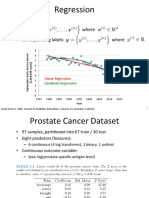
You might also like
- Ansys ManualDocument124 pagesAnsys ManualUdamanNo ratings yet
- Canal RegulatorDocument13 pagesCanal RegulatorBibhuti Bhusan Sahoo100% (1)
- Pulsar 150 PDFDocument41 pagesPulsar 150 PDFAdi Hermansyah100% (3)
- Srikanta Mishra - Machine Learning Applications in Subsurface Energy Resource Management - State of The Art and Future Prognosis-CRC Press (2024)Document379 pagesSrikanta Mishra - Machine Learning Applications in Subsurface Energy Resource Management - State of The Art and Future Prognosis-CRC Press (2024)AgathaNo ratings yet
- Product Position and Overview: Infoplus.21 Foundation CourseDocument22 pagesProduct Position and Overview: Infoplus.21 Foundation Courseursimmi100% (1)
- PVD PreloadingDocument104 pagesPVD PreloadingAkriti Kothiala100% (1)
- Design of Absorber: 5.1 AbsorptionsDocument13 pagesDesign of Absorber: 5.1 AbsorptionsNaya Septri HanaNo ratings yet
- Cooperating Intelligent Systems: Learning From Observations Chapter 18, AIMADocument51 pagesCooperating Intelligent Systems: Learning From Observations Chapter 18, AIMAapi-19643506No ratings yet
- Lec 2Document31 pagesLec 2asasdNo ratings yet
- Bayesian LearningDocument49 pagesBayesian Learning18R 368No ratings yet
- Ai LearningDocument25 pagesAi LearningGi jiNo ratings yet
- ML-02-Concept Linear Regression 100822Document53 pagesML-02-Concept Linear Regression 100822Being IITianNo ratings yet
- DtreesDocument43 pagesDtreesDuy TNo ratings yet
- ML DecisionTreesDocument46 pagesML DecisionTreespranati prasadNo ratings yet
- An Overview of Edward: A Probabilistic Programming System: Dustin Tran Columbia UniversityDocument34 pagesAn Overview of Edward: A Probabilistic Programming System: Dustin Tran Columbia UniversityStanislav SeNo ratings yet
- AI Lecture 12Document49 pagesAI Lecture 12Khalid MahmoodNo ratings yet
- Cooperating Intelligent Systems: Learning From Observations Chapter 18, AIMADocument53 pagesCooperating Intelligent Systems: Learning From Observations Chapter 18, AIMAZoran BogoeskiNo ratings yet
- Machine Learning: Chapter 3. Decision Tree LearningDocument29 pagesMachine Learning: Chapter 3. Decision Tree LearningPanku RangareeNo ratings yet
- Lecturenotes Cse176Document80 pagesLecturenotes Cse176burtNo ratings yet
- DistributionLearn (Shai)Document47 pagesDistributionLearn (Shai)Matei PopoviciNo ratings yet
- Prediction Problems HandoutDocument4 pagesPrediction Problems Handoutkouroshkutm7885No ratings yet
- Statistical Machine Learning-The Basic Approach and Current Research ChallengesDocument35 pagesStatistical Machine Learning-The Basic Approach and Current Research Challengesnikhilesh kumarNo ratings yet
- Maximum Likelihood Hypotheses For Predicting ProbabilitiesDocument10 pagesMaximum Likelihood Hypotheses For Predicting ProbabilitiesChatla ChetanNo ratings yet
- Machine LearningDocument79 pagesMachine LearningLOPASNo ratings yet
- Asset-V1 ColumbiaX+CSMM.102x+1T2018+type@asset+block@ML Lecture1Document17 pagesAsset-V1 ColumbiaX+CSMM.102x+1T2018+type@asset+block@ML Lecture1AdiNo ratings yet
- ML Columbia PDFDocument615 pagesML Columbia PDFAlvaro Jose Rehnfeldt SchmidtNo ratings yet
- Key Notes: Chapter-14 StatisticsDocument2 pagesKey Notes: Chapter-14 StatisticsManu VermaNo ratings yet
- Lesson 3.1 - Supervised Learning Decision TreesDocument51 pagesLesson 3.1 - Supervised Learning Decision TreesTayyaba FaisalNo ratings yet
- Statistical Machine Learning-The Basic Approach and Current Research ChallengesDocument35 pagesStatistical Machine Learning-The Basic Approach and Current Research ChallengesD'reef Newton 'dududpersonz'No ratings yet
- Overview and A Machine Learning AlgorithmDocument31 pagesOverview and A Machine Learning Algorithmmrt5000No ratings yet
- CPSC340: Entropy and Maximum LikelihoodDocument19 pagesCPSC340: Entropy and Maximum LikelihoodbzsahilNo ratings yet
- ECS171: Machine Learning: Lecture 1: Overview of Class, LFD 1.1, 1.2Document29 pagesECS171: Machine Learning: Lecture 1: Overview of Class, LFD 1.1, 1.2svwnerlgwrNo ratings yet
- 2-Inductive LearningDocument37 pages2-Inductive LearningKarishma JaniNo ratings yet
- Lecture NotesDocument86 pagesLecture NotesShweta ChavanNo ratings yet
- Lecturenotes PDFDocument80 pagesLecturenotes PDFdinesharulNo ratings yet
- Probability DistributionDocument22 pagesProbability DistributionReadoan Khan100% (1)
- Learning: Book: Artificial Intelligence, A Modern Approach (Russell & Norvig)Document22 pagesLearning: Book: Artificial Intelligence, A Modern Approach (Russell & Norvig)Mustefa MohammedNo ratings yet
- Gonzalez 2021Document67 pagesGonzalez 2021Harrison FreyNo ratings yet
- Class 16 Decision TreeDocument45 pagesClass 16 Decision TreeSumana BasuNo ratings yet
- Learning Theory: Machine Learning 10 - 601B Seyoung KimDocument44 pagesLearning Theory: Machine Learning 10 - 601B Seyoung KimShreyansh KothariNo ratings yet
- Algorithms: The Basic Methods Instance-Based Learning: Data ScienceDocument17 pagesAlgorithms: The Basic Methods Instance-Based Learning: Data ScienceRagini GuptaNo ratings yet
- Introduction To Machine LearningDocument126 pagesIntroduction To Machine LearningNandakumar NachimuthuNo ratings yet
- New 2019 QCDocument109 pagesNew 2019 QChardik desaiNo ratings yet
- Lecture8 - Learning TheoryDocument19 pagesLecture8 - Learning TheoryPacket MancerNo ratings yet
- Module 3 - Critical PointsDocument19 pagesModule 3 - Critical PointsMaddyyyNo ratings yet
- CH2 ConceptLearningDocument38 pagesCH2 ConceptLearningraneemraneem1209No ratings yet
- Ch02 DecisionTreeDocument41 pagesCh02 DecisionTreeTHINHNo ratings yet
- Bayesian Inference: A Practical Primer: OutlineDocument28 pagesBayesian Inference: A Practical Primer: OutlineDrProtektorNo ratings yet
- NNMLDocument113 pagesNNMLshyamd4No ratings yet
- Machine Learning and Neural Networks: Riccardo RizzoDocument113 pagesMachine Learning and Neural Networks: Riccardo RizzoRamakrishnaRao SoogooriNo ratings yet
- Interactive Theorem Proving: Jeremy AvigadDocument66 pagesInteractive Theorem Proving: Jeremy AvigadLauro EncisoNo ratings yet
- Bark08 Ghahramani Samlbb 01Document26 pagesBark08 Ghahramani Samlbb 01Shifath NafisNo ratings yet
- ProbabilityDocument36 pagesProbabilitya.mukhtarbekkyzyNo ratings yet
- Gonzalez 2020Document79 pagesGonzalez 2020hu jackNo ratings yet
- Algo DesignDocument5 pagesAlgo DesignRohith AddagatlaNo ratings yet
- 4 Spreadsheet Simulation BasicsDocument11 pages4 Spreadsheet Simulation BasicsAbdu AbdoulayeNo ratings yet
- Lecture 8 - MATH 403 - DISCRETE PROBABILITY DISTRIBUTIONSDocument6 pagesLecture 8 - MATH 403 - DISCRETE PROBABILITY DISTRIBUTIONSJoshua RamirezNo ratings yet
- Aiml Lab Exp 1 (Find S)Document24 pagesAiml Lab Exp 1 (Find S)priyanka tataNo ratings yet
- Statistical Inference Point Estimators Estimating The Population Mean Using Confidence IntervalsDocument40 pagesStatistical Inference Point Estimators Estimating The Population Mean Using Confidence IntervalsJuanNo ratings yet
- Decision Trees: ClassifierDocument23 pagesDecision Trees: ClassifierHarsha VardhanNo ratings yet
- Term 1: Business Statistics: Session 3: Discrete Probability DistributionsDocument13 pagesTerm 1: Business Statistics: Session 3: Discrete Probability DistributionsTanuj LalchandaniNo ratings yet
- Stat 535 C - Statistical Computing & Monte Carlo Methods: Arnaud DoucetDocument23 pagesStat 535 C - Statistical Computing & Monte Carlo Methods: Arnaud DoucetTalvany Luis de BarrosNo ratings yet
- Om's PPT MainDocument56 pagesOm's PPT MainÖm PräkåshNo ratings yet
- 02 Conceptlearning - PrinterDocument41 pages02 Conceptlearning - PrinterVikalp Ku GuptaNo ratings yet
- IEOR 160 Partial Lecture Notes 2017Document33 pagesIEOR 160 Partial Lecture Notes 2017Nate ArmstrongNo ratings yet
- Chapter 3Document33 pagesChapter 3VaradharajanSrinivasanNo ratings yet
- Class 2 ADocument32 pagesClass 2 AAgathaNo ratings yet
- Class 1 CDocument14 pagesClass 1 CAgathaNo ratings yet
- Class 2 BDocument10 pagesClass 2 BAgathaNo ratings yet
- Class 2 CDocument10 pagesClass 2 CAgathaNo ratings yet
- Class 1 BDocument14 pagesClass 1 BAgathaNo ratings yet
- Class 1 ADocument8 pagesClass 1 AAgathaNo ratings yet
- A Novel Approach To Reservoir Simulation of Hydraulic Fractures Performance Improvement Using Pseudo Well Connections - A Lokhandwala Et Al. 2022Document11 pagesA Novel Approach To Reservoir Simulation of Hydraulic Fractures Performance Improvement Using Pseudo Well Connections - A Lokhandwala Et Al. 2022AgathaNo ratings yet
- IPTC-21318-MS Utilizing Pseudo Well Connections To Simulate Multi-Stage Hydraulic Fracturing - Example Based On The Study of A Tight Gas AssetDocument13 pagesIPTC-21318-MS Utilizing Pseudo Well Connections To Simulate Multi-Stage Hydraulic Fracturing - Example Based On The Study of A Tight Gas AssetAgathaNo ratings yet
- Machine Learning Algorithms - A Review: January 2019Document7 pagesMachine Learning Algorithms - A Review: January 2019Nitin PrasadNo ratings yet
- Unstructured Grid GenerationDocument12 pagesUnstructured Grid GenerationAgathaNo ratings yet
- 31-12-2022 - SR - Super60 - NUCLEUS & STERLING - BT - Jee-Main-PTM-16 - KEY & Sol'SDocument12 pages31-12-2022 - SR - Super60 - NUCLEUS & STERLING - BT - Jee-Main-PTM-16 - KEY & Sol'SSameena LoniNo ratings yet
- Siddartha Institute of Science and Technoloy, Puttur: Seminar On Audio SpotlightingDocument19 pagesSiddartha Institute of Science and Technoloy, Puttur: Seminar On Audio SpotlightingRasiNo ratings yet
- New Microsoft Office Word DocumentDocument20 pagesNew Microsoft Office Word DocumentVinay KumarNo ratings yet
- Job Salary PredictionDocument23 pagesJob Salary PredictionShah Momtaj Ala Hriday 171-15-8834No ratings yet
- Lattice Structure Design For AmDocument9 pagesLattice Structure Design For AmNishar Alam Khan 19MCD0042No ratings yet
- K-D Hawk: Manitou North America, IncDocument334 pagesK-D Hawk: Manitou North America, IncRazvan MitruNo ratings yet
- Cooling Water CircuitDocument3 pagesCooling Water CircuitJamil AhmedNo ratings yet
- GWRS5500Document13 pagesGWRS5500Andrew HartNo ratings yet
- MAT3700-MayJune ExamDocument3 pagesMAT3700-MayJune ExamNhlanhla NdebeleNo ratings yet
- CharacterizigPlant Canopies With Hemispherical PhotographsDocument16 pagesCharacterizigPlant Canopies With Hemispherical PhotographsGabriel TiveronNo ratings yet
- WBSETCL Suggestive Paper..Document10 pagesWBSETCL Suggestive Paper..Pà PáïNo ratings yet
- Buck Boost IN7900Document12 pagesBuck Boost IN7900Adam StroufNo ratings yet
- Rational Algebraic Expressions: ObjectivesDocument11 pagesRational Algebraic Expressions: ObjectivesSonny ArgolidaNo ratings yet
- Cabinas de Bioseguridad HealforceDocument8 pagesCabinas de Bioseguridad HealforceJose HurtadoNo ratings yet
- Binary Dependent VarDocument5 pagesBinary Dependent VarManali PawarNo ratings yet
- Report On Earthquake Resistance Design of Building StructureDocument40 pagesReport On Earthquake Resistance Design of Building Structuremandira maharjanNo ratings yet
- Traffic Accidents - Balai Polis Trafik Jalan Tun H.SDocument3 pagesTraffic Accidents - Balai Polis Trafik Jalan Tun H.SsimoniaNo ratings yet
- The Effect of Backrest Roller On Warp Tension in Modern LoomDocument11 pagesThe Effect of Backrest Roller On Warp Tension in Modern LoomRavi KumarNo ratings yet
- Unit 3 Study Guide and ExercisesDocument2 pagesUnit 3 Study Guide and ExercisesTuan NguyenNo ratings yet
- ME201 Material Science & Engineering: Imperfections in SolidsDocument30 pagesME201 Material Science & Engineering: Imperfections in SolidsAmar BeheraNo ratings yet
- Oxyacids of SulphurDocument29 pagesOxyacids of SulphurSumaira Yasmeen100% (1)
- Ladblock PDFDocument542 pagesLadblock PDFrogernarvaezNo ratings yet
- Sakshi: 7.coordinate GeometryDocument3 pagesSakshi: 7.coordinate GeometryMartyn MartynNo ratings yet
- 7 Maths em 2020-21Document326 pages7 Maths em 2020-21ThNo ratings yet