You might also like
- Python Pandas-Series-newwDocument80 pagesPython Pandas-Series-newwp100% (1)
- Python Pandas SeriesDocument37 pagesPython Pandas SeriesRNo ratings yet
- SeriesDocument4 pagesSeriessukaina mumtazNo ratings yet
- exp8 sblcDocument9 pagesexp8 sblcRajNo ratings yet
- Data Handling Using Pandas-1Document25 pagesData Handling Using Pandas-1shakti singhNo ratings yet
- 2. Python Pandas(II)Document18 pages2. Python Pandas(II)tnandyalaNo ratings yet
- Pandas Series and DataFrameDocument5 pagesPandas Series and DataFrameRC SharmaNo ratings yet
- Python Pandas ch-2Document56 pagesPython Pandas ch-2Rohan sushilNo ratings yet
- Python Pandas New SylabusDocument53 pagesPython Pandas New SylabusRohan sushilNo ratings yet
- 1 IP 12 NOTES PythonPandas 2022 PDFDocument66 pages1 IP 12 NOTES PythonPandas 2022 PDFKrrish Kumar100% (3)
- Class12 Pandas NotesDocument23 pagesClass12 Pandas NotesMayank AhujaNo ratings yet
- Class XII Data Handlinng Using PandasIDocument46 pagesClass XII Data Handlinng Using PandasIPushkar ChaudharyNo ratings yet
- PYTHON PANDAS LIBRARY OVERVIEWDocument51 pagesPYTHON PANDAS LIBRARY OVERVIEWNenavath GaneshNo ratings yet
- Python PandasDocument22 pagesPython PandasAdithyan R NairNo ratings yet
- Python PandasDocument35 pagesPython PandasMayur Nasare100% (1)
- Python PandasDocument230 pagesPython PandasArun NarasimhanNo ratings yet
- Python For DScience & D Visualisation UpdatedDocument11 pagesPython For DScience & D Visualisation UpdatedbitchingaroundNo ratings yet
- Pandas Data Structures and OperationsDocument44 pagesPandas Data Structures and OperationsAyush KumarNo ratings yet
- ACFrOgBLSLBEGWl1XMkvkMPbYgZpd-cp8kuuVoM9fkVommOBW4OivZ7ZnL5CoBykDeImy3 9S3 RUnMSV-6MJ1FlyUw5EGIqIxtemr2AK7BMeaLukNSR6c6d TbqtEveAFCFAlq5gRYhWpvfMwlKDocument12 pagesACFrOgBLSLBEGWl1XMkvkMPbYgZpd-cp8kuuVoM9fkVommOBW4OivZ7ZnL5CoBykDeImy3 9S3 RUnMSV-6MJ1FlyUw5EGIqIxtemr2AK7BMeaLukNSR6c6d TbqtEveAFCFAlq5gRYhWpvfMwlKAkashsanthoshNo ratings yet
- Pandas: ImportDocument13 pagesPandas: Importhello100% (1)
- Python LibrariesDocument53 pagesPython Libraries0321-1741No ratings yet
- Data Handing Using Pandas-IDocument46 pagesData Handing Using Pandas-IPriyanka Porwal JainNo ratings yet
- Pandas Intro - Python data analysis libraryDocument33 pagesPandas Intro - Python data analysis libraryVivek MunjayasraNo ratings yet
- SeriesDocument21 pagesSeriesKsNo ratings yet
- panda qus (1)Document8 pagespanda qus (1)Smriti SharmaNo ratings yet
- 2 Python Data ProcessingDocument66 pages2 Python Data ProcessingShaifali Jain100% (2)
- Unit 2Document81 pagesUnit 2jai geraNo ratings yet
- Numpy Basics Introduction ToDocument35 pagesNumpy Basics Introduction Topriyanka sharmaNo ratings yet
- Pandas Notoes For XII PDFDocument12 pagesPandas Notoes For XII PDFManish JainNo ratings yet
- Introduction to NumPy and Pandas for Data ScienceDocument17 pagesIntroduction to NumPy and Pandas for Data ScienceSaif Ali KhanNo ratings yet
- Class 12 Series ProjectDocument14 pagesClass 12 Series ProjectJoshuaNo ratings yet
- ML Lab8Document28 pagesML Lab8Laiba ZaibNo ratings yet
- 22mbada303 Module 4Document32 pages22mbada303 Module 4Kiran VinnuNo ratings yet
- Pandas Ip PDFDocument48 pagesPandas Ip PDFabc100% (1)
- introduction-to-numpy-pandas-and-matplotlibDocument2 pagesintroduction-to-numpy-pandas-and-matplotlibrk73462002No ratings yet
- Study Material IP 2022Document55 pagesStudy Material IP 2022palkisudha274No ratings yet
- Informatics Practices Class 12 Study MaterialDocument128 pagesInformatics Practices Class 12 Study MaterialRishikesh Crafts and TechNo ratings yet
- Final Class XII IP Study Material 2023-24Document20 pagesFinal Class XII IP Study Material 2023-24Akashdeep SinghNo ratings yet
- Sesion 9Document546 pagesSesion 92marlenehh2003No ratings yet
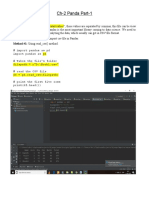
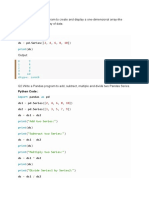
- Ch-2 - Panda - Part-1 - 3rd - DayDocument5 pagesCh-2 - Panda - Part-1 - 3rd - DayRC SharmaNo ratings yet
- Unit-03: Capturing, Preparing and Working With DataDocument41 pagesUnit-03: Capturing, Preparing and Working With DataMubaraka KundawalaNo ratings yet
- On Data Handling Using Pandas-IDocument64 pagesOn Data Handling Using Pandas-IRayansh Chauhan100% (2)
- Numpy Array: Powerful N-dimensional ContainerDocument3 pagesNumpy Array: Powerful N-dimensional ContainerNishanthNo ratings yet
- Pandas Dataframe Export The CSV FileDocument9 pagesPandas Dataframe Export The CSV Fileammouna bengNo ratings yet
- Pip3 Install JupyterDocument16 pagesPip3 Install Jupyterblah blNo ratings yet
- Women’s Christian College Python Programming WebinarDocument96 pagesWomen’s Christian College Python Programming WebinarRajaNo ratings yet
- PandasDocument41 pagesPandasSivam ChinnaNo ratings yet
- sblc-1Document23 pagessblc-1RajNo ratings yet
- Chapter 10 Python PandasDocument40 pagesChapter 10 Python PandasHarshit DayalNo ratings yet
- Ip Study MaterialDocument185 pagesIp Study MaterialADITYA INTERIORNo ratings yet
- Panas Short NotesDocument4 pagesPanas Short NotesMIHIRETEAB LEBASSENo ratings yet
- Course Id:INT 213Document42 pagesCourse Id:INT 213RAM PRAKASHNo ratings yet
- Unit-1: Data Handling - (DH) : PAN DA SDocument12 pagesUnit-1: Data Handling - (DH) : PAN DA SAbhinav KhannaNo ratings yet
- Data Science - Unit IIDocument173 pagesData Science - Unit IIDHEEVIKA SURESH100% (1)
- PandasDocument41 pagesPandasGabriel ChakhvashviliNo ratings yet
- Unit- V Introduction to Pandas in PythonDocument21 pagesUnit- V Introduction to Pandas in PythonLindsey WhiteNo ratings yet
- Python Pandas N-WPS OfficeDocument15 pagesPython Pandas N-WPS OfficeDeepanshu RajputNo ratings yet
- Python LibrariesDocument29 pagesPython LibrariesSubhradeep PalNo ratings yet
- Pandas Questions Ip FileDocument13 pagesPandas Questions Ip FileAISHI SHARMANo ratings yet
- Mysql Connector Statement To PythonDocument1 pageMysql Connector Statement To PythonAISHI SHARMANo ratings yet
- CYBER ETHICS PPT SlidesDocument16 pagesCYBER ETHICS PPT SlidesAISHI SHARMA78% (9)
- MATPLOTLIB NOTES PandasDocument17 pagesMATPLOTLIB NOTES PandasAISHI SHARMANo ratings yet
- The D-And F-Block Elements: Unit 7Document17 pagesThe D-And F-Block Elements: Unit 7Ashika D ChandavarkarNo ratings yet
- Smart Door Locking System Based On OTPFinal DocDocument51 pagesSmart Door Locking System Based On OTPFinal Docmd amaanNo ratings yet
- ELINT Procedures for AJS37 Viggen Radar DetectionDocument5 pagesELINT Procedures for AJS37 Viggen Radar DetectionRudel-ChwNo ratings yet
- Cyber War, Cyber Peace, Stones, and Glass Houses: Gary Mcgraw, Ph.D. Chief Technology Officer, CigitalDocument32 pagesCyber War, Cyber Peace, Stones, and Glass Houses: Gary Mcgraw, Ph.D. Chief Technology Officer, CigitalrodrigoduocNo ratings yet
- NJM13600/13700 Dual Operational Transconductance Amplifier SpecificationsDocument6 pagesNJM13600/13700 Dual Operational Transconductance Amplifier Specificationsavo638No ratings yet
- TowsDocument1 pageTowswishi08100% (1)
- 01v96v2 Es ManualDocument330 pages01v96v2 Es ManualAptaeex ExtremaduraNo ratings yet
- F-050 Impressed Current SystemDocument80 pagesF-050 Impressed Current SystemВасиль Гудзь100% (1)
- Sir C R Reddy College of Engineering Department of Computer Science and EngineeringDocument1 pageSir C R Reddy College of Engineering Department of Computer Science and EngineeringJayaramsai PanchakarlaNo ratings yet
- Role of Computer Systems in Organizational EfficiencyDocument47 pagesRole of Computer Systems in Organizational Efficiencyzelalem wegayehuNo ratings yet
- 2022 TV Firmware Upgrade Instruction T-PTMDEUCDocument5 pages2022 TV Firmware Upgrade Instruction T-PTMDEUCHendrikNo ratings yet
- VP Project Management Director PMO in Boston MA Resume Damnath de TisseraDocument3 pagesVP Project Management Director PMO in Boston MA Resume Damnath de TisseraDamnath De TisseraNo ratings yet
- Delivery Chalan DetailsDocument1 pageDelivery Chalan DetailsDikshant ETINo ratings yet
- Activity 3 THE DATABASE CONCEPTSDocument4 pagesActivity 3 THE DATABASE CONCEPTSRichille SordillaNo ratings yet
- CDBurnerXP license termsDocument1 pageCDBurnerXP license termsAndrei NicoaraNo ratings yet
- Take Home Quizz - Exec HMDocument5 pagesTake Home Quizz - Exec HMbeshfrend'z0% (1)
- 1) - Discuss The Limitations of Memory Management S...Document3 pages1) - Discuss The Limitations of Memory Management S...MyounasNo ratings yet
- Fake News Detection Using Machine LearningDocument4 pagesFake News Detection Using Machine LearningEditor IJTSRDNo ratings yet
- TM Use Common Bus Tools Tech 310812 PDFDocument60 pagesTM Use Common Bus Tools Tech 310812 PDFKaidrick Latrell CorpuzNo ratings yet
- Amoi Lc26t1e 32t1e 37t1e 42t1e (ET)Document120 pagesAmoi Lc26t1e 32t1e 37t1e 42t1e (ET)Dimitris ApostolouNo ratings yet
- SKF Thermal Camera Tkti10Document2 pagesSKF Thermal Camera Tkti10rezandriansyah100% (1)
- Printing Text File in CDocument5 pagesPrinting Text File in CPhuong LeNo ratings yet
- Aktiviti PecahanDocument8 pagesAktiviti PecahanAmalina ZulkifleeNo ratings yet
- Andhra Pradesh Mobile Policy Guidelines 2011Document2 pagesAndhra Pradesh Mobile Policy Guidelines 2011Raja ShekharNo ratings yet
- Kali Linux CommandsDocument6 pagesKali Linux Commandsranjan rajaNo ratings yet
- Wa0010.Document6 pagesWa0010.ivon cruzNo ratings yet
- Applied II NoteDocument171 pagesApplied II NoteAklilu HailuNo ratings yet
- EE2201 Measurement & InstrumentationDocument2 pagesEE2201 Measurement & InstrumentationveguruprasadNo ratings yet
- Coral EpabxDocument25 pagesCoral EpabxMushtaq AhmadNo ratings yet
- Fourier Series Representation of Periodic Signals ExplainedDocument18 pagesFourier Series Representation of Periodic Signals ExplainedAlper KaracakayaNo ratings yet
- 52 GSM BSS Network PS KPI (Downlink TBF Establishment Success Rate) Optimization ManualDocument31 pages52 GSM BSS Network PS KPI (Downlink TBF Establishment Success Rate) Optimization ManualMistero_H100% (4)
- Excel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceFrom EverandExcel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceNo ratings yet
- Clean Code: A Handbook of Agile Software CraftsmanshipFrom EverandClean Code: A Handbook of Agile Software CraftsmanshipRating: 5 out of 5 stars5/5 (13)
- Learn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.From EverandLearn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.Rating: 5 out of 5 stars5/5 (34)
- How to Make a Video Game All By Yourself: 10 steps, just you and a computerFrom EverandHow to Make a Video Game All By Yourself: 10 steps, just you and a computerRating: 5 out of 5 stars5/5 (1)
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- Python Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)From EverandPython Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)Rating: 5 out of 5 stars5/5 (1)
- The Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!From EverandThe Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!Rating: 4.5 out of 5 stars4.5/5 (2)
- HTML, CSS, and JavaScript Mobile Development For DummiesFrom EverandHTML, CSS, and JavaScript Mobile Development For DummiesRating: 4 out of 5 stars4/5 (10)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- GAMEDEV: 10 Steps to Making Your First Game SuccessfulFrom EverandGAMEDEV: 10 Steps to Making Your First Game SuccessfulRating: 4.5 out of 5 stars4.5/5 (12)
- Blockchain: The complete guide to understanding Blockchain Technology for beginners in record timeFrom EverandBlockchain: The complete guide to understanding Blockchain Technology for beginners in record timeRating: 4.5 out of 5 stars4.5/5 (34)
- App Empire: Make Money, Have a Life, and Let Technology Work for YouFrom EverandApp Empire: Make Money, Have a Life, and Let Technology Work for YouRating: 4 out of 5 stars4/5 (21)
- Python Programming : How to Code Python Fast In Just 24 Hours With 7 Simple StepsFrom EverandPython Programming : How to Code Python Fast In Just 24 Hours With 7 Simple StepsRating: 3.5 out of 5 stars3.5/5 (54)
- Coding for Kids Ages 9-15: Simple HTML, CSS and JavaScript lessons to get you started with Programming from ScratchFrom EverandCoding for Kids Ages 9-15: Simple HTML, CSS and JavaScript lessons to get you started with Programming from ScratchRating: 4.5 out of 5 stars4.5/5 (4)
- Mastering JavaScript: The Complete Guide to JavaScript MasteryFrom EverandMastering JavaScript: The Complete Guide to JavaScript MasteryRating: 5 out of 5 stars5/5 (1)
- SQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLFrom EverandSQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLRating: 4.5 out of 5 stars4.5/5 (46)
- ITIL 4: Digital and IT strategy: Reference and study guideFrom EverandITIL 4: Digital and IT strategy: Reference and study guideRating: 5 out of 5 stars5/5 (1)
- Natural Language Processing with Python: Natural Language Processing Using NLTKFrom EverandNatural Language Processing with Python: Natural Language Processing Using NLTKRating: 3.5 out of 5 stars3.5/5 (4)