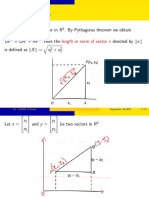
You might also like
- Assignment-Based Subjective QuestionsDocument10 pagesAssignment-Based Subjective QuestionsGopesh Singh100% (1)
- PR2 - PrelimsDocument3 pagesPR2 - PrelimsKaye-C CoronelNo ratings yet
- Mobile Device Detection Through Wifi Probe Request Analysis: Special Section On Data Mining For Internet of ThingsDocument10 pagesMobile Device Detection Through Wifi Probe Request Analysis: Special Section On Data Mining For Internet of ThingsAulia RahmanNo ratings yet
- Reviewer Exercises STATISTICAL METHODS With SolutionDocument16 pagesReviewer Exercises STATISTICAL METHODS With SolutionYhol Villanueva Capuyan100% (2)
- Astm D3681Document8 pagesAstm D3681Viswanath100% (1)
- PSLecture11 2022Document49 pagesPSLecture11 2022KrishNo ratings yet
- PSLecture5 2022Document76 pagesPSLecture5 2022Prachi SharmaNo ratings yet
- PSLecture10 2022Document24 pagesPSLecture10 2022Bimal GayaliNo ratings yet
- Slide ML 0915Document24 pagesSlide ML 0915zentea99No ratings yet
- Lecture 4: Joint Probability Distribution & Limit Theorems: Wisnu Setiadi NugrohoDocument48 pagesLecture 4: Joint Probability Distribution & Limit Theorems: Wisnu Setiadi NugrohoRidwan Putra JNo ratings yet
- 03-Multiple Random Variables-IDocument30 pages03-Multiple Random Variables-ITed Barancira100% (1)
- PSLecture14 2022Document8 pagesPSLecture14 2022KrishNo ratings yet
- Chapter - Three: Two Random VariablesDocument43 pagesChapter - Three: Two Random Variablesየእውነት መንገድNo ratings yet
- Introduction To Probability TheoryDocument9 pagesIntroduction To Probability TheoryarjunvenugopalacharyNo ratings yet
- CHAPTER 03-Random VariableDocument68 pagesCHAPTER 03-Random VariableHaniNo ratings yet
- Unit II - SjitDocument32 pagesUnit II - SjitShreyaNo ratings yet
- Problem Set 1 Introductory EconometricsDocument3 pagesProblem Set 1 Introductory Econometricshanford24gNo ratings yet
- Practice Questions For TT2Document4 pagesPractice Questions For TT2Disha GoelNo ratings yet
- 03-Multiple Random Variables-IDocument30 pages03-Multiple Random Variables-IYohanes FisehaNo ratings yet
- Lec2 IntroToProbabilityAndStatisticsDocument37 pagesLec2 IntroToProbabilityAndStatisticshu jackNo ratings yet
- 03-Multiple Random Variables-IDocument30 pages03-Multiple Random Variables-IGetahun Shanko KefeniNo ratings yet
- Stability of Duodecic Functional Equations in Multi-Banach SpacesDocument2 pagesStability of Duodecic Functional Equations in Multi-Banach SpacesiirNo ratings yet
- 02-Random VariablesDocument49 pages02-Random VariablesYohanes FisehaNo ratings yet
- 8mmpjoint AnnotatedDocument25 pages8mmpjoint AnnotatedAntal TóthNo ratings yet
- Aaoc C111: Probability & Statistics: Bits-Pilani Hyderabad CampusDocument41 pagesAaoc C111: Probability & Statistics: Bits-Pilani Hyderabad CampusDEVANSHI MATHURNo ratings yet
- Estimation of Extreme Quantiles From Heavy-Tailed Distributions in A Semi-Parametric Location-Dispersion Regression ModelDocument19 pagesEstimation of Extreme Quantiles From Heavy-Tailed Distributions in A Semi-Parametric Location-Dispersion Regression ModelAboubacrène Ag AhmadNo ratings yet
- Estimation of Extreme Quantiles From Heavy-Tailed Distributions in A Semi-Parametric Location-Dispersion Regression ModelDocument19 pagesEstimation of Extreme Quantiles From Heavy-Tailed Distributions in A Semi-Parametric Location-Dispersion Regression ModelAboubacrène Ag AhmadNo ratings yet
- Chapter 0Document13 pagesChapter 0nargizireNo ratings yet
- Piecewise Bijective Functions and Continuous InputsDocument19 pagesPiecewise Bijective Functions and Continuous InputsabeastinmeNo ratings yet
- UntitledDocument9 pagesUntitledAkash RupanwarNo ratings yet
- 3 Main specialRVsDocument50 pages3 Main specialRVsHarshit GuptaNo ratings yet
- Some Aspects of Localization Frames: Bhabhuti ChauhanDocument49 pagesSome Aspects of Localization Frames: Bhabhuti ChauhanHemant KumarNo ratings yet
- Chapter2 ProbabilityDocument45 pagesChapter2 ProbabilitywuziqiNo ratings yet
- 5-Multiple Integrals and Their Applications PDFDocument63 pages5-Multiple Integrals and Their Applications PDFLoo Javier Mamani Quea100% (1)
- MATERIAL09Document12 pagesMATERIAL09Oscar yaucobNo ratings yet
- Multiple Random VariablesDocument248 pagesMultiple Random Variablessunnyman9899No ratings yet
- PSLecture9 2022Document54 pagesPSLecture9 2022Bimal GayaliNo ratings yet
- CS236 Homework 1Document4 pagesCS236 Homework 1Raffael YasinNo ratings yet
- MCMC: Gibbs Sampling: D K k1 k+1 DDocument7 pagesMCMC: Gibbs Sampling: D K k1 k+1 DDevendraReddyPoreddyNo ratings yet
- MATERIAL08Document15 pagesMATERIAL08Oscar yaucobNo ratings yet
- Lecture 2Document42 pagesLecture 2Vivi EnneNo ratings yet
- CH-5,6,7,8 and 9Document87 pagesCH-5,6,7,8 and 9Hirpha FayisaNo ratings yet
- 03-Multiple Random Variables-IDocument8 pages03-Multiple Random Variables-Icreate newoneNo ratings yet
- Lecture 4Document16 pagesLecture 4nguyenhoangnguyenntNo ratings yet
- Probability Random Variables Results PVDocument49 pagesProbability Random Variables Results PVemaNo ratings yet
- Statistics Probability Distributions I Is emDocument58 pagesStatistics Probability Distributions I Is emSharanjeet SinghNo ratings yet
- AI-ML Class-14Document13 pagesAI-ML Class-14Mihir PatelNo ratings yet
- Multivariate Statistical DistributionsDocument12 pagesMultivariate Statistical DistributionsBruno Soares de CastroNo ratings yet
- M3 Unit-3Document63 pagesM3 Unit-3Sathvik WorkspaceNo ratings yet
- Partial Differential Equations MSO-203-B: T. Muthukumar Tmk@iitk - Ac.inDocument98 pagesPartial Differential Equations MSO-203-B: T. Muthukumar Tmk@iitk - Ac.inDon eladioNo ratings yet
- JRF Stat STA 2019Document2 pagesJRF Stat STA 2019Yojan SarkarNo ratings yet
- Theories Joint Distribution PDFDocument25 pagesTheories Joint Distribution PDFSundarRajanNo ratings yet
- Tutorial 6Document5 pagesTutorial 6Muhamed zameelNo ratings yet
- Bsm201 Model QuestionsDocument7 pagesBsm201 Model QuestionsamitNo ratings yet
- Innerproduct PrintDocument10 pagesInnerproduct PrintLuthHeldzistNo ratings yet
- Math C191: Mathematics - IDocument78 pagesMath C191: Mathematics - IKevin AdamsNo ratings yet
- F (X, Y) y X 1: Assignment-5 (B)Document4 pagesF (X, Y) y X 1: Assignment-5 (B)harshitNo ratings yet
- Tutsheet 4Document2 pagesTutsheet 4vishnuNo ratings yet
- STA413 ReviewProblems2Document1 pageSTA413 ReviewProblems2zhiying liaoNo ratings yet
- Lecture13 Conditional Distributions and Joint ContinuityDocument8 pagesLecture13 Conditional Distributions and Joint ContinuityVishal AshokNo ratings yet
- 2003 - (DESHPANDE) A Review of Non-Commutative Gauge TheoriesDocument10 pages2003 - (DESHPANDE) A Review of Non-Commutative Gauge Theoriesfaudzi5505No ratings yet
- Formal Concept Analysis: Isabelle BlochDocument18 pagesFormal Concept Analysis: Isabelle BlochAlice VillardièreNo ratings yet
- ML Section19 Sampling MCMCDocument61 pagesML Section19 Sampling MCMCdummyNo ratings yet
- STAT4003 HM 1Document1 pageSTAT4003 HM 1Chan Sze YuenNo ratings yet
- Module II - Ae 6 Accounting Research Method-1Document20 pagesModule II - Ae 6 Accounting Research Method-1claudine domingoNo ratings yet
- Unit 4-Regression and LearningDocument24 pagesUnit 4-Regression and LearningegadydqmdctlfzhnkbNo ratings yet
- Teodorovic (2009) - School EffectivenessDocument19 pagesTeodorovic (2009) - School EffectivenessAlice ChenNo ratings yet
- Educational Assessment of Engineering Students On Foundation Courses in Tertiary Institutions A Case Study of Kebbi State University of Science and Technology Aliero NiDocument10 pagesEducational Assessment of Engineering Students On Foundation Courses in Tertiary Institutions A Case Study of Kebbi State University of Science and Technology Aliero NiSuleiman AbdulrahmanNo ratings yet
- PR2 Summative TestDocument4 pagesPR2 Summative TestRey Julius RanocoNo ratings yet
- Simplified Equations For Shear-Modulus Degradation and Damping of GravelsDocument10 pagesSimplified Equations For Shear-Modulus Degradation and Damping of GravelsSébastien PAILLYNo ratings yet
- Copula RegressionDocument23 pagesCopula RegressionRoyal BengalNo ratings yet
- Quantitative MethodsDocument4 pagesQuantitative MethodsSantos Babylyn DoradoNo ratings yet
- Chapter 5Document19 pagesChapter 5Samuel DebeleNo ratings yet
- Psychological Assessment RationalizationDocument7 pagesPsychological Assessment RationalizationFLORLYN VERALNo ratings yet
- Financial Ratio Analysis As Determinant of Profitability in African Banking IndustryDocument10 pagesFinancial Ratio Analysis As Determinant of Profitability in African Banking IndustryjaneNo ratings yet
- 02.M.E. ConstructionDocument21 pages02.M.E. ConstructionBalakumar JaganathanNo ratings yet
- Introdution To Statistics - University of Pittsburgh - OutlierDocument7 pagesIntrodution To Statistics - University of Pittsburgh - OutlierTheNerdZueroNo ratings yet
- Note Partial Correlation Kom 6115Document14 pagesNote Partial Correlation Kom 6115jia quan gohNo ratings yet
- Statistics For Information TechnologyDocument2 pagesStatistics For Information Technologyhussein.a.ugNo ratings yet
- Open Electives Circular VII Sem AY 2021-22Document31 pagesOpen Electives Circular VII Sem AY 2021-22Pavan KumarNo ratings yet
- Neuroimage: Reports: Timothy Jordan, Mukesh DhamalaDocument10 pagesNeuroimage: Reports: Timothy Jordan, Mukesh DhamalaArtur GuimarãesNo ratings yet
- Reliability and Validity ABORDO - Docx 20230506165009Document20 pagesReliability and Validity ABORDO - Docx 20230506165009AlVinNo ratings yet
- Adversity QuotientDocument22 pagesAdversity QuotientKimson JhunNo ratings yet
- Comparative Study of HDFC Bank SBI Bank MBA ProjectDocument9 pagesComparative Study of HDFC Bank SBI Bank MBA ProjectAsif shaikhNo ratings yet
- BSC StatisticsDocument40 pagesBSC StatisticsVishnupriyaNo ratings yet
- Mas 2Document10 pagesMas 2Krishia GarciaNo ratings yet
- Audit Quality and Financial Reporting of Quoted Natural Resources Firms in NigeriaDocument10 pagesAudit Quality and Financial Reporting of Quoted Natural Resources Firms in NigeriasonyNo ratings yet
- Thogersen 2000Document29 pagesThogersen 2000Cristina NicolaeNo ratings yet
- Financial Literacy of YouthDocument71 pagesFinancial Literacy of YouthTasmay EnterprisesNo ratings yet