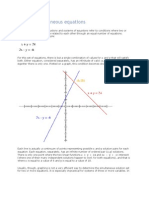
You might also like
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Equatons of Straight LineDocument7 pagesEquatons of Straight LineBilly CheungNo ratings yet
- Advanced AlgebraDocument20 pagesAdvanced AlgebraRems RecablancaNo ratings yet
- Equations 1. The Equation Formula: Mathg12 Euclid Stage 3 Class 1 NotesDocument8 pagesEquations 1. The Equation Formula: Mathg12 Euclid Stage 3 Class 1 NotesHappy DolphinNo ratings yet
- MA1513 Chapter 1 Lecture NoteDocument34 pagesMA1513 Chapter 1 Lecture NoteJustin NgNo ratings yet
- Kuttler LinearAlgebra AFirstCourse 2021A (020 040)Document21 pagesKuttler LinearAlgebra AFirstCourse 2021A (020 040)Fernanda Ortega LopezNo ratings yet
- Latest Part of Latest Notes 2024 FinalDocument2 pagesLatest Part of Latest Notes 2024 Finaljibapo5785No ratings yet
- Simultaneous EquationDocument10 pagesSimultaneous EquationsabbysamuraNo ratings yet
- B1 Lesson 8Document14 pagesB1 Lesson 8Montes Arianne A.No ratings yet
- System of Linear Equation and ApplicationDocument32 pagesSystem of Linear Equation and Applicationihsaanbava0% (1)
- Matrix AlgebraDocument46 pagesMatrix AlgebraPaul GeorgeNo ratings yet
- System of Linear EquationsDocument37 pagesSystem of Linear EquationsHucen Nashyd MohamedNo ratings yet
- Systems of NonDocument63 pagesSystems of Nonpramit04No ratings yet
- System of Linear Equations - Linear Algebra WithDocument37 pagesSystem of Linear Equations - Linear Algebra Withradhikaseelam1No ratings yet
- Assignment 1 SDocument7 pagesAssignment 1 SArc Angel Matias SerranoNo ratings yet
- Systems of Linear EquationsDocument9 pagesSystems of Linear Equationsprinkit patelNo ratings yet
- Linear Inequalities and Linear EquationsDocument11 pagesLinear Inequalities and Linear EquationsLuqman J. Cheema100% (1)
- Antonchap1 LinsystemsDocument23 pagesAntonchap1 Linsystemsapi-2612829520% (1)
- Systems of Linear Equations in Three Variables Extra CreditDocument7 pagesSystems of Linear Equations in Three Variables Extra CreditFleur BurnsNo ratings yet
- Linear Algebra Lecture Notes ch1Document10 pagesLinear Algebra Lecture Notes ch1Abdiqani Mohamed AdanNo ratings yet
- Linear Algebra Lecture Notes Ch3Document10 pagesLinear Algebra Lecture Notes Ch3Abdiqani Mohamed AdanNo ratings yet
- System of Linear EquationsDocument75 pagesSystem of Linear Equationsnoli_ediNo ratings yet
- Module 3 - B1Document21 pagesModule 3 - B1Agrida, Neitan Samuel R.No ratings yet
- BSI-111 Linear Algebra: Dr. Abid IqbalDocument30 pagesBSI-111 Linear Algebra: Dr. Abid IqbalHannan Sajjad JZ Batch 22No ratings yet
- System of Linear EquationsDocument13 pagesSystem of Linear EquationsKomal ShujaatNo ratings yet
- mst210 - Unit 12 - E1i1 PDFDocument57 pagesmst210 - Unit 12 - E1i1 PDFValdrin EjupiNo ratings yet
- Chapter 7 Systems of Nonlinear Diffe 2021 A Modern Introduction To DiffereDocument60 pagesChapter 7 Systems of Nonlinear Diffe 2021 A Modern Introduction To DiffereLJ AuNo ratings yet
- Systems of Equations ConceptDocument8 pagesSystems of Equations Conceptapi-126876773No ratings yet
- Systems of EquationsDocument51 pagesSystems of Equationsadampau1974No ratings yet
- Linear Equations: Unit 14 AND Euclidean SpacesDocument24 pagesLinear Equations: Unit 14 AND Euclidean SpacesRiddhima MukherjeeNo ratings yet
- Linear Equations in Two Variables: Table of ContentsDocument14 pagesLinear Equations in Two Variables: Table of ContentsJayson AbadNo ratings yet
- Algebra Course NotesDocument78 pagesAlgebra Course NotesMatthew RumleyNo ratings yet
- Ch1 Numerical Methods Lecture NotesDocument10 pagesCh1 Numerical Methods Lecture NotesAbdiqani Mohamed AdanNo ratings yet
- Basic Control System With Matlab ExamplesDocument19 pagesBasic Control System With Matlab ExamplesMostafa8425No ratings yet
- Math1070 130notes PDFDocument6 pagesMath1070 130notes PDFPrasad KharatNo ratings yet
- System of Linear EquationsDocument11 pagesSystem of Linear EquationsPaul ValdiviezoNo ratings yet
- L 1Document10 pagesL 1Paul Arne ØstværNo ratings yet
- Pre Calculus PrimerDocument17 pagesPre Calculus PrimeracsimsNo ratings yet
- LESSON 5 Systems of Linear EquationsDocument16 pagesLESSON 5 Systems of Linear EquationsMa RiaNo ratings yet
- The Sysytem of EquationsDocument24 pagesThe Sysytem of Equationsasadfarooqi4102No ratings yet
- Solving Simultaneous EquationsDocument12 pagesSolving Simultaneous EquationsLeanne ErasgaNo ratings yet
- Note 2Document20 pagesNote 2Jiasheng NiNo ratings yet
- Linear Algebra Group Presentation: Arsalan Ahmed, Zeeshan Karim, Syed Hasan Asim, Abeel Ahmed MinaiDocument22 pagesLinear Algebra Group Presentation: Arsalan Ahmed, Zeeshan Karim, Syed Hasan Asim, Abeel Ahmed MinaiArsalan AhmedNo ratings yet
- Linear Algebra FinalDocument43 pagesLinear Algebra FinalJhon Carlo DelmonteNo ratings yet
- Algeb Midterm-FinalDocument71 pagesAlgeb Midterm-FinalGreen zolarNo ratings yet
- PMA1014 - Linear Algebra Academic Year 2009/2010 Thomas Huettemann and Ivan TodorovDocument40 pagesPMA1014 - Linear Algebra Academic Year 2009/2010 Thomas Huettemann and Ivan TodorovTom DavisNo ratings yet
- Kramer's RuleDocument7 pagesKramer's RuleLurkermanguyNo ratings yet
- System of EquationsDocument32 pagesSystem of Equationsapi-20012397No ratings yet
- Solving Systems of Linear InequalitiesDocument2 pagesSolving Systems of Linear InequalitiesGlenn GalvezNo ratings yet
- Lecture1 PDFDocument6 pagesLecture1 PDFAnonymous ewKJI4xUNo ratings yet
- CE 403 Lecture 3Document9 pagesCE 403 Lecture 3akatsuki shiroNo ratings yet
- Two Variable Linear EquationDocument3 pagesTwo Variable Linear EquationEdelNo ratings yet
- Solving Systems of Equations: MATH 15-1 Linear Algebra Week 2Document53 pagesSolving Systems of Equations: MATH 15-1 Linear Algebra Week 2DK DMNo ratings yet
- Systems of Linear Equations Math 130 Linear AlgebraDocument4 pagesSystems of Linear Equations Math 130 Linear AlgebraCody SageNo ratings yet
- How To Solve An EquationDocument6 pagesHow To Solve An Equationapi-126876773No ratings yet
- Linear Systems: MATH 149 Linear Algebra With Computer ApplicationDocument53 pagesLinear Systems: MATH 149 Linear Algebra With Computer ApplicationMyca MoliNo ratings yet
- Lecture NotesDocument108 pagesLecture NotesjohnNo ratings yet
- Ch5 - Graphing Two EquationsDocument10 pagesCh5 - Graphing Two EquationsnikowawaNo ratings yet
- Matrix Unknowns RHSDocument8 pagesMatrix Unknowns RHSKhaled MaherNo ratings yet
- Paul's Online Notes: Ax + by P CX + Dy QDocument4 pagesPaul's Online Notes: Ax + by P CX + Dy QbenderNo ratings yet
- Suppression of Von Karman Vortex Streets Past PoDocument31 pagesSuppression of Von Karman Vortex Streets Past PoLuis PressoNo ratings yet
- 3D Lagrangian - Particle - Tracking - With - Multi-Pulse - SDocument2 pages3D Lagrangian - Particle - Tracking - With - Multi-Pulse - SLuis PressoNo ratings yet
- Lumped Element ModelDocument6 pagesLumped Element ModelLuis PressoNo ratings yet
- FFT Integration of Instantaneous 3D Pressure GradiDocument22 pagesFFT Integration of Instantaneous 3D Pressure GradiLuis PressoNo ratings yet
- Complex Numbers and Phasors in Polar or Rectangular FormDocument13 pagesComplex Numbers and Phasors in Polar or Rectangular FormLuis PressoNo ratings yet
- Electrons in MotionDocument5 pagesElectrons in MotionLuis PressoNo ratings yet
- AC Resistance and Impedance in An AC CircuitDocument6 pagesAC Resistance and Impedance in An AC CircuitLuis PressoNo ratings yet
- Linear Codes: Coding Theory and Its ApplicationsDocument23 pagesLinear Codes: Coding Theory and Its Applicationsjames-lawsonNo ratings yet
- AI Applications To Communications and Information Technologies - IEEE (2024)Document493 pagesAI Applications To Communications and Information Technologies - IEEE (2024)Mori TrumpNo ratings yet
- 1105 Pre-Class Assignment Week 1 (Functions)Document2 pages1105 Pre-Class Assignment Week 1 (Functions)DanielaNo ratings yet
- Lecture 17 - Piecewise Continuous Functions and Improper IntegralsDocument7 pagesLecture 17 - Piecewise Continuous Functions and Improper IntegralsTrần Hồng NgaNo ratings yet
- University of Dar Es Salaam College of Natural and Applied SciencesDocument9 pagesUniversity of Dar Es Salaam College of Natural and Applied SciencesMARYLUCY ASSENGANo ratings yet
- Trapezoidal RuleDocument19 pagesTrapezoidal RuleShawn GonzalesNo ratings yet
- VR14 14ME3603: Siddhartha Engineering CollegeDocument2 pagesVR14 14ME3603: Siddhartha Engineering CollegeVenkateshNo ratings yet
- Complexity Analysis of Algorithms (Greek For Greek)Document5 pagesComplexity Analysis of Algorithms (Greek For Greek)Nguyệt NguyệtNo ratings yet
- Neural Network Monitoring and Faults Diagnosis System Applied To The Vibrations Detection in Gas Turbine: Solar TITAN 130Document14 pagesNeural Network Monitoring and Faults Diagnosis System Applied To The Vibrations Detection in Gas Turbine: Solar TITAN 130Houcine BelhaskaNo ratings yet
- Churn ManagementDocument15 pagesChurn ManagementNeelanjan Biswas100% (1)
- By: Moataz Al-Haj: Vision Topics - Seminar (University of Haifa)Document69 pagesBy: Moataz Al-Haj: Vision Topics - Seminar (University of Haifa)subhashiNo ratings yet
- SSL MQDocument35 pagesSSL MQkarthickmsit100% (1)
- Encryption Using Lester Hill Cipher Algorithm: Thangarasu.N DR - Arul Lawrence SelvakumarDocument5 pagesEncryption Using Lester Hill Cipher Algorithm: Thangarasu.N DR - Arul Lawrence SelvakumarEhsan GhasisinNo ratings yet
- Cv7803 Numerical Methods FinalDocument3 pagesCv7803 Numerical Methods FinalJiye LiuNo ratings yet
- MAT1348 Assignment 3: 24 PointsDocument4 pagesMAT1348 Assignment 3: 24 PointsShuttlechairNo ratings yet
- Module 8 Inventory Excel TemplateDocument17 pagesModule 8 Inventory Excel TemplateENIDNo ratings yet
- How To Make Out-of-Sample Forecasts With ARIMA in Python: NavigationDocument58 pagesHow To Make Out-of-Sample Forecasts With ARIMA in Python: Navigationjmiheso2012No ratings yet
- Mapped ElementsDocument117 pagesMapped ElementsManish ShrikhandeNo ratings yet
- Linear Equations in Linear Algebra: Row Reduction and Echelon FormsDocument31 pagesLinear Equations in Linear Algebra: Row Reduction and Echelon FormsNajmul Puda PappadamNo ratings yet
- Ys 1700 SettingsDocument4 pagesYs 1700 SettingsvjNo ratings yet
- Homework 4Document4 pagesHomework 4Waleed Arshad0% (1)
- in The Bisection Method: X F X FDocument17 pagesin The Bisection Method: X F X Frenzon272No ratings yet
- Cheat SheetDocument20 pagesCheat SheetFąĎhiĽ セフィロスNo ratings yet
- 18AI71 - AAI INTERNAL 1 QB AnswersDocument14 pages18AI71 - AAI INTERNAL 1 QB AnswersSahithi BhashyamNo ratings yet
- Machine Learning (CSCI-567, Fall 2008) - Linear Discriminant AnalysisDocument32 pagesMachine Learning (CSCI-567, Fall 2008) - Linear Discriminant AnalysisAnonymous PlvU0LGNo ratings yet
- Block Diagram Algebra: Basic Connections For Blocks Series ConnectionDocument10 pagesBlock Diagram Algebra: Basic Connections For Blocks Series Connectionmohammed zaidNo ratings yet
- Application of Splay TreeDocument29 pagesApplication of Splay TreeArif Ahmed100% (1)
- CE 206: Engineering Computation Sessional Ordinary Differential Equations (ODE)Document23 pagesCE 206: Engineering Computation Sessional Ordinary Differential Equations (ODE)sazid alamNo ratings yet
- Western Constructions Case - MS15A051Document3 pagesWestern Constructions Case - MS15A051Anju SavithriNo ratings yet
- Uninformed SearchDocument45 pagesUninformed Searchyusifovyadigar1No ratings yet