You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Kongre Programi PDFDocument3 pagesKongre Programi PDFsonficyusNo ratings yet
- Kongre Programi PDFDocument3 pagesKongre Programi PDFsonficyusNo ratings yet
- Productflyer 42461Document1 pageProductflyer 42461sonficyusNo ratings yet
- 2b Sozlu Sunum2Document7 pages2b Sozlu Sunum2sonficyusNo ratings yet
- Quantitative Leaching of A Nigerian Iron Ore in HyDocument7 pagesQuantitative Leaching of A Nigerian Iron Ore in HysonficyusNo ratings yet
- +10mm 60sn ReportDocument5 pages+10mm 60sn ReportsonficyusNo ratings yet
- StrongNilateriteleachCMQ1974133485 93Document10 pagesStrongNilateriteleachCMQ1974133485 93sonficyusNo ratings yet
- Iron Ore Otation With Environmentally Friendly ReagentsDocument8 pagesIron Ore Otation With Environmentally Friendly ReagentssonficyusNo ratings yet
- Recovery of Permanent Magnets Type Ndfeb From WeeeDocument13 pagesRecovery of Permanent Magnets Type Ndfeb From WeeesonficyusNo ratings yet
- Leaching and Recovery of Rare-Earth Elements FromDocument18 pagesLeaching and Recovery of Rare-Earth Elements FromsonficyusNo ratings yet
- CRT Pyrometallurgical Hydrometallurgical e WasteDocument33 pagesCRT Pyrometallurgical Hydrometallurgical e WastesonficyusNo ratings yet
- Removal of Basic Dyes From Wastewater by Using Natural Zeolite - Kinetic and Equilibrium Studies (#312307) - 322549Document10 pagesRemoval of Basic Dyes From Wastewater by Using Natural Zeolite - Kinetic and Equilibrium Studies (#312307) - 322549sonficyusNo ratings yet
- Controllable Synthesis of MN O Nanowires and Application in The Treatment of Phenol at Room TemperatureDocument9 pagesControllable Synthesis of MN O Nanowires and Application in The Treatment of Phenol at Room TemperaturesonficyusNo ratings yet
- THESis)Document1 pageTHESis)sonficyusNo ratings yet
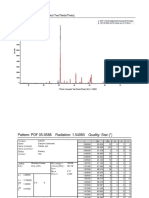
- PDF 11-0078 Camg (Co3) 2 Dolomite PDF 05-0586 Caco3 Calcite, Syn 11.9% MajorDocument3 pagesPDF 11-0078 Camg (Co3) 2 Dolomite PDF 05-0586 Caco3 Calcite, Syn 11.9% MajorsonficyusNo ratings yet
- Metal Recovery From Spent Samarium Cobalt Magnets UsingDocument7 pagesMetal Recovery From Spent Samarium Cobalt Magnets UsingsonficyusNo ratings yet
- PDF 11-0078 Camg (Co3) 2 Dolomite PDF 05-0586 Caco3 Calcite, Syn 11.9% MajorDocument3 pagesPDF 11-0078 Camg (Co3) 2 Dolomite PDF 05-0586 Caco3 Calcite, Syn 11.9% MajorsonficyusNo ratings yet
- PDF 11-0078 Camg (Co3) 2 Dolomite 97.8% Major PDF 05-0586 Caco3 Calcite, Syn 2.2% MinorDocument3 pagesPDF 11-0078 Camg (Co3) 2 Dolomite 97.8% Major PDF 05-0586 Caco3 Calcite, Syn 2.2% MinorsonficyusNo ratings yet
- PDF 11-0078 Camg (Co3) 2 Dolomite 95.3% Major PDF 05-0586 Caco3 Calcite, Syn 4.7% MinorDocument3 pagesPDF 11-0078 Camg (Co3) 2 Dolomite 95.3% Major PDF 05-0586 Caco3 Calcite, Syn 4.7% MinorsonficyusNo ratings yet
- Waste management laws and importance of recyclingDocument31 pagesWaste management laws and importance of recyclingsonficyusNo ratings yet
- E WastesDocument6 pagesE WastessonficyusNo ratings yet
- PDF 11-0078 Camg (Co3) 2 Dolomite 95.3% Major PDF 05-0586 Caco3 Calcite, Syn 4.7% MinorDocument3 pagesPDF 11-0078 Camg (Co3) 2 Dolomite 95.3% Major PDF 05-0586 Caco3 Calcite, Syn 4.7% MinorsonficyusNo ratings yet
- Dissolving Zinc From Smithsonite Mineral by Direct Leaching MethodDocument12 pagesDissolving Zinc From Smithsonite Mineral by Direct Leaching MethodsonficyusNo ratings yet
- Materials 13 02528 ConcreteDocument18 pagesMaterials 13 02528 ConcretesonficyusNo ratings yet
- Bangladesh TitaniumDocument6 pagesBangladesh TitaniumsonficyusNo ratings yet
- Conversion of magnetic units between Gaussian, SI and rationalized MKSA systemsDocument1 pageConversion of magnetic units between Gaussian, SI and rationalized MKSA systemsRichster LofrancoNo ratings yet
- Upgrading Specularite Ore Using Wet Magnetic Separation and Reverse FlotationDocument8 pagesUpgrading Specularite Ore Using Wet Magnetic Separation and Reverse FlotationsonficyusNo ratings yet
- Study On The Gravity Processing of Manganese Ores: Asian Journal of ChemistryDocument7 pagesStudy On The Gravity Processing of Manganese Ores: Asian Journal of ChemistrysonficyusNo ratings yet
- IMPS 2014 Program (Printed Version)Document16 pagesIMPS 2014 Program (Printed Version)sonficyusNo ratings yet
- 121-Ugong Issue 5.2 - FINAL - Doc - With Corrections-2nd RevisionDocument16 pages121-Ugong Issue 5.2 - FINAL - Doc - With Corrections-2nd RevisionMarq QoNo ratings yet
- L27 - Optical Measuring InstrumentsDocument14 pagesL27 - Optical Measuring Instrumentschaitanyamohod2020No ratings yet
- This Study Resource WasDocument6 pagesThis Study Resource WasRian RorresNo ratings yet
- Chapter 4 Duality and Post Optimal AnalysisDocument37 pagesChapter 4 Duality and Post Optimal AnalysisMir Md Mofachel HossainNo ratings yet
- Manual For The Implementation of International Development Cooperation Projects of SloveniaDocument7 pagesManual For The Implementation of International Development Cooperation Projects of SloveniarefikrosicNo ratings yet
- Selection of Materials For Cutting ToolsDocument21 pagesSelection of Materials For Cutting ToolsKarthick NNo ratings yet
- GT Protection Type TestDocument24 pagesGT Protection Type Testashwani2101100% (1)
- Modern Coating Additives for SustainabilityDocument8 pagesModern Coating Additives for Sustainabilitynano100% (1)
- Remote Environment: - Concern The Nature and Direction of Economy in Which A Firm Operates - Types of FactorsDocument27 pagesRemote Environment: - Concern The Nature and Direction of Economy in Which A Firm Operates - Types of FactorsmikiyingNo ratings yet
- Engleza Cls A 11 A A VarDocument4 pagesEngleza Cls A 11 A A VarMariusEc0No ratings yet
- Contoh Kurikulum Vitae PDFDocument8 pagesContoh Kurikulum Vitae PDFANDI2lusNo ratings yet
- Performance Appraisal at UFLEX Ltd.Document29 pagesPerformance Appraisal at UFLEX Ltd.Mohit MehraNo ratings yet
- Ideal Home - Complete Guide To Christmas 2016 PDFDocument148 pagesIdeal Home - Complete Guide To Christmas 2016 PDFpetru555100% (2)
- North American Free Trade Agreement: Prof. MakhmoorDocument15 pagesNorth American Free Trade Agreement: Prof. MakhmoorShikha ShuklaNo ratings yet
- English Letter WritingDocument2 pagesEnglish Letter WritingSundarNo ratings yet
- Resolution No. 100 - Ease of Doing BusinessDocument2 pagesResolution No. 100 - Ease of Doing BusinessTeamBamAquinoNo ratings yet
- Tutorial 6 - SolutionsDocument8 pagesTutorial 6 - SolutionsNguyễn Phương ThảoNo ratings yet
- DL 57 PDFDocument2 pagesDL 57 PDFmaheshm_erpNo ratings yet
- The Threat Landscape Quiz ResultsDocument5 pagesThe Threat Landscape Quiz ResultsKaskusemail88 EmailNo ratings yet
- Petron Corporate PresentationDocument46 pagesPetron Corporate Presentationsivuonline0% (1)
- QuizDocument5 pagesQuizReuven GunawanNo ratings yet
- Boiler Tube LeakageDocument20 pagesBoiler Tube LeakageSayan AichNo ratings yet
- Installation and User's Guide InformixDocument52 pagesInstallation and User's Guide Informixissa912721No ratings yet
- ODMP Hydrology and Water Resources Inception ReportDocument68 pagesODMP Hydrology and Water Resources Inception ReportAse JohannessenNo ratings yet
- 1 Introduction To Electrical DrivesDocument45 pages1 Introduction To Electrical DrivesSetya Ardhi67% (3)
- Akd 736103113213Document1 pageAkd 736103113213May'Axel RomaricNo ratings yet
- RFPDocument88 pagesRFPJayaram Peggem P0% (1)
- Literature Review On School AdministrationDocument6 pagesLiterature Review On School Administrationea7sfn0f100% (1)
- Edmonton Report On Flood MitigationDocument6 pagesEdmonton Report On Flood MitigationAnonymous TdomnV9OD4No ratings yet
- Chapter 6-Trial Balance and Rectification of Errors Previous QuestionsDocument12 pagesChapter 6-Trial Balance and Rectification of Errors Previous Questionscrescenthss vanimalNo ratings yet