You might also like
- Mathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsFrom EverandMathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsNo ratings yet
- MScFE 610 ECON - Compiled - Notes - M6Document29 pagesMScFE 610 ECON - Compiled - Notes - M6sadiqpmpNo ratings yet
- Regression Modelling With Actuarial and Financial Applications - Key NotesDocument3 pagesRegression Modelling With Actuarial and Financial Applications - Key NotesMitchell NathanielNo ratings yet
- Application of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsFrom EverandApplication of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsRating: 5 out of 5 stars5/5 (1)
- Michael C. Whitlock, Dolph Schluter - The Analysis of Biological Data-MacMillan, W. H. Freeman (2020) - CompressedDocument2,306 pagesMichael C. Whitlock, Dolph Schluter - The Analysis of Biological Data-MacMillan, W. H. Freeman (2020) - CompressedDEVPRABHU100% (1)
- Numerical and Statistical Methods: For Civil EngineeringDocument716 pagesNumerical and Statistical Methods: For Civil EngineeringPaulo Aleixo33% (3)
- Dohoo Veterinary Epidemiologic Research OcrDocument727 pagesDohoo Veterinary Epidemiologic Research OcrRaquel Correa Luna86% (7)
- MidTerm MGT782 JULY 2023Document6 pagesMidTerm MGT782 JULY 2023Alea AzmiNo ratings yet
- Comparison of Methods: Passing and Bablok Regression - Biochemia MedicaDocument5 pagesComparison of Methods: Passing and Bablok Regression - Biochemia MedicaLink BuiNo ratings yet
- Lecture 3-MSDA 3055Document44 pagesLecture 3-MSDA 3055dhaval galaNo ratings yet
- 焦润一已发表论文1Document5 pages焦润一已发表论文1Runyi JiaoNo ratings yet
- Exam With SolutionsDocument7 pagesExam With SolutionsCarlos Andres Pinzon LoaizaNo ratings yet
- STD DevDocument5 pagesSTD DevAhmar AliNo ratings yet
- Reactions 2Document7 pagesReactions 2Josephine ChenNo ratings yet
- Univariate and Bivariate Data Analysis + ProbabilityDocument5 pagesUnivariate and Bivariate Data Analysis + ProbabilityBasoko_Leaks100% (1)
- 2.1 Plotting For Exploratory Data Analysis (EDA)Document2 pages2.1 Plotting For Exploratory Data Analysis (EDA)RajaNo ratings yet
- EovermreportDocument7 pagesEovermreportapi-702743009No ratings yet
- Excercise 1 - 2022 - SolutionDocument6 pagesExcercise 1 - 2022 - SolutionDũng VũNo ratings yet
- Lecture-1-2 Frequency Distribution & Central TendencyDocument7 pagesLecture-1-2 Frequency Distribution & Central TendencyNafiul Alam SnigdhoNo ratings yet
- Appendix Robust RegressionDocument17 pagesAppendix Robust RegressionPRASHANTH BHASKARANNo ratings yet
- Lecture # 3 (Heteroskedasticity in Cross-Sectional Data)Document5 pagesLecture # 3 (Heteroskedasticity in Cross-Sectional Data)Batool SahabnNo ratings yet
- HSVZJX DDocument10 pagesHSVZJX DCes SyNo ratings yet
- Numerical Error AnalysisDocument16 pagesNumerical Error AnalysisArkayan LahaNo ratings yet
- Lin's Concordance Correlation CoefficientDocument7 pagesLin's Concordance Correlation CoefficientscjofyWFawlroa2r06YFVabfbajNo ratings yet
- Mean Absolute Deviation About Median As A Tool ofDocument7 pagesMean Absolute Deviation About Median As A Tool ofMuhammad SatriyoNo ratings yet
- Traineeship Report: CraagDocument9 pagesTraineeship Report: CraagOmar SiddikNo ratings yet
- LP 1 in Math 2Document23 pagesLP 1 in Math 2Walwal WalwalNo ratings yet
- Modeling Uncertainty P2Document11 pagesModeling Uncertainty P2Sam OkpehNo ratings yet
- Improper IntegralsDocument16 pagesImproper Integralsjodyanne ubaldeNo ratings yet
- Chapter 1 Simple Linear Regression ModelDocument2 pagesChapter 1 Simple Linear Regression ModelNermine LimemeNo ratings yet
- Topic 7-GEE5 Elementary StatisticsDocument5 pagesTopic 7-GEE5 Elementary StatisticsLyndeemuringNo ratings yet
- Standard Normal Distribution Critical Values, ZDocument3 pagesStandard Normal Distribution Critical Values, Zlbeard501No ratings yet
- TP05 Econometrics p1Document22 pagesTP05 Econometrics p1tommy.santos2No ratings yet
- Lecture 3 - Econometria IDocument46 pagesLecture 3 - Econometria ITassio Schiavetti RossiNo ratings yet
- CE 2231 NOTES Venturi Nozzle Pitot TubeDocument3 pagesCE 2231 NOTES Venturi Nozzle Pitot TubeDaryl Adrian ChilaganNo ratings yet
- Cramer-Rao Lower Bound: 4.1 Estimator AccuracyDocument7 pagesCramer-Rao Lower Bound: 4.1 Estimator AccuracyÖmer Faruk DemirNo ratings yet
- HW 9Document6 pagesHW 9Acads Storage 02No ratings yet
- Chapter 3 - The DerivativeDocument8 pagesChapter 3 - The DerivativeERJEAN SILVERIONo ratings yet
- Rohini 27786294869Document10 pagesRohini 27786294869Drishti Study CenterNo ratings yet
- Lecture 5Document5 pagesLecture 5alcinialbob1234No ratings yet
- DSP Sp23 Wk2 230220Document18 pagesDSP Sp23 Wk2 230220Qaiser AbbasNo ratings yet
- 統計摘要Document12 pages統計摘要harrison61704No ratings yet
- Instrumental Variables Two Stage Least Squares 2sls 2013 The BasicsDocument2 pagesInstrumental Variables Two Stage Least Squares 2sls 2013 The BasicsDjime DiawaraNo ratings yet
- Lecture 10Document13 pagesLecture 10YashikaNo ratings yet
- Test-Statistics List: Test Statistics For Finding The Confidence Intervals and Hypothesis TestingDocument1 pageTest-Statistics List: Test Statistics For Finding The Confidence Intervals and Hypothesis TestingRojan PradhanNo ratings yet
- Unit 4Document8 pagesUnit 4Kamlesh PariharNo ratings yet
- MTH 102 Calculus - II-Topic 2-The Fundamental Theorem of CalculusDocument23 pagesMTH 102 Calculus - II-Topic 2-The Fundamental Theorem of CalculusDestroy GameNo ratings yet
- Keplers LawsDocument7 pagesKeplers LawsShumailaNo ratings yet
- Derivation of The Mean Square DisplacementDocument4 pagesDerivation of The Mean Square DisplacementSimone MolinaroNo ratings yet
- L5 1D+Truss+Element +formulationsDocument11 pagesL5 1D+Truss+Element +formulationsMustafa Oğuz DALNo ratings yet
- S9-P5 Mrabti PaperDocument10 pagesS9-P5 Mrabti PaperGhita ZazNo ratings yet
- BEST Linear EstimatorsDocument8 pagesBEST Linear EstimatorsDénes EnikőNo ratings yet
- AE 5332 - Professor Dora E. Musielak: Residue Theorem and Solution of Real Indefinite IntegralsDocument12 pagesAE 5332 - Professor Dora E. Musielak: Residue Theorem and Solution of Real Indefinite IntegralsJohnNo ratings yet
- Lecture 23Document22 pagesLecture 23Dinuja SenevirathneNo ratings yet
- SDET Formulae MidSem2 2018 Ver3Document2 pagesSDET Formulae MidSem2 2018 Ver3Ritvick GuptaNo ratings yet
- New Solutions To Variable Coefficients Differential Equations IDocument14 pagesNew Solutions To Variable Coefficients Differential Equations IInnocentNo ratings yet
- EC2105 Lecture 7 E-Field4Document24 pagesEC2105 Lecture 7 E-Field4hyunyoung256No ratings yet
- Simple Linear RegressionDocument2 pagesSimple Linear RegressionVaibhav RaulkarNo ratings yet
- Hafiz Arslan Khalid: Roll No. Department: Subject: Assignment # 3: Submitted To: Date SubmissionDocument8 pagesHafiz Arslan Khalid: Roll No. Department: Subject: Assignment # 3: Submitted To: Date SubmissionArslan RajaNo ratings yet
- A Simple Engineering Technique To Estimate The FirDocument8 pagesA Simple Engineering Technique To Estimate The FirMarkNo ratings yet
- Lecture-5-6 Moment, Skewness and KurtosisDocument5 pagesLecture-5-6 Moment, Skewness and KurtosisNafiul Alam SnigdhoNo ratings yet
- BasicCalQ3W1 SLMDocument16 pagesBasicCalQ3W1 SLMNasos 2No ratings yet
- CH 8Document22 pagesCH 8aju michaelNo ratings yet
- Quetions For Top Students PDFDocument2 pagesQuetions For Top Students PDFharuhi.karasunoNo ratings yet
- DPBS 1203 Business and Economic StatisticsDocument21 pagesDPBS 1203 Business and Economic StatisticsJazlyn JasaNo ratings yet
- Lesson 06Document8 pagesLesson 06kavishka ubeysekaraNo ratings yet
- Lesson 04Document5 pagesLesson 04kavishka ubeysekaraNo ratings yet
- Lesson 05Document8 pagesLesson 05kavishka ubeysekaraNo ratings yet
- Lecture 9 - Exchange RateDocument27 pagesLecture 9 - Exchange Ratekavishka ubeysekaraNo ratings yet
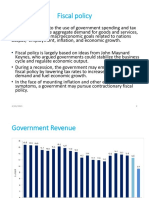
- Supplementary Lecture 5 - Fiscal PolicyDocument22 pagesSupplementary Lecture 5 - Fiscal Policykavishka ubeysekaraNo ratings yet
- Lecture 7 - Monetary PolicyDocument11 pagesLecture 7 - Monetary Policykavishka ubeysekaraNo ratings yet
- Lecture 8 - Balance of PaymentsDocument23 pagesLecture 8 - Balance of Paymentskavishka ubeysekaraNo ratings yet
- Lecture 1 - GDP, Eco Growth + The Business CycleDocument40 pagesLecture 1 - GDP, Eco Growth + The Business Cyclekavishka ubeysekaraNo ratings yet
- Mayfield High School Coursework SampleDocument6 pagesMayfield High School Coursework Samplejlnggfajd100% (2)
- Multilinear ProblemStatementDocument132 pagesMultilinear ProblemStatementSBS MoviesNo ratings yet
- Chapter 15 CRAVEN SALES MODEL - Multiple RegressionDocument19 pagesChapter 15 CRAVEN SALES MODEL - Multiple RegressionFahad MushtaqNo ratings yet
- 04 - Notebook4 - Additional InformationDocument5 pages04 - Notebook4 - Additional InformationLokesh LokiNo ratings yet
- Factors Affecting Customer Satisfaction in Banking Sector of PakistanDocument12 pagesFactors Affecting Customer Satisfaction in Banking Sector of Pakistananon_66157408No ratings yet
- Introduction To Correlationand Regression Analysis BY Farzad Javidanrad PDFDocument52 pagesIntroduction To Correlationand Regression Analysis BY Farzad Javidanrad PDFgulafshanNo ratings yet
- 1 s2.0 S2210670720301025 MainDocument11 pages1 s2.0 S2210670720301025 MainGodwynNo ratings yet
- Simple Linear Regression - Assign3Document8 pagesSimple Linear Regression - Assign3Sravani AdapaNo ratings yet
- Group 1 MR ProjectDocument40 pagesGroup 1 MR ProjectradhikaNo ratings yet
- Value Chain Analysis of Banana in Bench Maji and Sheka Zones of Southern EthiopiaDocument20 pagesValue Chain Analysis of Banana in Bench Maji and Sheka Zones of Southern Ethiopianigus gurmis1No ratings yet
- Comparative Analysis of Supervised Machine LearninDocument10 pagesComparative Analysis of Supervised Machine LearninHainsley EdwardsNo ratings yet
- Quick Review of ML Algorithms 139Document5 pagesQuick Review of ML Algorithms 139cheintNo ratings yet
- Stevenson7ce PPT Ch03Document86 pagesStevenson7ce PPT Ch03Anisha SidhuNo ratings yet
- Corporate Governance Reform Within The Uk Banking Industry and Its Effect On Firm PerformanceDocument15 pagesCorporate Governance Reform Within The Uk Banking Industry and Its Effect On Firm PerformanceImi MaximNo ratings yet
- QUM2 Task 1 Linear Regression AnalysisDocument5 pagesQUM2 Task 1 Linear Regression Analysisvieucheyenne1986No ratings yet
- Salinan Dari Untitled0.Ipynb - ColaboratoryDocument3 pagesSalinan Dari Untitled0.Ipynb - ColaboratoryDandi Rifa'i TariganNo ratings yet
- American International University-Bangladesh (Aiub) : Faculty of Science & Technology Department of Physics Physics Lab 1Document9 pagesAmerican International University-Bangladesh (Aiub) : Faculty of Science & Technology Department of Physics Physics Lab 1rianrian100% (4)
- Reading 07-Correlation and RegressionDocument18 pagesReading 07-Correlation and Regression杨坡No ratings yet
- Mean-Variance Portfolio Selection With Estimation Risk and Transaction CostsDocument19 pagesMean-Variance Portfolio Selection With Estimation Risk and Transaction CostsdominiquendatienNo ratings yet
- Evaluation of Stabilised-Earth Block (STEB) As Alternative To Sancrete Blocks For Housing Provision and Construction in South East NigeriaDocument8 pagesEvaluation of Stabilised-Earth Block (STEB) As Alternative To Sancrete Blocks For Housing Provision and Construction in South East NigeriaNnadi EzekielNo ratings yet
- Bahan TOD Korea-DikonversiDocument15 pagesBahan TOD Korea-DikonversiBillbe XBNo ratings yet
- Vaccine Hesitancy and Cognitive BiasesDocument7 pagesVaccine Hesitancy and Cognitive Biasesemy mamdohNo ratings yet
- FALL 2012-13: by Assoc. Prof. Sami FethiDocument84 pagesFALL 2012-13: by Assoc. Prof. Sami FethiTabish BhatNo ratings yet
- A Conceptual Model of Consumer Behavior PDFDocument11 pagesA Conceptual Model of Consumer Behavior PDFDylan Ludo DCNo ratings yet