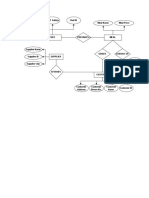
You might also like
- Monetizing Machine Learning: Quickly Turn Python ML Ideas into Web Applications on the Serverless CloudFrom EverandMonetizing Machine Learning: Quickly Turn Python ML Ideas into Web Applications on the Serverless CloudNo ratings yet
- Design Principles ExplainedDocument17 pagesDesign Principles ExplainedAftab Hakki100% (1)
- Professional Test Driven Development with C#: Developing Real World Applications with TDDFrom EverandProfessional Test Driven Development with C#: Developing Real World Applications with TDDNo ratings yet
- What Are Programming Principles?Document6 pagesWhat Are Programming Principles?JosephoffumNo ratings yet
- Agile software development principles and practicesDocument1 pageAgile software development principles and practicesJames BeruegaNo ratings yet
- Extreme ProgrammingDocument15 pagesExtreme ProgrammingSaumya SwapnesawrNo ratings yet
- 7 Ways To Write Cleaner, More Effective CodeDocument5 pages7 Ways To Write Cleaner, More Effective CodeJuan Manuel Antón Bernal100% (1)
- Agile Design Practices: Apparently More Effective TooDocument5 pagesAgile Design Practices: Apparently More Effective TooMayank AgarwalaNo ratings yet
- Am 5Document97 pagesAm 5sakti_badalaNo ratings yet
- Java Means Durga Soft: DURGA SOFTWARE SOLUTIONS, 202 HUDA Maitrivanam, Ameerpet, Hyd. PH: 040-64512786Document9 pagesJava Means Durga Soft: DURGA SOFTWARE SOLUTIONS, 202 HUDA Maitrivanam, Ameerpet, Hyd. PH: 040-64512786Narsi100% (1)
- SEN - Unit 2Document19 pagesSEN - Unit 2Master ArronNo ratings yet
- TOP-DOWN APPROACHDocument7 pagesTOP-DOWN APPROACHvineet883No ratings yet
- Lecture 20: Design Strategy: 20.1process Overview & TestingDocument12 pagesLecture 20: Design Strategy: 20.1process Overview & Testingstef_iosNo ratings yet
- Software DesignDocument5 pagesSoftware Designshaynealmario7No ratings yet
- Chapter 2 Requirement Engineering ProcessDocument19 pagesChapter 2 Requirement Engineering ProcessNDDHSADNo ratings yet
- SOA PatternsDocument11 pagesSOA PatternsCostin StefanNo ratings yet
- 3.design Patterns LAB RecordDocument15 pages3.design Patterns LAB RecordLadi Pradeep KumarNo ratings yet
- Reuse Good Ideas1Document6 pagesReuse Good Ideas1Anonymous IH0vxINo ratings yet
- Fundamentals of Software EngineeringDocument37 pagesFundamentals of Software EngineeringFawaaz ShareefNo ratings yet
- Assignment 3Document10 pagesAssignment 3Anjani Kunwar100% (1)
- Writing A Good ProgramDocument10 pagesWriting A Good Programola pedensNo ratings yet
- Extreme ProgrammingDocument4 pagesExtreme ProgrammingpavithraNo ratings yet
- Importance of Design Patterns and Frameworks For Software DevelopmentDocument4 pagesImportance of Design Patterns and Frameworks For Software DevelopmentsansdipNo ratings yet
- Adaptive Software DevelopmentDocument10 pagesAdaptive Software DevelopmentBintang Polaris100% (1)
- PaigeDocument17 pagesPaigeSHUBHAM POLNo ratings yet
- Concepts of Software Engineering: Strategy DevelopmentDocument62 pagesConcepts of Software Engineering: Strategy DevelopmentSama A ShurrabNo ratings yet
- Introduction to Experiential ExercisesDocument8 pagesIntroduction to Experiential ExercisesAntokaNo ratings yet
- GGGDDocument24 pagesGGGDpoiuret isthisgoodNo ratings yet
- Interview Questions and Answers On SDLCDocument13 pagesInterview Questions and Answers On SDLCPintanaNo ratings yet
- Why Working Together Is Currently HardDocument7 pagesWhy Working Together Is Currently HardNatsu DragneelNo ratings yet
- Good Programming PracticeDocument17 pagesGood Programming PracticeRosette DjeukoNo ratings yet
- Feature-Driven Development-PracticesDocument20 pagesFeature-Driven Development-PracticesVictoria LoveNo ratings yet
- Software RefactoringDocument6 pagesSoftware RefactoringAyesha FayyazNo ratings yet
- Scrum An Extension Pattern Language ForDocument19 pagesScrum An Extension Pattern Language ForMicaela AchilliNo ratings yet
- Seminar Report'03 Extreme ProgrammingDocument32 pagesSeminar Report'03 Extreme Programmingapi-19937584No ratings yet
- Stop Over-Engineering Software with Test-First Programming and RefactoringDocument4 pagesStop Over-Engineering Software with Test-First Programming and Refactoringpc123No ratings yet
- Home Work-11: 4. What Is A Human-Machine Boundary?Document3 pagesHome Work-11: 4. What Is A Human-Machine Boundary?zahed83No ratings yet
- Coding at The Lowest LevelDocument27 pagesCoding at The Lowest LevelnimwijNo ratings yet
- WWW - Assignmentwritingindia.co M: E A D PDocument19 pagesWWW - Assignmentwritingindia.co M: E A D PprofessionalwritersNo ratings yet
- Code 9Document4 pagesCode 9Beru Beru BaneNo ratings yet
- BDD Big Picture - M.VajsDocument9 pagesBDD Big Picture - M.VajsMiloš RistićNo ratings yet
- PF AssignmentDocument5 pagesPF AssignmentSaad ZaheenNo ratings yet
- 1928 - How To Be A ProgrammerDocument59 pages1928 - How To Be A ProgrammerAshish ChoudharyNo ratings yet
- Agile Software Development CDocument17 pagesAgile Software Development CAhsan ChNo ratings yet
- How To Be A ProgrammerDocument55 pagesHow To Be A Programmernaveen karthikeyanNo ratings yet
- DDD-Tight Coupling Between Domain Model and SoftwareDocument27 pagesDDD-Tight Coupling Between Domain Model and SoftwareSatrajit JanaNo ratings yet
- A Use Case-Driven Approach To Requirements GatheringDocument15 pagesA Use Case-Driven Approach To Requirements GatheringSofi KetemaNo ratings yet
- How To Build Reliable CodeDocument3 pagesHow To Build Reliable CodeCarlos SabidoNo ratings yet
- Class Design GuidelinesDocument16 pagesClass Design GuidelinesRenz Casipit100% (1)
- 15 Coding Best PracticesDocument9 pages15 Coding Best PracticesMulata Kahsay100% (1)
- Tao of ReactDocument113 pagesTao of ReactLetícia ChijoNo ratings yet
- Data Abstraction CouplingDocument4 pagesData Abstraction CouplingRANA131No ratings yet
- CEN 4020 Software Engineering Essay No. 1: Debugging methodsDocument9 pagesCEN 4020 Software Engineering Essay No. 1: Debugging methodsLindsey Segal100% (1)
- Python Programming 3 BOOKS IN 1 Learn Machine Learning, Data Science and Analysis With A Crash Course For Beginners. Included Coding Exercises For Artificial Intelligence, Numpy, Pandas and Ipython.Document217 pagesPython Programming 3 BOOKS IN 1 Learn Machine Learning, Data Science and Analysis With A Crash Course For Beginners. Included Coding Exercises For Artificial Intelligence, Numpy, Pandas and Ipython.Alisson SilvaNo ratings yet
- Value of ModelingDocument13 pagesValue of ModelingPannaga RaoNo ratings yet
- The Modular Structure of Complex Systems ExplainedDocument15 pagesThe Modular Structure of Complex Systems ExplainedD_XNo ratings yet
- Solid PrinciplesDocument11 pagesSolid PrinciplesSRISAILAM PYATANo ratings yet
- General Interview Questions For DevelopersDocument6 pagesGeneral Interview Questions For DevelopersMihaela TabaranuNo ratings yet
- Chapter 1 & 2 Questions SummaryDocument10 pagesChapter 1 & 2 Questions SummarySofia LivelyNo ratings yet
- Software Engineering Tutorial2Document3 pagesSoftware Engineering Tutorial2NOOR AZLAN BIN MAHMUDNo ratings yet
- TechsemDocument6 pagesTechsemYogeshwara SNo ratings yet
- WakeupDocument36 pagesWakeupYogeshwara SNo ratings yet
- ThunderDocument11 pagesThunderYogeshwara SNo ratings yet
- StromDocument5 pagesStromYogeshwara SNo ratings yet
- 1122Document1 page1122Yogeshwara SNo ratings yet
- Activity 2Document4 pagesActivity 2Yogeshwara SNo ratings yet
- Hotel ManagementDocument2 pagesHotel ManagementYogeshwara SNo ratings yet
- Insert Single Row Insert Multiple Row Insert Hierarchical RowDocument2 pagesInsert Single Row Insert Multiple Row Insert Hierarchical RowYogeshwara SNo ratings yet
- Pattern Program AssignmentDocument30 pagesPattern Program AssignmentYogeshwara SNo ratings yet
- Reverse String Java Program Preserving SpacesDocument3 pagesReverse String Java Program Preserving SpacesYogeshwara SNo ratings yet
- Component Level DesignDocument2 pagesComponent Level DesignkpsdeviNo ratings yet
- Face Detection Attendance System Using Opencv: Chapter-1Document59 pagesFace Detection Attendance System Using Opencv: Chapter-1nimarose 11No ratings yet
- JPR-Ch-4Document33 pagesJPR-Ch-4GoodNo ratings yet
- Documenting Python Code: A Complete GuideDocument17 pagesDocumenting Python Code: A Complete GuideRavi MistryNo ratings yet
- Python Exception Handling GuideDocument40 pagesPython Exception Handling GuidePrafful JainNo ratings yet
- Btech Software Curriculum N Syllabus 2015Document97 pagesBtech Software Curriculum N Syllabus 2015JagdeshNo ratings yet
- Play With CDocument71 pagesPlay With CRagu RamNo ratings yet
- TAW12 ABAP Workbench Concepts Part I & IIDocument17 pagesTAW12 ABAP Workbench Concepts Part I & IItheict mentorNo ratings yet
- Building Applications in C# - InTLDocument682 pagesBuilding Applications in C# - InTLMustehsan Armaghan Ghouri Magkacgck100% (1)
- Computer Programming - IIDocument2 pagesComputer Programming - IISuresh RamanujamNo ratings yet
- The Fork Join Framework in Java7Document6 pagesThe Fork Join Framework in Java7Nguyen Duc ToanNo ratings yet
- How to Define Generic Methods in JavaDocument14 pagesHow to Define Generic Methods in JavarinkalNo ratings yet
- 12th Computer Science Chapter 1 FunctionsDocument75 pages12th Computer Science Chapter 1 FunctionsVignesh Sdhk Rvs50% (2)
- Mock Test X - Terminal - 2022Document4 pagesMock Test X - Terminal - 2022Harsh abc (Qwerty)No ratings yet
- Simotion New Features V531 ENDocument13 pagesSimotion New Features V531 ENGener TzabNo ratings yet
- Oodj Test1Document4 pagesOodj Test1John WalkerNo ratings yet
- Introduction To WPF: Contoso Healthcare Sample ApplicationDocument37 pagesIntroduction To WPF: Contoso Healthcare Sample Applicationre_sk8No ratings yet
- Laboratory Manual For OOP - JavaDocument84 pagesLaboratory Manual For OOP - JavaMuluken KindachewNo ratings yet
- ABAPDocument334 pagesABAPMuhammad Asghar Khan75% (12)
- Mystic Documentation - Highly-constrained non-convex optimization and uncertainty quantification libraryDocument218 pagesMystic Documentation - Highly-constrained non-convex optimization and uncertainty quantification libraryMohit GuptaNo ratings yet
- Chapter 1)Document111 pagesChapter 1)Dhananjay KumbharNo ratings yet
- Uml & DP Complete MaterialDocument149 pagesUml & DP Complete Materialjyothi .No ratings yet
- Cse3001 Software Engineering: Dr. S M SatapathyDocument60 pagesCse3001 Software Engineering: Dr. S M SatapathyMajety S LskshmiNo ratings yet
- Object Oriented Programming With C++Document121 pagesObject Oriented Programming With C++Mavs ZestNo ratings yet
- Scene BuilderDocument45 pagesScene BuilderGladeas Paembonan100% (1)
- Requirements ModelingDocument39 pagesRequirements ModelingDeshnu SudeepNo ratings yet
- Elementary Concepts of Objects and ClassesDocument10 pagesElementary Concepts of Objects and ClassesGurmehar SinghNo ratings yet
- Java Last Year Question PaperDocument18 pagesJava Last Year Question PaperibrahimnasimshaikhNo ratings yet
- Super Simple TaskerDocument14 pagesSuper Simple Taskerfsteff_ScribdNo ratings yet
- Chapter 8 Talking To WCF and ASMX Services Sample ChapterDocument51 pagesChapter 8 Talking To WCF and ASMX Services Sample Chapterjagdevs7234No ratings yet
- Learn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.From EverandLearn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.Rating: 5 out of 5 stars5/5 (34)
- Excel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceFrom EverandExcel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceNo ratings yet
- Nine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today's ComputersFrom EverandNine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today's ComputersRating: 5 out of 5 stars5/5 (7)
- Linux: The Ultimate Beginner's Guide to Learn Linux Operating System, Command Line and Linux Programming Step by StepFrom EverandLinux: The Ultimate Beginner's Guide to Learn Linux Operating System, Command Line and Linux Programming Step by StepRating: 4.5 out of 5 stars4.5/5 (9)
- Clean Code: A Handbook of Agile Software CraftsmanshipFrom EverandClean Code: A Handbook of Agile Software CraftsmanshipRating: 5 out of 5 stars5/5 (13)
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- Introducing Python: Modern Computing in Simple Packages, 2nd EditionFrom EverandIntroducing Python: Modern Computing in Simple Packages, 2nd EditionRating: 4 out of 5 stars4/5 (7)
- Excel VBA: A Comprehensive, Step-By-Step Guide on Excel VBA Programming Tips and Tricks for Effective StrategiesFrom EverandExcel VBA: A Comprehensive, Step-By-Step Guide on Excel VBA Programming Tips and Tricks for Effective StrategiesNo ratings yet
- Python Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)From EverandPython Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)Rating: 5 out of 5 stars5/5 (1)
- Art of Clean Code: How to Write Codes for HumanFrom EverandArt of Clean Code: How to Write Codes for HumanRating: 3.5 out of 5 stars3.5/5 (7)
- Software Engineering at Google: Lessons Learned from Programming Over TimeFrom EverandSoftware Engineering at Google: Lessons Learned from Programming Over TimeRating: 4 out of 5 stars4/5 (11)
- ITIL 4: Digital and IT strategy: Reference and study guideFrom EverandITIL 4: Digital and IT strategy: Reference and study guideRating: 5 out of 5 stars5/5 (1)
- Agile Metrics in Action: How to measure and improve team performanceFrom EverandAgile Metrics in Action: How to measure and improve team performanceNo ratings yet
- Monitored: Business and Surveillance in a Time of Big DataFrom EverandMonitored: Business and Surveillance in a Time of Big DataRating: 4 out of 5 stars4/5 (1)
- The JavaScript Workshop: Learn to develop interactive web applications with clean and maintainable JavaScript codeFrom EverandThe JavaScript Workshop: Learn to develop interactive web applications with clean and maintainable JavaScript codeRating: 5 out of 5 stars5/5 (3)
- What Algorithms Want: Imagination in the Age of ComputingFrom EverandWhat Algorithms Want: Imagination in the Age of ComputingRating: 3.5 out of 5 stars3.5/5 (41)