You might also like
- String Algorithms in C: Efficient Text Representation and SearchFrom EverandString Algorithms in C: Efficient Text Representation and SearchNo ratings yet
- Python: Advanced Guide to Programming Code with Python: Python Computer Programming, #4From EverandPython: Advanced Guide to Programming Code with Python: Python Computer Programming, #4No ratings yet
- Implementation of N-Gram TechniqueDocument6 pagesImplementation of N-Gram Techniquelalitha sriNo ratings yet
- A Study Using N-Gram Features For Text CategorizationDocument10 pagesA Study Using N-Gram Features For Text CategorizationmynetmarNo ratings yet
- Top 10 NLP Question - AnswerDocument16 pagesTop 10 NLP Question - AnswerAvadhraj VermaNo ratings yet
- NLTK - N-Gram LMDocument13 pagesNLTK - N-Gram LMPavan KumarNo ratings yet
- CNN, RNN & HAN Text Classification ReportDocument15 pagesCNN, RNN & HAN Text Classification Reportpradeep_dhote9No ratings yet
- Multi-Output Classification With Machine LearningDocument10 pagesMulti-Output Classification With Machine Learningpanigrahisuman7No ratings yet
- Next Word Prediction With NLP and Deep LearningDocument13 pagesNext Word Prediction With NLP and Deep LearningAlebachew MekuriawNo ratings yet
- Neural NetworksDocument37 pagesNeural NetworksNAIMUL HASAN NAIMNo ratings yet
- Word Analysis Python ProgramsDocument10 pagesWord Analysis Python Programs20115016 HICET STUDENT AIMLNo ratings yet
- NLP For ML - Spam ClassifierDocument14 pagesNLP For ML - Spam ClassifierThomas WestNo ratings yet
- 6 - RNN LSTM & GruDocument14 pages6 - RNN LSTM & Gruabbas1999n8No ratings yet
- NLP Programming Assignment 1: Hidden Markov ModelsDocument4 pagesNLP Programming Assignment 1: Hidden Markov ModelsYuchenNo ratings yet
- Neural Lab 1Document5 pagesNeural Lab 1Bashar AsaadNo ratings yet
- COMP 4650 6490 Assignment 3 2023-v1.1Document6 pagesCOMP 4650 6490 Assignment 3 2023-v1.1390942959No ratings yet
- First ReportDocument14 pagesFirst Reportdnthrtm3No ratings yet
- Unit - 1: Write A Program To Demosnstrate Basic Data Type in PythonDocument31 pagesUnit - 1: Write A Program To Demosnstrate Basic Data Type in PythonMr raj SrivastavaNo ratings yet
- DL Mannual For ReferenceDocument58 pagesDL Mannual For ReferenceDevant PajgadeNo ratings yet
- Machine Learning Lab Manual 7Document8 pagesMachine Learning Lab Manual 7Raheel Aslam100% (1)
- Team Name - Codesmashers Team Members - Manmeet Singh Tuteja, Raghav GuptaDocument4 pagesTeam Name - Codesmashers Team Members - Manmeet Singh Tuteja, Raghav Guptamanmeet singh tutejaNo ratings yet
- Implementation of Time Series ForecastingDocument12 pagesImplementation of Time Series ForecastingSoba CNo ratings yet
- Experiment No. 9 TE SL-II (ANN)Document2 pagesExperiment No. 9 TE SL-II (ANN)RutujaNo ratings yet
- Long Short-Term Memory (LSTM) : 1. Problem StatementDocument6 pagesLong Short-Term Memory (LSTM) : 1. Problem StatementEmmanuel Lwele Lj JuniorNo ratings yet
- Pps Lab Manual ProgramsDocument5 pagesPps Lab Manual ProgramsAnusia SharmaNo ratings yet
- Mimpython 1Document6 pagesMimpython 1Rayhan KhanNo ratings yet
- Lab 08 - Data PreprocessingDocument9 pagesLab 08 - Data PreprocessingridaNo ratings yet
- Decap776 P 1Document6 pagesDecap776 P 1pb4444335No ratings yet
- Classification Algorithms IDocument14 pagesClassification Algorithms IJayod RajapakshaNo ratings yet
- MLE in StataDocument17 pagesMLE in StatavivipaufNo ratings yet
- Brainheaters Notes: Machine Learning PrioritiesDocument69 pagesBrainheaters Notes: Machine Learning PrioritiesjenNo ratings yet
- GloveDocument10 pagesGlovetareqeee15100% (1)
- Simple Guide To Optuna For Hyperparameters OptimizationTuningDocument29 pagesSimple Guide To Optuna For Hyperparameters OptimizationTuningRadha KilariNo ratings yet
- Speech emotion recognition with librosa: 72.4% accuracyDocument14 pagesSpeech emotion recognition with librosa: 72.4% accuracyNitish Kumar ChoudhuryNo ratings yet
- ASNM Program ExplainDocument4 pagesASNM Program ExplainKesehoNo ratings yet
- ML Classification Algorithms in PythonDocument32 pagesML Classification Algorithms in PythonMukul SharmaNo ratings yet
- LP 1 Lab Manual - v1Document80 pagesLP 1 Lab Manual - v1Diptesh ThakareNo ratings yet
- Sparse autoencoder implementation for natural imagesDocument5 pagesSparse autoencoder implementation for natural imagesJoseNo ratings yet
- A 02Document2 pagesA 02dsaNo ratings yet
- Over Description About The ModelDocument3 pagesOver Description About The Modelwww.santhoshvjd123No ratings yet
- Lecture 5 - Multi-Layer Feedforward Neural Networks Using Matlab Part 1Document4 pagesLecture 5 - Multi-Layer Feedforward Neural Networks Using Matlab Part 1meazamaliNo ratings yet
- AI_Manual (1)Document36 pagesAI_Manual (1)Dev SejvaniNo ratings yet
- Image Captioning Project Report AnalyzedDocument10 pagesImage Captioning Project Report AnalyzedaliNo ratings yet
- Represented Using Tensors, and As A Result, Neural Network Programming UtilizesDocument32 pagesRepresented Using Tensors, and As A Result, Neural Network Programming UtilizesYogesh KrishnaNo ratings yet
- AI Phash 5Document14 pagesAI Phash 5techusama4No ratings yet
- DsatextDocument69 pagesDsatextAyush SharmaNo ratings yet
- CNN Text ClassificationDocument12 pagesCNN Text Classification孙亚童No ratings yet
- Programming and Computer Application Practices: Wildan Aghniya 17063048Document5 pagesProgramming and Computer Application Practices: Wildan Aghniya 17063048wildan aghniyaNo ratings yet
- Scikit LearnDocument17 pagesScikit LearnRRNo ratings yet
- kerasDocument3 pageskerasmagas32862No ratings yet
- ProjectReport KanwarpalDocument17 pagesProjectReport KanwarpalKanwarpal SinghNo ratings yet
- PYTHON UNIT 2Document8 pagesPYTHON UNIT 2Prajwal TilekarNo ratings yet
- PatternDocument1 pagePatternahmadkhalilNo ratings yet
- NLP RecordDocument6 pagesNLP Recordnuzzurockzz301No ratings yet
- Ebook To Become ML EngineerDocument21 pagesEbook To Become ML Engineerమయూ ఖNo ratings yet
- Understand The Softmax Function in Minutes: Data Science BootcampDocument15 pagesUnderstand The Softmax Function in Minutes: Data Science BootcampVikash RryderNo ratings yet
- Deep Learning AssignmentDocument8 pagesDeep Learning AssignmentDiriba SaboNo ratings yet
- DATA STRUCTURE NotesDocument101 pagesDATA STRUCTURE Notesrockmeena127No ratings yet
- Deep Learning Lab (1)Document20 pagesDeep Learning Lab (1)6005 Saraswathi. BNo ratings yet
- ANLPDocument7 pagesANLPMuneesh BajpaiNo ratings yet
- Amasidda Majjagi: Ref No:RPGS-MP/03 Date: 07/01/2023 National President (Booth Management)Document2 pagesAmasidda Majjagi: Ref No:RPGS-MP/03 Date: 07/01/2023 National President (Booth Management)ASHU KNo ratings yet
- Pandit Jagdish Sharma: National President M-1/5 Rajiv Market, Shukurpur, Britaniya Chowk, Delhi-110034Document1 pagePandit Jagdish Sharma: National President M-1/5 Rajiv Market, Shukurpur, Britaniya Chowk, Delhi-110034ASHU KNo ratings yet
- Internship Report SHAHBAZDocument10 pagesInternship Report SHAHBAZASHU KNo ratings yet
- Hotel Indore Mayur Dec 22Document19 pagesHotel Indore Mayur Dec 22ASHU KNo ratings yet
- My ResumeDocument2 pagesMy ResumeASHU KNo ratings yet
- Ref No:RPGS-UDC/33 Date: 22/12/2022 National President (Booth Management)Document2 pagesRef No:RPGS-UDC/33 Date: 22/12/2022 National President (Booth Management)ASHU KNo ratings yet
- Pandit Jagdish Sharma: Amasidda MajjagiDocument1 pagePandit Jagdish Sharma: Amasidda MajjagiASHU KNo ratings yet
- My ResumeDocument2 pagesMy ResumeASHU KNo ratings yet
- School ManagmentDocument25 pagesSchool ManagmentASHU KNo ratings yet
- Internship Report SHAHBAZDocument10 pagesInternship Report SHAHBAZASHU KNo ratings yet
- School ManagmentDocument25 pagesSchool ManagmentASHU KNo ratings yet
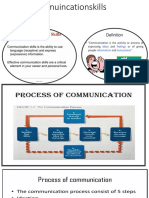
- Com U in Cation SkillsDocument6 pagesCom U in Cation SkillsASHU KNo ratings yet
- Restaurant Managment Sakshat Shrivatra 222Document25 pagesRestaurant Managment Sakshat Shrivatra 222ASHU KNo ratings yet
- Restaurant Managment Sakshat Shrivatra 222Document25 pagesRestaurant Managment Sakshat Shrivatra 222ASHU KNo ratings yet
- Cs MuskanDocument1 pageCs MuskanASHU KNo ratings yet
- Conservation of Natural ResoursesDocument6 pagesConservation of Natural ResoursesASHU KNo ratings yet
- Vinay Yadav Expence 26 Dec To 31decDocument2 pagesVinay Yadav Expence 26 Dec To 31decASHU KNo ratings yet
- An Shika ResumeDocument1 pageAn Shika ResumeASHU KNo ratings yet
- The Impact of PM Housing SchemeDocument85 pagesThe Impact of PM Housing SchemeASHU KNo ratings yet
- Vinay Yadav Expence 26 Dec To 31decDocument2 pagesVinay Yadav Expence 26 Dec To 31decASHU KNo ratings yet
- Enterpenership DevelopementDocument6 pagesEnterpenership DevelopementASHU KNo ratings yet
- Vinay Yadav Expence 26 Dec To 31decDocument2 pagesVinay Yadav Expence 26 Dec To 31decASHU KNo ratings yet
- Final Internship ReportDocument218 pagesFinal Internship ReportASHU KNo ratings yet
- The Impact of PM Housing SchemeDocument82 pagesThe Impact of PM Housing SchemeASHU KNo ratings yet
- Pdf&rendition 1Document2 pagesPdf&rendition 1ASHU KNo ratings yet
- Particulars Amount Advance Fees A/C - 5000.00 Tuition Fee 15000.00 Book Bank 1100.00 Bus Fees 10000.00 T & P 1500.00 Late Fee 2500.00Document1 pageParticulars Amount Advance Fees A/C - 5000.00 Tuition Fee 15000.00 Book Bank 1100.00 Bus Fees 10000.00 T & P 1500.00 Late Fee 2500.00ASHU KNo ratings yet
- Photowalk AssignmentDocument8 pagesPhotowalk AssignmentASHU KNo ratings yet
- The Impact of PM Housing SchemeDocument85 pagesThe Impact of PM Housing SchemeASHU KNo ratings yet
- O2DE19DCE1127Document6 pagesO2DE19DCE1127ASHU KNo ratings yet
- Lokesh Kumar ChoukseyDocument2 pagesLokesh Kumar ChoukseyASHU KNo ratings yet
- Neutron SourcesDocument64 pagesNeutron SourcesJenodi100% (1)
- Mycophenolic Acid Chapter-1Document34 pagesMycophenolic Acid Chapter-1NabilaNo ratings yet
- Samsung RAM Product Guide Feb 11Document24 pagesSamsung RAM Product Guide Feb 11Javed KhanNo ratings yet
- Lesson 2Document10 pagesLesson 2angeliquefaithemnaceNo ratings yet
- 3 Manacsa&Tan 2012 Strong Republic SidetrackedDocument41 pages3 Manacsa&Tan 2012 Strong Republic SidetrackedGil Osila JaradalNo ratings yet
- Public OpinionDocument7 pagesPublic OpinionSona Grewal100% (1)
- Search Engine Marketing Course Material 2t4d9Document165 pagesSearch Engine Marketing Course Material 2t4d9Yoga Guru100% (2)
- Orion C.M. HVAC Case Study-07.25.23Document25 pagesOrion C.M. HVAC Case Study-07.25.23ledmabaya23No ratings yet
- Winter's Bracing Approach RevisitedDocument5 pagesWinter's Bracing Approach RevisitedJitendraNo ratings yet
- 2 Integrated MarketingDocument13 pages2 Integrated MarketingPaula Marin CrespoNo ratings yet
- CAFA Open House HighlightsDocument1 pageCAFA Open House HighlightsDaniel LaiNo ratings yet
- Rolls-Royce M250 FIRST Network: 2015 Customer Support DirectoryDocument76 pagesRolls-Royce M250 FIRST Network: 2015 Customer Support Directoryale11vigarNo ratings yet
- Heather Bianco 2016 Resume Revised PDFDocument3 pagesHeather Bianco 2016 Resume Revised PDFapi-316610725No ratings yet
- Villanueva Poetry Analysis Template BSEE 35Document7 pagesVillanueva Poetry Analysis Template BSEE 35CHRISTIAN MAHINAYNo ratings yet
- Natural GasDocument86 pagesNatural GasNikhil TiwariNo ratings yet
- Reprocessing Guide: Shaver Handpiece TrayDocument198 pagesReprocessing Guide: Shaver Handpiece TrayAnne Stephany ZambranoNo ratings yet
- Ginglen 2022 - Necrotizing Enterocolitis - StatPearlsDocument8 pagesGinglen 2022 - Necrotizing Enterocolitis - StatPearlsBee GuyNo ratings yet
- Ventilator Modes - WEANINGDocument3 pagesVentilator Modes - WEANINGAlaa OmarNo ratings yet
- Cla IdmaDocument160 pagesCla Idmacurotto1953No ratings yet
- Audio Narration SINGLE Slide: Google Form in The Discussion ForumDocument2 pagesAudio Narration SINGLE Slide: Google Form in The Discussion Forumfast sayanNo ratings yet
- 2023 Catalog Score SummerDocument65 pages2023 Catalog Score Summermadhudasa0% (2)
- Mark Wildon - Representation Theory of The Symmetric Group (Lecture Notes) (2015)Document34 pagesMark Wildon - Representation Theory of The Symmetric Group (Lecture Notes) (2015)Satyam Agrahari0% (1)
- Ap4955 PDFDocument4 pagesAp4955 PDFGilvan HenriqueNo ratings yet
- Creating Literacy Instruction For All Students ResourceDocument25 pagesCreating Literacy Instruction For All Students ResourceNicole RickettsNo ratings yet
- Notes (Net) para Sa KritikaDocument4 pagesNotes (Net) para Sa KritikaClaire CastillanoNo ratings yet
- Sem Iii Sybcom Finacc Mang AccDocument6 pagesSem Iii Sybcom Finacc Mang AccKishori KumariNo ratings yet
- Raiseyourvoice SFDocument26 pagesRaiseyourvoice SFAttila Engin100% (1)
- Technical Information System Overview Prosafe-Com 3.00 Prosafe-ComDocument49 pagesTechnical Information System Overview Prosafe-Com 3.00 Prosafe-Comshekoofe danaNo ratings yet
- Basketball 2011: Johnson CountyDocument25 pagesBasketball 2011: Johnson CountyctrnewsNo ratings yet
- School of Education, Arts and Sciences General Education Area 1 SEMESTER S.Y 2021-2022Document4 pagesSchool of Education, Arts and Sciences General Education Area 1 SEMESTER S.Y 2021-2022JaylordPalattaoNo ratings yet