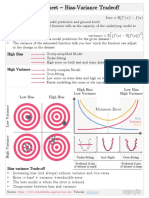
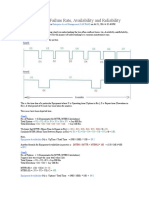
You might also like
- Ifa PDFDocument10 pagesIfa PDFmusa100% (1)
- 50 Advanced Machine Learning Questions - ChatGPTDocument18 pages50 Advanced Machine Learning Questions - ChatGPTLily Lauren100% (1)
- 51 Machine Learning Interview Questions With Answers - SpringboardDocument20 pages51 Machine Learning Interview Questions With Answers - SpringboardShrivathsatv Shri100% (1)
- Interview Questions On Machine LearningDocument22 pagesInterview Questions On Machine LearningPraveen100% (4)
- 2024 HRPIWSProgramDocument120 pages2024 HRPIWSProgramJhan Saavedra100% (1)
- Python ML BookDocument211 pagesPython ML BookLeo PackNo ratings yet
- Awesome Big Data AlgorithmsDocument37 pagesAwesome Big Data AlgorithmsYamabushiNo ratings yet
- #187 - Structured Water - With DRDocument7 pages#187 - Structured Water - With DRRudolph Flowers IINo ratings yet
- Machine Learning Interview Questions.Document43 pagesMachine Learning Interview Questions.hari krishna reddy100% (1)
- Week 15 - ClusteringDocument25 pagesWeek 15 - ClusteringRoyer Rojano100% (2)
- 40 Interview Questions Asked at Startups in Machine Learning - Data ScienceDocument33 pages40 Interview Questions Asked at Startups in Machine Learning - Data Sciencesanjana100% (1)
- 15 Retaining Walls, Basement WallsDocument8 pages15 Retaining Walls, Basement Wallsjunhe898100% (1)
- Machine Learning with Clustering: A Visual Guide for Beginners with Examples in PythonFrom EverandMachine Learning with Clustering: A Visual Guide for Beginners with Examples in PythonNo ratings yet
- Machine Learning Cheat Sheet PDFDocument15 pagesMachine Learning Cheat Sheet PDFgalagrandNo ratings yet
- Super Cheatsheet Machine LearningDocument15 pagesSuper Cheatsheet Machine LearningAkhil Kandregula100% (1)
- CheatSheet Python 10 Machine Learning SVMDocument1 pageCheatSheet Python 10 Machine Learning SVMSATYAJEET SARFARE (Alumni)No ratings yet
- Cheatsheets For Deep Learning 1650192034Document95 pagesCheatsheets For Deep Learning 1650192034desdentado30No ratings yet
- Stock Market Prediction Using LSTM TechniqueDocument11 pagesStock Market Prediction Using LSTM TechniqueIJRASETPublications100% (1)
- Machine Learning InterviewsDocument22 pagesMachine Learning InterviewsMark Fisher100% (2)
- 40 Interview Questions Asked at Startups in Machine Learning - Data ScienceDocument33 pages40 Interview Questions Asked at Startups in Machine Learning - Data SciencePallav Anand100% (3)
- Machine LearningDocument211 pagesMachine LearningHarish100% (1)
- Machine Learning InterviewDocument14 pagesMachine Learning Interviewsobuz visualNo ratings yet
- 4navigating The Other WorldsDocument32 pages4navigating The Other WorldsManuel HerreraNo ratings yet
- Deep Learning PDFDocument87 pagesDeep Learning PDFArnaldo Preso De LigaNo ratings yet
- Mathematics For Machine LearningDocument100 pagesMathematics For Machine LearningUmaphani MorthaNo ratings yet
- Machine Learning: The Hundred-Page BookDocument4 pagesMachine Learning: The Hundred-Page BookpollupoccuNo ratings yet
- Top 40 Data Structure Interview Questions and Answers (2021) - InterviewBitDocument31 pagesTop 40 Data Structure Interview Questions and Answers (2021) - InterviewBitShubham BajajNo ratings yet
- Deep Learning Interview Questions - Deep Learning QuestionsDocument21 pagesDeep Learning Interview Questions - Deep Learning QuestionsheheeNo ratings yet
- 2021-02-16 - BHNF - Regional Office Meet Request Re BHNF Sustained YieldDocument11 pages2021-02-16 - BHNF - Regional Office Meet Request Re BHNF Sustained YieldNancy HildingNo ratings yet
- Statquest Gentle Introduction To Rna SeqDocument188 pagesStatquest Gentle Introduction To Rna SeqHoangHai100% (1)
- Top 30 Data Analytics Interview Questions & AnswersDocument16 pagesTop 30 Data Analytics Interview Questions & Answerskumar kumarNo ratings yet
- Feature EngineeringDocument76 pagesFeature Engineeringsentilbalan@gmail.com100% (1)
- Bagging and Random Forest Presentation1Document23 pagesBagging and Random Forest Presentation1endale100% (2)
- Notes On BackpropagationDocument14 pagesNotes On BackpropagationJun WangNo ratings yet
- Machine Learning Engineer Interview QuestionsDocument2 pagesMachine Learning Engineer Interview QuestionsRajaNo ratings yet
- Alpha Beta PruningDocument35 pagesAlpha Beta PruningChandra Bhushan SahNo ratings yet
- Machine LearningDocument62 pagesMachine LearningDoan Hieu100% (1)
- The Concise Valve V IDocument174 pagesThe Concise Valve V Ikagasaw023No ratings yet
- Deep Learning NotesDocument110 pagesDeep Learning NotesNishanth JoisNo ratings yet
- Genetic AlgorithmsDocument94 pagesGenetic AlgorithmsAbhishek Nanda100% (1)
- Machine LearningDocument46 pagesMachine LearningPoorna Kalandhar100% (3)
- Machine Learning NotesDocument3 pagesMachine Learning Noteshoney13No ratings yet
- Different Types of Regression ModelsDocument18 pagesDifferent Types of Regression ModelsHemal PandyaNo ratings yet
- Machine Learning With BoostingDocument212 pagesMachine Learning With Boostingelena.echavarria100% (1)
- Machine LearningDocument185 pagesMachine LearningAnbu Saravanan100% (1)
- Word2Vec Tutorial - The Skip-Gram Model Chris McCormick PDFDocument39 pagesWord2Vec Tutorial - The Skip-Gram Model Chris McCormick PDFVandCasaNo ratings yet
- Interpretable Machine LearningDocument251 pagesInterpretable Machine Learningsagar100% (1)
- Data Science Interview QuestionsDocument55 pagesData Science Interview QuestionsArunachalam Narayanan100% (2)
- Machine Learning and Linear RegressionDocument55 pagesMachine Learning and Linear RegressionKapil Chandel100% (1)
- Deep LearningDocument5 pagesDeep LearningTom AmitNo ratings yet
- Principal Component Analysis (PCA) in Machine LearningDocument20 pagesPrincipal Component Analysis (PCA) in Machine LearningMs Sushma BNo ratings yet
- Introduction To K-Nearest Neighbors: Simplified (With Implementation in Python)Document125 pagesIntroduction To K-Nearest Neighbors: Simplified (With Implementation in Python)Abhiraj Das100% (1)
- Future Towers Amanora Park Town, Pune, IndiaDocument12 pagesFuture Towers Amanora Park Town, Pune, IndiaPriya Balaji80% (5)
- Natural Language Processing: All You Need To Know AboutDocument45 pagesNatural Language Processing: All You Need To Know AboutChaitanya SaiNo ratings yet
- Statistics in DetailsDocument283 pagesStatistics in Detailsyousef shaban100% (1)
- Data Science Interview Questions (#Day13)Document10 pagesData Science Interview Questions (#Day13)Sahil GouthamNo ratings yet
- Machine Learning Case Study Interview Deeplearning - Ai - Workera PDFDocument1 pageMachine Learning Case Study Interview Deeplearning - Ai - Workera PDFSau L.No ratings yet
- Machine Learning Is FunDocument142 pagesMachine Learning Is FunRajachandra VoodigaNo ratings yet
- Ensemble Learning MethodsDocument24 pagesEnsemble Learning Methodskhatri81100% (1)
- Matching AlgorithmDocument3 pagesMatching AlgorithmraghuannamalaiNo ratings yet
- MACHINE LEARNING ALGORITHM - Unit-1-1Document78 pagesMACHINE LEARNING ALGORITHM - Unit-1-1akash chandankar100% (1)
- Machine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionDocument22 pagesMachine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionKANTESH kantesh100% (1)
- XGBoost R TutorialDocument10 pagesXGBoost R TutorialNitish100% (1)
- Outline and Reading: Tries 4/1/2003 9:02 AMDocument3 pagesOutline and Reading: Tries 4/1/2003 9:02 AMVenkataLakshmi KrishnasamyNo ratings yet
- XGboost TutorialDocument13 pagesXGboost Tutorialgargwork1990No ratings yet
- KNN Classification 1Document7 pagesKNN Classification 1Iyed Ben RejebNo ratings yet
- FRM Part 1 Quants 2023 MLDocument8 pagesFRM Part 1 Quants 2023 MLIshika ParasrampuriaNo ratings yet
- Gauss Nodes Revolution: Numerical Integration Theory Radically Simplified And GeneralisedFrom EverandGauss Nodes Revolution: Numerical Integration Theory Radically Simplified And GeneralisedNo ratings yet
- Are Medical Errors Still The Third Leading Cause of Death - LewRockwellDocument8 pagesAre Medical Errors Still The Third Leading Cause of Death - LewRockwellRudolph Flowers IINo ratings yet
- 2022 Pearson Code of ConductDocument32 pages2022 Pearson Code of ConductRudolph Flowers IINo ratings yet
- How To Make Cinnamon ToothpicksDocument10 pagesHow To Make Cinnamon ToothpicksRudolph Flowers IINo ratings yet
- Dr. Igor Shepherd's Talk About The Horrors of A Covid' Vaccine - LewRockwellDocument2 pagesDr. Igor Shepherd's Talk About The Horrors of A Covid' Vaccine - LewRockwellRudolph Flowers IINo ratings yet
- Aqa 7131 7132 SP 2023Document42 pagesAqa 7131 7132 SP 2023tramy.nguyenNo ratings yet
- Exam Questions Modelling With Exponential Functions - MsDocument13 pagesExam Questions Modelling With Exponential Functions - MsfajrbilaNo ratings yet
- Qdoc - Tips Hoc Anh Van Cung Thay Developing Skills For The ToDocument40 pagesQdoc - Tips Hoc Anh Van Cung Thay Developing Skills For The ToKiên Đỗ TrungNo ratings yet
- Grade 7 Weekly Lesson PlanDocument4 pagesGrade 7 Weekly Lesson Planfabillardevinegrace94No ratings yet
- Lesson IV: Characteristics of Competency Based TrainingDocument10 pagesLesson IV: Characteristics of Competency Based Trainingنجشو گحوشNo ratings yet
- Mastering The Art of ApproachingDocument2 pagesMastering The Art of ApproachingElvin MitraNo ratings yet
- Script of Interview VideoDocument3 pagesScript of Interview VideoTsogtsaikhan BatdelgerNo ratings yet
- Akhtar Zaiti Binti Azizi (CGS02786926) - Assignment Hmef5023 - V2Document15 pagesAkhtar Zaiti Binti Azizi (CGS02786926) - Assignment Hmef5023 - V2Akhtar ZaitiNo ratings yet
- On The Foundations of Gravitation, Inertia and Gravitational WavesDocument9 pagesOn The Foundations of Gravitation, Inertia and Gravitational Wavesgiorgiofontana100% (5)
- BLM 1-3 Section 1.1 PracticDocument1 pageBLM 1-3 Section 1.1 PracticRenier Palma CruzNo ratings yet
- Wa0004.Document15 pagesWa0004.ishaan shehrawatNo ratings yet
- Posorja Multipurpose Terminal Terminal Works: High-Mast and CCTV Poles InstallationDocument5 pagesPosorja Multipurpose Terminal Terminal Works: High-Mast and CCTV Poles Installationhz135874No ratings yet
- Estropia, Rhealyn Sanao: Email Add CONTACT NO: 09291694464 Address: 856 Prudencia STDocument2 pagesEstropia, Rhealyn Sanao: Email Add CONTACT NO: 09291694464 Address: 856 Prudencia STAlfred CasicasNo ratings yet
- 32-4-3 Social ScienceDocument11 pages32-4-3 Social ScienceshreyasNo ratings yet
- Fundamentals of Limits and Fits: Notes Prepared by Dr. Suhas S. Joshi, Department of Mechanical Engineering, IndianDocument35 pagesFundamentals of Limits and Fits: Notes Prepared by Dr. Suhas S. Joshi, Department of Mechanical Engineering, Indianyair Enrique Romero OspinoNo ratings yet
- HSMC & Open Electives Ii List 2021-22: Rural Development: Administration and PlanningDocument1 pageHSMC & Open Electives Ii List 2021-22: Rural Development: Administration and PlanningAnmolNo ratings yet
- D 6726 - 01 - Rdy3mjyDocument7 pagesD 6726 - 01 - Rdy3mjyRam Kailash YadavNo ratings yet
- Core Psychiatry Training - CT1 2023Document7 pagesCore Psychiatry Training - CT1 2023Rodrigo AmaralNo ratings yet
- BT Ngày 1.4.2022Document7 pagesBT Ngày 1.4.2022NhiNo ratings yet
- Real 6e Lesson Plan Water DensityDocument3 pagesReal 6e Lesson Plan Water Densityapi-384860157No ratings yet
- Investigation of Epithermal and Fast Neutron Shielding Properties of Some High Entropy Alloys Containing Ti, HF, NB, and ZRDocument9 pagesInvestigation of Epithermal and Fast Neutron Shielding Properties of Some High Entropy Alloys Containing Ti, HF, NB, and ZRالحكيم المصريNo ratings yet
- MTTRDocument3 pagesMTTRbkmineroNo ratings yet
- Assessment of Energy Consumption in Existing BuildingsDocument21 pagesAssessment of Energy Consumption in Existing BuildingsMerwin Andrew UyNo ratings yet