You might also like
- Indicator Name: Weight-For-Height - 2SD (Wasting) : 1. WHO Child Growth Standards 2006Document1,086 pagesIndicator Name: Weight-For-Height - 2SD (Wasting) : 1. WHO Child Growth Standards 2006Satesh BalachantharNo ratings yet
- UNICEF WHO WB Global Expanded Databases Stunting April 2021Document1,032 pagesUNICEF WHO WB Global Expanded Databases Stunting April 2021sajjad khanNo ratings yet
- Chapter Two StatiDocument25 pagesChapter Two Statidimberu yirgaNo ratings yet
- Weight-for-height >+2SD (Overweight) PercentageDocument1,340 pagesWeight-for-height >+2SD (Overweight) PercentageonnNo ratings yet
- JJU Statistics Student GuideDocument125 pagesJJU Statistics Student Guideibrahim abdiNo ratings yet
- Combining Satellite Imagery and Machine Learning To Predict PovertyDocument6 pagesCombining Satellite Imagery and Machine Learning To Predict PovertyKennNo ratings yet
- Intro to StatisticsDocument22 pagesIntro to StatisticsShimelis TesemaNo ratings yet
- Mid Term 1 Practice Packet vs2Document15 pagesMid Term 1 Practice Packet vs2Kayanna HallNo ratings yet
- 1 s2.0 S0033350620303206 MainDocument7 pages1 s2.0 S0033350620303206 MainNazwa AnnisaNo ratings yet
- Sampling DistributionDocument10 pagesSampling DistributionvarunNo ratings yet
- Smat3: Statistics and RobabilityDocument8 pagesSmat3: Statistics and RobabilityMs. ArceñoNo ratings yet
- F00007942-WV6 Results by Country v20180912 PDFDocument898 pagesF00007942-WV6 Results by Country v20180912 PDFAkashDebNo ratings yet
- SOCIAL STUDIES OFFICIAL SBA GUIDE. 2015 07 10 2015 EditionDocument18 pagesSOCIAL STUDIES OFFICIAL SBA GUIDE. 2015 07 10 2015 Editionnivea roperNo ratings yet
- 3 IS Module 5Document11 pages3 IS Module 5Hiezeyl Ymana GuntangNo ratings yet
- ATP 2009 Secure Testing AWDocument21 pagesATP 2009 Secure Testing AWapi-13976781No ratings yet
- Chapter 3Document8 pagesChapter 3Cherry Lane LepuraNo ratings yet
- Q4 Module 8 9Document17 pagesQ4 Module 8 9Reymark YensonNo ratings yet
- GMS 2014 Module 2Document113 pagesGMS 2014 Module 2chiko kalindaNo ratings yet
- ST2187 Block 2Document27 pagesST2187 Block 2Joseph MatthewNo ratings yet
- CHAPTER THREE ShakiratDocument3 pagesCHAPTER THREE ShakiratPrinceNo ratings yet
- MAT105 STUDY GUIDEDocument14 pagesMAT105 STUDY GUIDEbalikstiamyuNo ratings yet
- MATH 101-WEEK 7-8-HANDOUT-Managing and Understanding DataDocument16 pagesMATH 101-WEEK 7-8-HANDOUT-Managing and Understanding DataJeann DelacruzNo ratings yet
- Math1530finalreview NospacesDocument10 pagesMath1530finalreview Nospacesapi-502745314No ratings yet
- Chapter 3Document7 pagesChapter 3Dee Bonah DearNo ratings yet
- Paper MB0040 Full AssignmentDocument9 pagesPaper MB0040 Full AssignmentHiren RaichadaNo ratings yet
- Auditors' Selection of Tolerable Error and Risk Levels in The Context of Sample Size Decisions: A Cross-Cultural ExperimentDocument14 pagesAuditors' Selection of Tolerable Error and Risk Levels in The Context of Sample Size Decisions: A Cross-Cultural ExperimentgigitoNo ratings yet
- STA 324 Survey $ SamplingDocument98 pagesSTA 324 Survey $ SamplingLedu martinzNo ratings yet
- Paper en Word - InglésDocument6 pagesPaper en Word - Inglésexfirme exfirmeNo ratings yet
- Importance of statistics in researchDocument5 pagesImportance of statistics in researchWazaNo ratings yet
- Team Assignment Report - 3ADocument28 pagesTeam Assignment Report - 3AHoàng Minh ChuNo ratings yet
- PublicationDocument7 pagesPublicationAkalyaNo ratings yet
- Stansa23z - 2023 - Basic StatisticsDocument10 pagesStansa23z - 2023 - Basic Statisticsaudreycelestine8No ratings yet
- Walden University RSCH 8210: Quantitative Reasoning and Analysis Dr. Randy Heinrich September 19, 2021Document9 pagesWalden University RSCH 8210: Quantitative Reasoning and Analysis Dr. Randy Heinrich September 19, 2021Chelsea LynnNo ratings yet
- Study of Profiling The Typical Fraudster in The General Education Sector in ZambiaDocument9 pagesStudy of Profiling The Typical Fraudster in The General Education Sector in ZambiaEditor IjasreNo ratings yet
- Likert Scale Survey AnalysisDocument8 pagesLikert Scale Survey AnalysisSynthia AlamNo ratings yet
- Chapter 3 ResearchDocument6 pagesChapter 3 ResearchJay BilaroNo ratings yet
- FV ZDC 5 H 2 AE6 JNK QXD 0 MyDocument28 pagesFV ZDC 5 H 2 AE6 JNK QXD 0 Myaacreation666No ratings yet
- Lesson 2Document25 pagesLesson 2Tri WidyastutiNo ratings yet
- Data On Vietnamese Students' Acceptance of Using Vcts For Distance Learning During The Covid-19 PandemicDocument6 pagesData On Vietnamese Students' Acceptance of Using Vcts For Distance Learning During The Covid-19 PandemicNgan DoanNo ratings yet
- Assessment 3Document1 pageAssessment 3Richard MacoNo ratings yet
- Paper Solution of RM. UNIT - 2,3,4Document15 pagesPaper Solution of RM. UNIT - 2,3,4arbazkhan13218980No ratings yet
- ACFrOgDvPXMbgn-8KJn3MpIEqU7Ac6nsCWNjLhSoJ9U8NhVwZ56PBEBGQRZVkI8 WrSFP9M yuGJZWe3EiqY5z5ZupkpgRoSyaipeRU9g3Dn21k5S4Nxfmp8TFDJehxlpedHUouBv QGn0geh1fpDocument9 pagesACFrOgDvPXMbgn-8KJn3MpIEqU7Ac6nsCWNjLhSoJ9U8NhVwZ56PBEBGQRZVkI8 WrSFP9M yuGJZWe3EiqY5z5ZupkpgRoSyaipeRU9g3Dn21k5S4Nxfmp8TFDJehxlpedHUouBv QGn0geh1fpSYAZANA FIRAS SAMATNo ratings yet
- Chapter 1Document45 pagesChapter 1lil lordNo ratings yet
- 315lecturech1 2 4Document19 pages315lecturech1 2 4noayran120No ratings yet
- 12 Unit8Document48 pages12 Unit8mesfinNo ratings yet
- HNS B308 Biostatistics Msa CampusDocument7 pagesHNS B308 Biostatistics Msa Campusjamilasaeed777No ratings yet
- DEG ASM ReportDocument38 pagesDEG ASM ReportDarrenyongweihanyahoo.com DarrenNo ratings yet
- CHAPTER 3 & Questionnaire Psychosocial Determinants of Voting Behavior of Youths in Rivers StateDocument3 pagesCHAPTER 3 & Questionnaire Psychosocial Determinants of Voting Behavior of Youths in Rivers StateIkirika HopeNo ratings yet
- Statistics Overview: Understanding Data TypesDocument10 pagesStatistics Overview: Understanding Data TypesChristine Kaye DamoloNo ratings yet
- Factors Affecting Business Survival in SMEsDocument45 pagesFactors Affecting Business Survival in SMEsFawazNo ratings yet
- Does Eye Color Depend On Gender? It Might Depend On Who or How You AskDocument11 pagesDoes Eye Color Depend On Gender? It Might Depend On Who or How You AskAkhmadRidhoAshariansyahNo ratings yet
- Chapter III - Revised No.2Document10 pagesChapter III - Revised No.2Nigel MadriñanNo ratings yet
- (Final) Assignment 5 (Methodology - Data Processing (Part 2) )Document14 pages(Final) Assignment 5 (Methodology - Data Processing (Part 2) )Christinus NgNo ratings yet
- Meaning and Importance of Statistics in Decision MakingDocument134 pagesMeaning and Importance of Statistics in Decision MakingNorjehanie AliNo ratings yet
- Research Methodology AnalysisDocument27 pagesResearch Methodology AnalysisJoseph JboyNo ratings yet
- MMW Group-4 Lesson 4 Data ManagementDocument68 pagesMMW Group-4 Lesson 4 Data ManagementRey MarkNo ratings yet
- Chapter IiiDocument6 pagesChapter IiiPaul Bryan BronNo ratings yet
- Introduction To Business Statistics Through R Software: SoftwareFrom EverandIntroduction To Business Statistics Through R Software: SoftwareNo ratings yet
- MCDP 5 PlanningDocument107 pagesMCDP 5 PlanningVader559No ratings yet
- MCDP 3 Expeditionary OperationsDocument153 pagesMCDP 3 Expeditionary OperationsJosé Ángel Pérez TapiasNo ratings yet
- Ways To Overcome Emotional and Psychological TraumDocument5 pagesWays To Overcome Emotional and Psychological TraumJosé Ángel Pérez TapiasNo ratings yet
- The Bride Gathering Cult PhenomenonDocument4 pagesThe Bride Gathering Cult PhenomenonJosé Ángel Pérez TapiasNo ratings yet
- The Paradox of Declining Female HappinessDocument49 pagesThe Paradox of Declining Female HappinessJosé Ángel Pérez TapiasNo ratings yet
- S0 04 PRF JPabon Filosf 2020 III - Ingles I - Verb ListDocument2 pagesS0 04 PRF JPabon Filosf 2020 III - Ingles I - Verb ListJosé Ángel Pérez TapiasNo ratings yet
- The Bride Gathering Cult PhenomenonDocument4 pagesThe Bride Gathering Cult PhenomenonJosé Ángel Pérez TapiasNo ratings yet
- A. Lesson Preview / Review: This Document Is The Property of PHINMA EDUCATIONDocument11 pagesA. Lesson Preview / Review: This Document Is The Property of PHINMA EDUCATIONTherese Anne ArmamentoNo ratings yet
- Abbadvant 800 XaDocument9 pagesAbbadvant 800 XaAlexNo ratings yet
- TaxonomyDocument56 pagesTaxonomyKrezia Mae SolomonNo ratings yet
- Chapter 2 Research and DesignDocument24 pagesChapter 2 Research and Designalvin salesNo ratings yet
- CENELEC RA STANDARDS CATALOGUEDocument17 pagesCENELEC RA STANDARDS CATALOGUEHamed AhmadnejadNo ratings yet
- TN Govt RecruitmentDocument12 pagesTN Govt RecruitmentPriyanka ShankarNo ratings yet
- NView NNM (V5) Operation Guide PDFDocument436 pagesNView NNM (V5) Operation Guide PDFAgoez100% (1)
- MPU 2232 Chapter 5-Marketing PlanDocument27 pagesMPU 2232 Chapter 5-Marketing Plandina azmanNo ratings yet
- Introduction To Google SheetDocument14 pagesIntroduction To Google SheetJohn Rey Radoc100% (1)
- Day3 PESTLE AnalysisDocument13 pagesDay3 PESTLE AnalysisAmit AgrawalNo ratings yet
- 5e3 Like ApproachDocument1 page5e3 Like Approachdisse_detiNo ratings yet
- CopyofCopyofMaldeepSingh Jawanda ResumeDocument2 pagesCopyofCopyofMaldeepSingh Jawanda Resumebob nioNo ratings yet
- Administration and Supervisory Uses of Test and Measurement - Coronado, Juliet N.Document23 pagesAdministration and Supervisory Uses of Test and Measurement - Coronado, Juliet N.Juliet N. Coronado89% (9)
- Astm D 4417Document4 pagesAstm D 4417Javier Celada0% (1)
- List of Candidates for BUDI Scholarship 2016Document9 pagesList of Candidates for BUDI Scholarship 2016Andriawan Mora Anggi HarahapNo ratings yet
- 2024 Yoga Vidya Training FormDocument8 pages2024 Yoga Vidya Training FormJohnNo ratings yet
- Grammar Notes-February2017 - by Aslinda RahmanDocument41 pagesGrammar Notes-February2017 - by Aslinda RahmanNadia Anuar100% (1)
- EPON ONU with 4FE+WiFi EONU-04WDocument4 pagesEPON ONU with 4FE+WiFi EONU-04WAndres Alberto ParraNo ratings yet
- Appendix A - Status Messages: Armed. Bad Snubber FuseDocument9 pagesAppendix A - Status Messages: Armed. Bad Snubber Fuse이민재No ratings yet
- Consumer PerceptionDocument61 pagesConsumer PerceptionPrakhar DwivediNo ratings yet
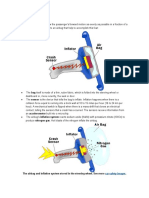
- Airbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreDocument5 pagesAirbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreShivankur HingeNo ratings yet
- FSA&V Case StudyDocument10 pagesFSA&V Case StudyAl Qur'anNo ratings yet
- Handwashing and Infection ControlDocument23 pagesHandwashing and Infection ControlLiane BartolomeNo ratings yet
- The Facility Manager's HandbookDocument362 pagesThe Facility Manager's HandbookLuân Châu100% (14)
- ANNEXURE IV Dec 2022 enDocument17 pagesANNEXURE IV Dec 2022 enadvocacyindyaNo ratings yet
- Operational Readiness Guide - 2017Document36 pagesOperational Readiness Guide - 2017albertocm18100% (2)
- Tem 2final PDFDocument9 pagesTem 2final PDFSkuukzky baeNo ratings yet
- Annual Reading Plan - Designed by Pavan BhattadDocument12 pagesAnnual Reading Plan - Designed by Pavan BhattadFarhan PatelNo ratings yet
- The Essential Guide To Data in The Cloud:: A Handbook For DbasDocument20 pagesThe Essential Guide To Data in The Cloud:: A Handbook For DbasInes PlantakNo ratings yet