You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5806)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (842)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (589)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Press Tool Theory One Marks Q & ADocument48 pagesPress Tool Theory One Marks Q & ASantosh Paple100% (11)
- CBSE Class 10 Maths NotesDocument7 pagesCBSE Class 10 Maths NotesLori GuerraNo ratings yet
- Grade 3 Mental Maths Worksheet 1 1Document2 pagesGrade 3 Mental Maths Worksheet 1 1Lori GuerraNo ratings yet
- Grade 2 Mental Maths Worksheet 2Document2 pagesGrade 2 Mental Maths Worksheet 2Lori GuerraNo ratings yet
- Grade 2 Mental Maths Worksheet 3Document2 pagesGrade 2 Mental Maths Worksheet 3Lori GuerraNo ratings yet
- Grade 4 Mental Maths Subtraction Worksheet 1Document2 pagesGrade 4 Mental Maths Subtraction Worksheet 1Lori GuerraNo ratings yet
- Grade 4 Mental Maths Multiplication Worksheet 1Document2 pagesGrade 4 Mental Maths Multiplication Worksheet 1Lori GuerraNo ratings yet
- The SARIMAX Model: Full Name: Short DescriptionDocument7 pagesThe SARIMAX Model: Full Name: Short DescriptionLori GuerraNo ratings yet
- MLA TAB Lecture1Document81 pagesMLA TAB Lecture1Lori GuerraNo ratings yet
- 46 - 811MAInfAR1Document11 pages46 - 811MAInfAR1Lori GuerraNo ratings yet
- MLA TAB Lecture3Document70 pagesMLA TAB Lecture3Lori GuerraNo ratings yet
- MLA TAB Lecture2Document84 pagesMLA TAB Lecture2Lori GuerraNo ratings yet
- Data Set DescriptionDocument5 pagesData Set DescriptionLori GuerraNo ratings yet
- Cracking Bgcse PhysicsDocument96 pagesCracking Bgcse Physicstmoatshe96No ratings yet
- Las-Gen - Chem2 - WK1 - 2Document32 pagesLas-Gen - Chem2 - WK1 - 2Evelyn AndosonNo ratings yet
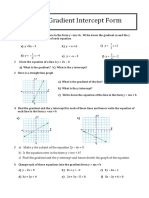
- Gradient Intercept FormDocument3 pagesGradient Intercept FormsaadNo ratings yet
- Properties of Electric Charges, Electric ForceDocument44 pagesProperties of Electric Charges, Electric ForceDyan NavarroNo ratings yet
- Mechanical Engineering Department, IST, IslamabadDocument9 pagesMechanical Engineering Department, IST, Islamabadengr2487No ratings yet
- NDT Summary-Steam Turbine InspectionDocument5 pagesNDT Summary-Steam Turbine InspectionOm Ar TanNo ratings yet
- Lecture 08 - ME 243 - Helical SpringsDocument14 pagesLecture 08 - ME 243 - Helical Springssalmanalamj5No ratings yet
- David HumeDocument5 pagesDavid HumeEric StoneNo ratings yet
- All India Test Series For JEE (Advanced) 2024 (For CRP)Document4 pagesAll India Test Series For JEE (Advanced) 2024 (For CRP)Atharva SrivastavaNo ratings yet
- Capstone Project First Quarter: Week 1Document5 pagesCapstone Project First Quarter: Week 1Martee Gozun100% (1)
- Scanning Rate Enhancement of Leaky Wave Antennas Using Slow-Wave Substrate Integrated Waveguide (SIW) StructureDocument6 pagesScanning Rate Enhancement of Leaky Wave Antennas Using Slow-Wave Substrate Integrated Waveguide (SIW) StructureMohamed MOUMOUNo ratings yet
- Chap 1 - Crystalline & Noncrystalline StructureDocument55 pagesChap 1 - Crystalline & Noncrystalline StructureJordan ThongNo ratings yet
- Books Doubtnut Question BankDocument260 pagesBooks Doubtnut Question Bankrohan sinhaNo ratings yet
- Bernoulli Numbers and Polynomials: T. Muthukumar Tmk@iitk - Ac.in 17 Jun 2014Document7 pagesBernoulli Numbers and Polynomials: T. Muthukumar Tmk@iitk - Ac.in 17 Jun 2014Destructive InterferenceNo ratings yet
- Student Mentoring Infographics by SlidesgoDocument26 pagesStudent Mentoring Infographics by SlidesgoDarmanNo ratings yet
- Class: XII Session: 2020-2021 Subject: Physics Sample Question Paper (Theory)Document10 pagesClass: XII Session: 2020-2021 Subject: Physics Sample Question Paper (Theory)Hritik JaiswalNo ratings yet
- Design Modeling and Control of A Wall CL PDFDocument6 pagesDesign Modeling and Control of A Wall CL PDFRam KumarNo ratings yet
- Low Cement Dense Castables / Calcestruzzi Densi A Basso Cemento / Betons Denses A Basse Teneur en Ciment / Dichte Lc-BetoneDocument2 pagesLow Cement Dense Castables / Calcestruzzi Densi A Basso Cemento / Betons Denses A Basse Teneur en Ciment / Dichte Lc-Betoneasad razaNo ratings yet
- Co3 LPDocument8 pagesCo3 LPChiara Yasmin HanduganNo ratings yet
- Energies 13 04560Document20 pagesEnergies 13 04560Jay KayeNo ratings yet
- Lagrange Mechanics I: Presented By: Amir Patel PHD (Mechatronics) Cape TownDocument29 pagesLagrange Mechanics I: Presented By: Amir Patel PHD (Mechatronics) Cape TownDaniel JonesNo ratings yet
- Objective Question Bank (NDT)Document22 pagesObjective Question Bank (NDT)Syed FarhanNo ratings yet
- Monoslope Wind NSCP - PDF - Windward and Leeward - WoundDocument13 pagesMonoslope Wind NSCP - PDF - Windward and Leeward - WoundAicel RegenciaNo ratings yet
- Radiography Procedure RNDTDocument27 pagesRadiography Procedure RNDTrashmibetuNo ratings yet
- Shear Capacity Prediction of Confined Masonry Walls Subjected To Cyclic Lateral LoadingDocument14 pagesShear Capacity Prediction of Confined Masonry Walls Subjected To Cyclic Lateral LoadingJalal KeNo ratings yet
- Constraints On Seismic Velocities in The Earth From TraveltimesDocument17 pagesConstraints On Seismic Velocities in The Earth From TraveltimesDigta FernandoNo ratings yet
- Geometry Final 2020Document30 pagesGeometry Final 2020Sergio Cuautle JuarezNo ratings yet
- Dr. Ayman Abd El-Hamid - Performance Based Design of StructuresDocument58 pagesDr. Ayman Abd El-Hamid - Performance Based Design of Structuresعبدالرحمن النجدي100% (1)
- Electrodynamics Introduction: Electrodynamics - Final Exams RevisionDocument27 pagesElectrodynamics Introduction: Electrodynamics - Final Exams RevisionThabelo NgwenyaNo ratings yet