo ratings yet
- Unit 5 - Mathematics III - www.rgpvnotes.inDocument26 pagesUnit 5 - Mathematics III - www.rgpvnotes.inmishranitesh25072004No ratings yet
- UntitledDocument17 pagesUntitledSITHESWARAN SELVAMNo ratings yet
- Discrete Probability Distribution Chapter3Document47 pagesDiscrete Probability Distribution Chapter3TARA NATH POUDELNo ratings yet
- Probability & Cumulative Distribution Functions: Yatin VasavaDocument39 pagesProbability & Cumulative Distribution Functions: Yatin Vasavadilawar sumraNo ratings yet
- Probability Distributions in RDocument42 pagesProbability Distributions in RNaski KuafniNo ratings yet
- Indicator functions and expected values explainedDocument10 pagesIndicator functions and expected values explainedPatricio Antonio VegaNo ratings yet
- Random Variables and Probability DistributionDocument73 pagesRandom Variables and Probability Distributionkelihe8947No ratings yet
- Random Variables: Distributions, Expectations and PropertiesDocument74 pagesRandom Variables: Distributions, Expectations and PropertiesAshwani SharmaNo ratings yet
- Chapter 4Document31 pagesChapter 4惠洁No ratings yet
- Lecture 7Document6 pagesLecture 7Agha Zeeshan Khan SoomroNo ratings yet
- Ds 5Document26 pagesDs 5Giozy OradeaNo ratings yet
- Ma2261 Probability And Random Processes: ω: X (ω) ≤ x x ∈ RDocument17 pagesMa2261 Probability And Random Processes: ω: X (ω) ≤ x x ∈ RSivabalanNo ratings yet
- 11 - Queing Theory Part 1Document31 pages11 - Queing Theory Part 1sairamNo ratings yet
- Econ 140 (Spring 2018) - Section 1: 1 Random Variable (RV)Document7 pagesEcon 140 (Spring 2018) - Section 1: 1 Random Variable (RV)Mashiat MutmainnahNo ratings yet
- تلخيص احتمالات 1Document16 pagesتلخيص احتمالات 1samNo ratings yet
- DiscreteDistributions SAKAIDocument18 pagesDiscreteDistributions SAKAIBrian ZambeziNo ratings yet
- Chapitre 2Document6 pagesChapitre 2chihabhliwaNo ratings yet
- Lecture 10Document22 pagesLecture 10ruff ianNo ratings yet
- ZXONE 8300&8500&8700 Acceptance Test Guide - R1.7Document152 pagesZXONE 8300&8500&8700 Acceptance Test Guide - R1.7Felipe Ignacio Lopez GordilloNo ratings yet
- Emergency Fairlite LightingDocument3 pagesEmergency Fairlite LightingawadalmekawyNo ratings yet
- Q3 Science 5 Periodical Test Questions No HeadingDocument4 pagesQ3 Science 5 Periodical Test Questions No HeadingWea Joy Mantolino-MasNo ratings yet
- Ch02-Zealey PRE 4thppDocument67 pagesCh02-Zealey PRE 4thppMuhammad Kashif RashidNo ratings yet
- Tip 127Document4 pagesTip 127pingontronicNo ratings yet
- Air-Stable and Volatile Bis (Pyridylalkenolato) - Sanjay MathurDocument5 pagesAir-Stable and Volatile Bis (Pyridylalkenolato) - Sanjay MathurGanesh BabuNo ratings yet
- Energy Systems and Resources ExplainedDocument22 pagesEnergy Systems and Resources ExplainedTayani Tedson KumwendaNo ratings yet
- Tehnicni Program SESSION 2018Document34 pagesTehnicni Program SESSION 2018kenlavie2No ratings yet
- Function of Several VariablesDocument4 pagesFunction of Several VariablesKedhar Nadh GadiboinaNo ratings yet
- Electric Traction - ReferenceDocument19 pagesElectric Traction - ReferenceShrestha SanjuNo ratings yet
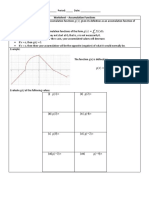
- Worksheet - Accumulation FunctionsDocument3 pagesWorksheet - Accumulation FunctionssteveNo ratings yet
- Me Lab 6Document9 pagesMe Lab 6BensoyNo ratings yet
- Aluminium Dome Roof InstallationDocument7 pagesAluminium Dome Roof Installationmuhammad.younisNo ratings yet
- Direct VariationDocument44 pagesDirect VariationMary Ann Rasco100% (1)
- ICRU Report No. 90 Key Data for Ionizing Radiation DosimetryDocument118 pagesICRU Report No. 90 Key Data for Ionizing Radiation DosimetryMarcusNo ratings yet
- Environmental friendly, energy saving LED well luminaireDocument9 pagesEnvironmental friendly, energy saving LED well luminaireAbhishek KumarNo ratings yet
- WEEKLY MODULE 1 Earth ScienceDocument1 pageWEEKLY MODULE 1 Earth Sciencemichael sto domingoNo ratings yet
- OMAE2015-41911: Rheological Properties of Oil Based Drilling Fluids and Base OilsDocument8 pagesOMAE2015-41911: Rheological Properties of Oil Based Drilling Fluids and Base OilskmskskqNo ratings yet
- Offer For 48V 700AH Li-Ion Battery PDFDocument1 pageOffer For 48V 700AH Li-Ion Battery PDFJosé MoralesNo ratings yet
- Dynamic Mechanical Analysis - WikipediaDocument8 pagesDynamic Mechanical Analysis - WikipediamohsenNo ratings yet
- 1 Motor Protection Single SessionDocument27 pages1 Motor Protection Single Sessionmubarakkirko100% (1)
- ITTC - Recommended Procedures and Guidelines: Experimental Wake Scaling MethodsDocument8 pagesITTC - Recommended Procedures and Guidelines: Experimental Wake Scaling MethodsajayNo ratings yet
- Spur Gears Component GeneratorDocument4 pagesSpur Gears Component GeneratorRodrigo NavarreteNo ratings yet
- The Chemistry of F Block ElementsDocument17 pagesThe Chemistry of F Block ElementsSana AjmalNo ratings yet
- BES 314 FINAL QUIZ TAKE HOMEDocument2 pagesBES 314 FINAL QUIZ TAKE HOMEahmad ryan0% (1)
- MPG-V1.1 Operating InstructionDocument7 pagesMPG-V1.1 Operating Instructionsea13No ratings yet
- Cabeçotes GE - US Convencional - bhcs39424 - Conventional - Probe - Catalog - r3 - 2Document47 pagesCabeçotes GE - US Convencional - bhcs39424 - Conventional - Probe - Catalog - r3 - 2Carlos WagnerNo ratings yet
- Mass S.Document17 pagesMass S.Yasasmi GunasekeraNo ratings yet
- SuspensionDocument72 pagesSuspensionUkash sukarmanNo ratings yet
- Vibrapac Maint PDFDocument211 pagesVibrapac Maint PDFJosé C. Canche DavidNo ratings yet