You might also like
- Demystifying Big Data RGc1.0Document10 pagesDemystifying Big Data RGc1.0Nandan Kumar100% (1)
- Business AnalyticsDocument46 pagesBusiness AnalyticsMuhammed Althaf VK100% (3)
- Business Analytics-ReviewerDocument5 pagesBusiness Analytics-ReviewerAzi MendozaNo ratings yet
- The Influence of Big Data Analytics in The IndustryDocument15 pagesThe Influence of Big Data Analytics in The IndustrymikhailovaelyaNo ratings yet
- 1 hMATLAB - Simulink - TutorialDocument12 pages1 hMATLAB - Simulink - TutorialWasimNo ratings yet
- Test 8Document6 pagesTest 8Robert KegaraNo ratings yet
- Data LineageDocument14 pagesData Lineagejohn949No ratings yet
- Big Data Analytics NotesDocument117 pagesBig Data Analytics NotesARYAN GUPTANo ratings yet
- BIG Data Analysis Assign - FinalDocument21 pagesBIG Data Analysis Assign - FinalBehailu DemissieNo ratings yet
- Pyton PDFDocument6 pagesPyton PDFGame WorldNo ratings yet
- BIG DATA Technology: SubtitleDocument34 pagesBIG DATA Technology: SubtitleDhavan KumarNo ratings yet
- Data Warehousing AssignmentDocument9 pagesData Warehousing AssignmentRushil Nagwan100% (2)
- Unit 1Document22 pagesUnit 1Vishal ShivhareNo ratings yet
- Ccs 334Document16 pagesCcs 334Amsaveni .amsaveniNo ratings yet
- BigData, Data Mining and Machine Learning Ch1&2Document5 pagesBigData, Data Mining and Machine Learning Ch1&2aswagadaNo ratings yet
- Module 1Document35 pagesModule 1Jha JeeNo ratings yet
- Data AnalyticsDocument5 pagesData AnalyticsLen FCNo ratings yet
- Big Data AnalyticsDocument64 pagesBig Data AnalyticsSameer MemonNo ratings yet
- Hidden Patterns, Unknown Correlations, Market Trends, Customer Preferences and Other Useful Information That Can Help Organizations Make More-Informed Business DecisionsDocument4 pagesHidden Patterns, Unknown Correlations, Market Trends, Customer Preferences and Other Useful Information That Can Help Organizations Make More-Informed Business DecisionsPolukanti GouthamkrishnaNo ratings yet
- Big Data History: Ideal Institute of TechnologyDocument11 pagesBig Data History: Ideal Institute of TechnologyAbhi Stan LeeNo ratings yet
- Unit-1-Part1-Big Data Analytics and ToolsDocument12 pagesUnit-1-Part1-Big Data Analytics and ToolsAlekhya AbbarajuNo ratings yet
- Unit 4 LTDocument16 pagesUnit 4 LTSahil KumarNo ratings yet
- Unit 1Document19 pagesUnit 1thakursahabonhunt1No ratings yet
- Big Data: Presented By, Nishaa RDocument24 pagesBig Data: Presented By, Nishaa RNishaaNo ratings yet
- Big DataDocument6 pagesBig DataDivyasriNo ratings yet
- Data Warehousing ManagementDocument7 pagesData Warehousing Managementtricia quilangNo ratings yet
- Mittal School of Business: Course Code: CAP348 Course Title: Introduction To Big DataDocument6 pagesMittal School of Business: Course Code: CAP348 Course Title: Introduction To Big DataNitin PatidarNo ratings yet
- MIS Ch. No. 3Document62 pagesMIS Ch. No. 3sgsoniNo ratings yet
- Mittal School of Business: Course Code: CAP348 Course Title: Introduction To Big DataDocument6 pagesMittal School of Business: Course Code: CAP348 Course Title: Introduction To Big DataNitin PatidarNo ratings yet
- Describe The Data Processing Chain: Business UnderstandingDocument4 pagesDescribe The Data Processing Chain: Business UnderstandingTHAATNo ratings yet
- 1 - Introduction To Data ScienceDocument6 pages1 - Introduction To Data ScienceDaniel VasconcellosNo ratings yet
- Chapter - 2 - Data ScienceDocument32 pagesChapter - 2 - Data Scienceaschalew woldeyesusNo ratings yet
- Answers For Sessional 1 BDADocument11 pagesAnswers For Sessional 1 BDAkumarchaturvedulaNo ratings yet
- Emerging TechnologyDocument18 pagesEmerging TechnologyGudeta nNo ratings yet
- Bda Aiml Note Unit 1Document14 pagesBda Aiml Note Unit 1viswakranthipalagiriNo ratings yet
- Big DataDocument10 pagesBig DataJorge GrubeNo ratings yet
- Book Big Data TechnologyDocument87 pagesBook Big Data TechnologyAnish shahNo ratings yet
- Big DataDocument3 pagesBig Datanam trầnNo ratings yet
- 2nd Sem MIS MB0047Document9 pages2nd Sem MIS MB0047pandey_hariom12No ratings yet
- BIG DATA & Hadoop TutorialDocument23 pagesBIG DATA & Hadoop Tutorialsaif salahNo ratings yet
- Unit I Introduction To Data Science SyllabusDocument10 pagesUnit I Introduction To Data Science Syllabusswetha karthigeyanNo ratings yet
- Hand Book: Ahmedabad Institute of TechnologyDocument103 pagesHand Book: Ahmedabad Institute of TechnologyBhavik SangharNo ratings yet
- BMIS Chapter 4 SCMSBDocument35 pagesBMIS Chapter 4 SCMSBNainika ReddyNo ratings yet
- Relation Between Big: Data and BusinessDocument4 pagesRelation Between Big: Data and Businessعمار طعمةNo ratings yet
- BDA Unit 1Document22 pagesBDA Unit 1pl.babyshalini palanisamyNo ratings yet
- Data Science Vs Big DataDocument34 pagesData Science Vs Big Datapoi.tamrakarNo ratings yet
- Cloud & Big DataDocument5 pagesCloud & Big DataHenish KananiNo ratings yet
- Datamining 2Document5 pagesDatamining 2Manoj ManuNo ratings yet
- QB Bda SolutionDocument46 pagesQB Bda SolutionAvinashNo ratings yet
- Chapter TwoDocument14 pagesChapter TwoTade GaromaNo ratings yet
- DSBDA EndSem2023 12F FlyHighDocument20 pagesDSBDA EndSem2023 12F FlyHighakshaydeolasi00eNo ratings yet
- Emerging Chapter 2Document22 pagesEmerging Chapter 2nuri mohammedNo ratings yet
- Data Analytics For Ioe: SyllabusDocument23 pagesData Analytics For Ioe: SyllabusTejal DeshpandeNo ratings yet
- Module 1Document21 pagesModule 1johnsonjoshal5No ratings yet
- Big Data and Data Analysis: Offurum Paschal I Kunoch Education and Training College, OwerriDocument35 pagesBig Data and Data Analysis: Offurum Paschal I Kunoch Education and Training College, OwerriSixtus OkoroNo ratings yet
- Basic of Intelligence BusinessDocument5 pagesBasic of Intelligence BusinessDhivena JeonNo ratings yet
- Data Analyst Interview QuestionsDocument28 pagesData Analyst Interview Questionssomya.anime.007No ratings yet
- 12 01 09 10 32 12 1287 Sindhujam PDFDocument23 pages12 01 09 10 32 12 1287 Sindhujam PDFPrasad DhanikondaNo ratings yet
- Big Data AnalysisDocument30 pagesBig Data AnalysisAdithya GutthaNo ratings yet
- Arpit Garg 00913302717 SLS 6Document5 pagesArpit Garg 00913302717 SLS 6Subject LearningNo ratings yet
- Big Data Analytics On Large Scale Shared Storage System: University of Computer Studies, Yangon, MyanmarDocument7 pagesBig Data Analytics On Large Scale Shared Storage System: University of Computer Studies, Yangon, MyanmarKyar Nyo AyeNo ratings yet
- Big Data for Beginners: Data at Scale. Harnessing the Potential of Big Data AnalyticsFrom EverandBig Data for Beginners: Data at Scale. Harnessing the Potential of Big Data AnalyticsNo ratings yet
- Databackupandrecovery6 1800x1800Document1 pageDatabackupandrecovery6 1800x1800TKKNo ratings yet
- Databackupandrecovery5 1800x1800Document2 pagesDatabackupandrecovery5 1800x1800TKKNo ratings yet
- IT BC DR PolicyDocument7 pagesIT BC DR PolicyTKKNo ratings yet
- Staying Competitive During A PandemicDocument8 pagesStaying Competitive During A PandemicTKKNo ratings yet
- RecoverNXT FlyerDocument4 pagesRecoverNXT FlyerTKKNo ratings yet
- Data Protection and Data Disposal Policy - Posp1718010Document10 pagesData Protection and Data Disposal Policy - Posp1718010TKKNo ratings yet
- Big Data Internal 2 Answers-1-9Document9 pagesBig Data Internal 2 Answers-1-9TKKNo ratings yet
- Big Data Internal 2 AnswersDocument9 pagesBig Data Internal 2 AnswersTKKNo ratings yet
- Internal 3 AnswerDocument10 pagesInternal 3 AnswerTKKNo ratings yet
- INTERNAL 2-ANS-CCT-Cloud ComputingTechnologiesDocument10 pagesINTERNAL 2-ANS-CCT-Cloud ComputingTechnologiesTKKNo ratings yet
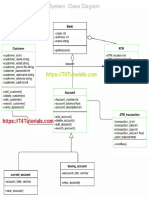
- Bank Management System Class DiagramDocument1 pageBank Management System Class DiagramTKKNo ratings yet
- Correction form-OTQ733542497 PDFDocument1 pageCorrection form-OTQ733542497 PDFTKKNo ratings yet
- MFL39754855 - Owners Manual & Installation ManualDocument2 pagesMFL39754855 - Owners Manual & Installation ManualTKKNo ratings yet
- Applications of Digital Communication PDFDocument19 pagesApplications of Digital Communication PDFSaif AhmedNo ratings yet
- Sanjay Mali: Citizenship: Indian Date of Birth: 30 May 1991Document4 pagesSanjay Mali: Citizenship: Indian Date of Birth: 30 May 1991Sandesh AhirNo ratings yet
- Mealy and Moore MachinesDocument20 pagesMealy and Moore MachinesSHRUTI SRIDHAR 20BCE1405No ratings yet
- Sem Unp Lab ProgramsDocument39 pagesSem Unp Lab ProgramsEnduku MeekuNo ratings yet
- ACW Manual v3Document2 pagesACW Manual v3Reef VolutionsNo ratings yet
- Module 3 CDSS PDFDocument44 pagesModule 3 CDSS PDFGanga Nayan T LNo ratings yet
- Style SheetsDocument8 pagesStyle SheetsVinod DeenathayalanNo ratings yet
- Iptvgreat Vs Falcon TVDocument6 pagesIptvgreat Vs Falcon TVAparajita LamiaNo ratings yet
- Computer Yan TramDocument2 pagesComputer Yan TramAakash murarkaNo ratings yet
- Pulse Catch InputDocument10 pagesPulse Catch Inputduccuong2004No ratings yet
- Grid ArchitectureDocument19 pagesGrid ArchitectureBittu VermaNo ratings yet
- CourseOfferingPlanGradF18 S20 20180106Document9 pagesCourseOfferingPlanGradF18 S20 20180106Anshum PalNo ratings yet
- LogfileDocument7 pagesLogfileJacob TibonNo ratings yet
- American International University-Bangladesh (AIUB) Faculty of Engineering (EEE)Document4 pagesAmerican International University-Bangladesh (AIUB) Faculty of Engineering (EEE)SifatNo ratings yet
- Buy RYZEN 7 3700X 4.4GHz GT 1030 2GB Desktop PC at Evetech - Co.zaDocument1 pageBuy RYZEN 7 3700X 4.4GHz GT 1030 2GB Desktop PC at Evetech - Co.zamgstruwigNo ratings yet
- Communiques - DP - DP 302 Submission of Annual System Audit ReportDocument13 pagesCommuniques - DP - DP 302 Submission of Annual System Audit ReportscnehraNo ratings yet
- ParaView Users Guide DocumentationDocument530 pagesParaView Users Guide DocumentationDonatoNo ratings yet
- Chapter 5 - User-Defined Methods - Solutions For Class 10 ICSE Logix Kips Computer Applications With BlueJ Java - KnowledgeBoatDocument17 pagesChapter 5 - User-Defined Methods - Solutions For Class 10 ICSE Logix Kips Computer Applications With BlueJ Java - KnowledgeBoatJeronimoNo ratings yet
- Final Exam 23okt2020Document16 pagesFinal Exam 23okt2020zay_cobainNo ratings yet
- Atmel Example ListDocument1 pageAtmel Example ListimenenouvelleNo ratings yet
- Chapter 6 C - DLD (Dr. Nauman)Document12 pagesChapter 6 C - DLD (Dr. Nauman)Bangle ChNo ratings yet
- Object Oriented ProgrammingDocument2 pagesObject Oriented ProgrammingBiantoroKunartoNo ratings yet
- Automatic Billing System Using ZigbeeDocument6 pagesAutomatic Billing System Using ZigbeeBrightworld ProjectsNo ratings yet
- Implementas API Bot Telegram Untuk Sistem Notifikasi Pada The Dude Network Monitoring SystemDocument7 pagesImplementas API Bot Telegram Untuk Sistem Notifikasi Pada The Dude Network Monitoring SystemDellya Sari AndiniNo ratings yet
- Analog ElectronicsDocument180 pagesAnalog ElectronicsTharun kumar DoggaNo ratings yet
- NIOS 8.4.8 ReleaseNotesDocument55 pagesNIOS 8.4.8 ReleaseNotesLuis InostrozaNo ratings yet
- PI OLEDB Error' - Pisquare - Osisoft.com - S - Question - 0D51I00004UHeezSAD - Pi-Oledb-ErrorDocument1 pagePI OLEDB Error' - Pisquare - Osisoft.com - S - Question - 0D51I00004UHeezSAD - Pi-Oledb-ErrorDimo DimoNo ratings yet