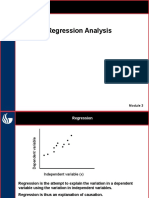
You might also like
- AP Statistics - 2014-2015 Semester 1 Test 3Document4 pagesAP Statistics - 2014-2015 Semester 1 Test 3Camden BickelNo ratings yet
- The Biostatistics of Aging: From Gompertzian Mortality to an Index of Aging-RelatednessFrom EverandThe Biostatistics of Aging: From Gompertzian Mortality to an Index of Aging-RelatednessNo ratings yet
- MCQ StatisticsDocument8 pagesMCQ StatisticsNima PemaNo ratings yet
- Bio 321 F13 HW 2 Key v2Document6 pagesBio 321 F13 HW 2 Key v2Stringer BellNo ratings yet
- Data8 sp16 Final SolutionDocument9 pagesData8 sp16 Final SolutionMinh ChâuNo ratings yet
- MATH105 Worksheet 4 1Document10 pagesMATH105 Worksheet 4 1Gia Huong HoangNo ratings yet
- Stab22h3 m17Document26 pagesStab22h3 m17fiona.li388No ratings yet
- Measures of Position and Spread in DataDocument2 pagesMeasures of Position and Spread in DataCadie ClarkNo ratings yet
- C8511 Research Skills One Sample Paper With AnswersDocument21 pagesC8511 Research Skills One Sample Paper With AnswersArun Mohanaraj100% (1)
- AP Statistics Ch 1 Test ReviewDocument5 pagesAP Statistics Ch 1 Test ReviewRubbie NguyenNo ratings yet
- Hemh105 PDFDocument20 pagesHemh105 PDFhoneygarg1986No ratings yet
- BA578Assignment-1 due by Midnight (11:59pm) Sunday, September 11th , 2011Document13 pagesBA578Assignment-1 due by Midnight (11:59pm) Sunday, September 11th , 2011kshamblNo ratings yet
- Sample Problems On Data Analysis: What Is Your Favorite Class?Document8 pagesSample Problems On Data Analysis: What Is Your Favorite Class?ainaNo ratings yet
- MATH015 Autumn2015 Tutorials Ex 0.1 QuestionsDocument3 pagesMATH015 Autumn2015 Tutorials Ex 0.1 QuestionsMohamadFadiNo ratings yet
- Browne (2004)Document13 pagesBrowne (2004)seolalalalNo ratings yet
- Statistics AssignmentDocument6 pagesStatistics Assignmentianiroy13No ratings yet
- Multivariate Analysis FINAL EXAM RETAKE FALL 2019Document8 pagesMultivariate Analysis FINAL EXAM RETAKE FALL 2019Si Hui ZhuoNo ratings yet
- ExercisesDocument37 pagesExercisesdarwin_hua100% (1)
- U of T Scarborough STAB22 Midterm Exam Questions (40chDocument13 pagesU of T Scarborough STAB22 Midterm Exam Questions (40chAbdullahiNo ratings yet
- Lecture On Non-Parametric StatisticsDocument16 pagesLecture On Non-Parametric StatisticsRyan BondocNo ratings yet
- PalAss2011 PosterDocument1 pagePalAss2011 PosterrossmounceNo ratings yet
- Exercise 1:: Chapter 3: Describing Data: Numerical MeasuresDocument11 pagesExercise 1:: Chapter 3: Describing Data: Numerical MeasuresPW Nicholas100% (1)
- Appendix 7A: Details About Sources Used For Entries in Table 7.1Document30 pagesAppendix 7A: Details About Sources Used For Entries in Table 7.1Henrique FreitasNo ratings yet
- HSH 2023 G10 BC Summative by Zi Chuan LINDocument19 pagesHSH 2023 G10 BC Summative by Zi Chuan LINnotmuappleNo ratings yet
- 1-Way ANOVA Tests: The SettingDocument7 pages1-Way ANOVA Tests: The SettingKhushbuNo ratings yet
- As Stats Chapter 3 Representations of Data Worksheet QP 3Document7 pagesAs Stats Chapter 3 Representations of Data Worksheet QP 3BONGLAV JemasonNo ratings yet
- Midterm2015 Solutions 032415Document16 pagesMidterm2015 Solutions 032415Phương NguyễnNo ratings yet
- ANOVA ExplainedDocument9 pagesANOVA ExplainedDexter LedesmaNo ratings yet
- Sequence Weights: Stephen F. AltschulDocument17 pagesSequence Weights: Stephen F. AltschulaminNo ratings yet
- Name - Hour - Date - Scatter Plots and Lines of Best Fit WorksheetDocument2 pagesName - Hour - Date - Scatter Plots and Lines of Best Fit WorksheetDalton MiracleNo ratings yet
- Business Statistics (Exercise 1)Document3 pagesBusiness Statistics (Exercise 1)مہر علی حیدر33% (3)
- This Study Resource Was: Lane #8 CH 7Document4 pagesThis Study Resource Was: Lane #8 CH 7Zoloft Zithromax ProzacNo ratings yet
- Exercise CH 11Document10 pagesExercise CH 11Nurshuhada NordinNo ratings yet
- Statistics SonDocument39 pagesStatistics SonHuseyn AdigozalovNo ratings yet
- Prep For Fe Sol Qr15Document5 pagesPrep For Fe Sol Qr15chumnhomauxanhNo ratings yet
- Model Paper - Business StatisticsDocument7 pagesModel Paper - Business StatisticsIshini SaparamaduNo ratings yet
- Modelling Complex VariationDocument9 pagesModelling Complex VariationDimNo ratings yet
- AP Stats Practice ch1Document6 pagesAP Stats Practice ch1Chae ChaeNo ratings yet
- Exam1 s16 SolDocument10 pagesExam1 s16 SolVũ Quốc NgọcNo ratings yet
- Multiple Regression Tutorial 3Document5 pagesMultiple Regression Tutorial 32plus5is7100% (2)
- Statistics For The Behavioral Sciences 4th Edition Nolan Heinzen Test BankDocument41 pagesStatistics For The Behavioral Sciences 4th Edition Nolan Heinzen Test Bankpenelope100% (23)
- STAB22 Final Examination Multiple Choice QuestionsDocument23 pagesSTAB22 Final Examination Multiple Choice QuestionsczvzNo ratings yet
- Unit 1 Review PacketDocument10 pagesUnit 1 Review PacketLiezlLzeilCarreonGalgoNo ratings yet
- ANOVA Explained: Analysis of VarianceDocument25 pagesANOVA Explained: Analysis of VariancevanausabNo ratings yet
- Worksheet On Frequency DistributionDocument11 pagesWorksheet On Frequency DistributionChris Mine0% (1)
- Illustration of Using Excel To Find Maximum Likelihood EstimatesDocument14 pagesIllustration of Using Excel To Find Maximum Likelihood EstimatesRustam MuhammadNo ratings yet
- Past Paper 2015Document7 pagesPast Paper 2015Choco CheapNo ratings yet
- PS03 Descriptive StatisticsDocument8 pagesPS03 Descriptive StatisticssrwNo ratings yet
- Describing Data Numerically - Activity-SKDocument6 pagesDescribing Data Numerically - Activity-SKShamari DavisNo ratings yet
- Midterm 1a SolutionsDocument9 pagesMidterm 1a Solutionskyle.krist13No ratings yet
- Mean, Median and ModeDocument11 pagesMean, Median and ModeSeerat Pannu0% (1)
- Tugas8 Probabilitas - AdelyaNatasya - 09011281924055Document8 pagesTugas8 Probabilitas - AdelyaNatasya - 09011281924055PitriaNo ratings yet
- A Visualization of Fisher's Least Significant Difference TestDocument7 pagesA Visualization of Fisher's Least Significant Difference TestAli MasykurNo ratings yet
- Tugas Statistik Ke-3Document6 pagesTugas Statistik Ke-3Pandu AnggoroNo ratings yet
- Statistics 252 - Midterm Exam: Instructor: Paul CartledgeDocument7 pagesStatistics 252 - Midterm Exam: Instructor: Paul CartledgeRauNo ratings yet
- Chisquare Indep Sol1Document13 pagesChisquare Indep Sol1Munawar100% (1)
- 2 - 6 - Practice Test REGDocument5 pages2 - 6 - Practice Test REGnuoti guanNo ratings yet
- Chapter 14 - Analysis of Variance (ANOVA) : TI-83/84 ProcedureDocument6 pagesChapter 14 - Analysis of Variance (ANOVA) : TI-83/84 Proceduren2985No ratings yet
- Quiz 3 Review QuestionsDocument5 pagesQuiz 3 Review QuestionsSteven Nguyen0% (1)
- Tutorial 05 SolnDocument4 pagesTutorial 05 SolnJingyi LiNo ratings yet
- Probability and Statistics Tutorial SolutionDocument3 pagesProbability and Statistics Tutorial SolutionJingyi LiNo ratings yet
- Tutorial 03 SolnDocument2 pagesTutorial 03 SolnJingyi LiNo ratings yet
- Tutorial 03 OnsiteDocument1 pageTutorial 03 OnsiteJingyi LiNo ratings yet
- ST1131 Tutorial Normal Sampling DistributionsDocument4 pagesST1131 Tutorial Normal Sampling DistributionsJingyi LiNo ratings yet
- Tutorial 01 SolnDocument4 pagesTutorial 01 SolnJingyi LiNo ratings yet
- ST1131 Final Exam Marks AnalysisDocument1 pageST1131 Final Exam Marks AnalysisJingyi LiNo ratings yet
- Presentation Generalized Linear Model TheoryDocument77 pagesPresentation Generalized Linear Model Theorymse0425No ratings yet
- MulticollinearityDocument25 pagesMulticollinearityDUSHYANT MUDGAL100% (1)
- Unit-5 AnovaDocument12 pagesUnit-5 AnovaMANTHAN JADHAVNo ratings yet
- Effective Training Boosts E-Commerce Competitive EdgeDocument14 pagesEffective Training Boosts E-Commerce Competitive Edgemuna moono100% (1)
- Predict Binary Outcomes with Logistic RegressionDocument11 pagesPredict Binary Outcomes with Logistic RegressionOsama RiazNo ratings yet
- Materi - Confounders in Internal Validity - GM IPBDocument21 pagesMateri - Confounders in Internal Validity - GM IPBsalehahnhNo ratings yet
- Analisis daya serap uap airDocument4 pagesAnalisis daya serap uap airKRISTINANo ratings yet
- Stochastic Analysis, Modeling, and Simulation (SAMS) User ManualDocument123 pagesStochastic Analysis, Modeling, and Simulation (SAMS) User ManualKarla ZárateNo ratings yet
- Regression AnalysisDocument15 pagesRegression AnalysispoonamNo ratings yet
- Poisson Distribution ExamplesDocument2 pagesPoisson Distribution ExamplesSandhya SinghNo ratings yet
- Data Mining Techniques in 38 CharactersDocument6 pagesData Mining Techniques in 38 CharactersNed ThaiNo ratings yet
- Statistical Soup - ANOVA, ANCOVA, MANOVA, & MANCOVADocument1 pageStatistical Soup - ANOVA, ANCOVA, MANOVA, & MANCOVAsapaNo ratings yet
- Pengaruh Kepemilikan Institusional, Intellectual Capital, Dan (Studi Kasus Pada Perusahaan Manufaktur Yang Terdaftar Di Bursa Efek Indonesia Tahun 2014-2017)Document14 pagesPengaruh Kepemilikan Institusional, Intellectual Capital, Dan (Studi Kasus Pada Perusahaan Manufaktur Yang Terdaftar Di Bursa Efek Indonesia Tahun 2014-2017)Aula NasyrahNo ratings yet
- Introduction to Statistical InferenceDocument22 pagesIntroduction to Statistical InferenceMLNo ratings yet
- Philippine Christian University Taft Avenue, Manila: Course Outline and ObjectivesDocument3 pagesPhilippine Christian University Taft Avenue, Manila: Course Outline and ObjectivesKatrizia FauniNo ratings yet
- Lecture 18 LSD and HSDDocument19 pagesLecture 18 LSD and HSDPremKumarTamilarasanNo ratings yet
- DMPM-LAB-03-Assignment: RcodeDocument9 pagesDMPM-LAB-03-Assignment: RcodeA-10- Amar-SaxenaNo ratings yet
- CS-E4820 Machine Learning: Advanced Probabilistic MethodsDocument2 pagesCS-E4820 Machine Learning: Advanced Probabilistic MethodsGigiNo ratings yet
- PAIRED T TEST Note and Example1Document25 pagesPAIRED T TEST Note and Example1Zul ZhafranNo ratings yet
- STA1510 Chapter 8 SummaryDocument3 pagesSTA1510 Chapter 8 SummaryLeigh MakanNo ratings yet
- Measures of Central Tendency and DispersionDocument216 pagesMeasures of Central Tendency and DispersionJai John100% (1)
- Business Statistics - Retail CASE (Solutions)Document5 pagesBusiness Statistics - Retail CASE (Solutions)Anonymous 7apeurNo ratings yet
- SAT Subject StatisticsDocument12 pagesSAT Subject StatisticsyuhanNo ratings yet
- Econ140 Spring2016 Section07 Handout SolutionsDocument6 pagesEcon140 Spring2016 Section07 Handout SolutionsFatemeh IglinskyNo ratings yet
- 285 NotesDocument45 pages285 NotesNele Graves100% (1)
- CAM625 2019 s1 Module1Document31 pagesCAM625 2019 s1 Module1Kelvin LeongNo ratings yet
- Tutorial 9 FishersDocument2 pagesTutorial 9 FishersБ.ХалиунNo ratings yet
- Review - 1 Machine Learning: - D.Malakondaiah Chowdary (160050051)Document12 pagesReview - 1 Machine Learning: - D.Malakondaiah Chowdary (160050051)Madhu VardhineediNo ratings yet
- Stat QuizDocument105 pagesStat QuizAllen Jerry AriesNo ratings yet
- CORRELATION BETWEEN HEIGHT AND WEIGHTDocument4 pagesCORRELATION BETWEEN HEIGHT AND WEIGHTBread BasketNo ratings yet
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- Strategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceFrom EverandStrategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceNo ratings yet
- Assessment Prep for Common Core Mathematics, Grade 6From EverandAssessment Prep for Common Core Mathematics, Grade 6Rating: 5 out of 5 stars5/5 (1)