You might also like
- Robot perception of environment impedanceDocument6 pagesRobot perception of environment impedanceVerdi bobNo ratings yet
- Contact Stiffness and Damping Estimation For Robotic SystemsDocument17 pagesContact Stiffness and Damping Estimation For Robotic SystemsNguyễn Anh SơnNo ratings yet
- Multiple Impedance Control For Object ManipulationDocument7 pagesMultiple Impedance Control For Object ManipulationluukverstegenNo ratings yet
- Motion and Force Control of Robot ManipulatorsDocument6 pagesMotion and Force Control of Robot ManipulatorsSajani N. BannekaNo ratings yet
- Force-Impedance Control: A New Robotic Manipulation StrategyDocument12 pagesForce-Impedance Control: A New Robotic Manipulation StrategycmkorpelaNo ratings yet
- Inverse Kinematics Solution Using ANFIS Neural NetworkDocument3 pagesInverse Kinematics Solution Using ANFIS Neural NetworkDilek METİNNo ratings yet
- Design of Adaptive-Robust Finite-Time Nonlinear Control Inputs For Uncertain Robot ManipulatorsDocument7 pagesDesign of Adaptive-Robust Finite-Time Nonlinear Control Inputs For Uncertain Robot ManipulatorsMartino Ojwok AjangnayNo ratings yet
- CarnighanICRA2004197 WE-10 3Document6 pagesCarnighanICRA2004197 WE-10 3baixiu0813No ratings yet
- Dynamic control of redundant manipulators for obstacle avoidanceDocument16 pagesDynamic control of redundant manipulators for obstacle avoidanceRatnadeep AndureNo ratings yet
- Hybrid Control of Load Simulator For Unmanned Aerial Vehicle Based On Wavelet NetworksDocument5 pagesHybrid Control of Load Simulator For Unmanned Aerial Vehicle Based On Wavelet NetworksPhuc Pham XuanNo ratings yet
- Clei2012 294Document7 pagesClei2012 294danioiNo ratings yet
- Dynamic Surface Control-Backstepping Based Impedance Control For 5-DOF Flexible Joint RobotsDocument9 pagesDynamic Surface Control-Backstepping Based Impedance Control For 5-DOF Flexible Joint RobotsinfodotzNo ratings yet
- Electromechanical System Simulation With Models Generated From Finite Element SolutionDocument4 pagesElectromechanical System Simulation With Models Generated From Finite Element SolutionDimeshNo ratings yet
- PID Control Dynamics of A Robotic Arm Manipulator PDFDocument7 pagesPID Control Dynamics of A Robotic Arm Manipulator PDFMourad KattassNo ratings yet
- Free Vibration Analysis Using EFGMDocument9 pagesFree Vibration Analysis Using EFGMsushant kumarNo ratings yet
- Free Vibration Analysis Using EFGMDocument9 pagesFree Vibration Analysis Using EFGMsushant kumarNo ratings yet
- Zeng (1997) An Overview of Robot Force ControlDocument10 pagesZeng (1997) An Overview of Robot Force ControloliveirarogerioNo ratings yet
- Small Signal Modeling and Analysis of Synchronverters: Zhou Wei, Chen Jie and Gong ChunyingDocument5 pagesSmall Signal Modeling and Analysis of Synchronverters: Zhou Wei, Chen Jie and Gong ChunyingEnimien AymenNo ratings yet
- Analysis of Lorentz and Saliency Forces PDFDocument4 pagesAnalysis of Lorentz and Saliency Forces PDFIvan VazdarNo ratings yet
- Oscillatory Motion Control of Hinged Body Using ControllerDocument8 pagesOscillatory Motion Control of Hinged Body Using ControllerInternational Journal of Research in Engineering and TechnologyNo ratings yet
- Amiri 2008Document6 pagesAmiri 2008Leroy Lionel SonfackNo ratings yet
- Sitae Kim, Woosung In, Moonki Kim, : Sungcheul Lee Jay I. Jeong and Jongwon KimDocument8 pagesSitae Kim, Woosung In, Moonki Kim, : Sungcheul Lee Jay I. Jeong and Jongwon Kim07clc_pfievNo ratings yet
- Application of Differential Transform Method in Free Vibration Analysis of Rotating Non-Prismatic BeamsDocument8 pagesApplication of Differential Transform Method in Free Vibration Analysis of Rotating Non-Prismatic BeamsKhairul Anuar RahmanNo ratings yet
- Simulation and Control Design of An Uniaxial Magnetic Levitation SystemDocument6 pagesSimulation and Control Design of An Uniaxial Magnetic Levitation SystemElmer Mamani PretelNo ratings yet
- Spectra and Pseudospectra of Waveform Relaxation OperatorsDocument19 pagesSpectra and Pseudospectra of Waveform Relaxation OperatorsShalini GuptaNo ratings yet
- Dynamic Characterisation OF A Flexible Manipulator System: Theory and ExperimentsDocument6 pagesDynamic Characterisation OF A Flexible Manipulator System: Theory and ExperimentsselvamNo ratings yet
- Deep ONetDocument22 pagesDeep ONet梁帅哲No ratings yet
- PID Controller Design For A Magnetic Levitation System Using An IntelligentDocument8 pagesPID Controller Design For A Magnetic Levitation System Using An Intelligentambachew bizunehNo ratings yet
- Finite Element Implementation of Incompressible, Transversely Isotropic HyperelasticityDocument22 pagesFinite Element Implementation of Incompressible, Transversely Isotropic HyperelasticityManuelNo ratings yet
- Preliminary Study On Magnetic Levitation Modeling Using PID ControlDocument7 pagesPreliminary Study On Magnetic Levitation Modeling Using PID ControlSkyFaLL-CSNo ratings yet
- s14 CompletareDocument14 pagess14 CompletareLaura NicoletaNo ratings yet
- From Differential Equations To Multilayer Neural Network ModelsDocument9 pagesFrom Differential Equations To Multilayer Neural Network ModelsAman JalanNo ratings yet
- Larreal Murcia Nuñez 2022Document13 pagesLarreal Murcia Nuñez 2022Daniel NuñezNo ratings yet
- Electromagnetic Levitation System: An Experimental ApproachDocument7 pagesElectromagnetic Levitation System: An Experimental Approachsh1n00b1No ratings yet
- Interactions between Electromagnetic Fields and Matter: Vieweg Tracts in Pure and Applied PhysicsFrom EverandInteractions between Electromagnetic Fields and Matter: Vieweg Tracts in Pure and Applied PhysicsNo ratings yet
- Out-of-step blocking function using mathematical morphologyDocument7 pagesOut-of-step blocking function using mathematical morphologyraamNo ratings yet
- Reconstruction of Seismic Data With Least Squares Inversion Based On Nonuniform Fast Fourier TransformDocument8 pagesReconstruction of Seismic Data With Least Squares Inversion Based On Nonuniform Fast Fourier TransformHumbang PurbaNo ratings yet
- A Control of MR Damper Using Feed-Forward Neural Network Without Force SensorDocument4 pagesA Control of MR Damper Using Feed-Forward Neural Network Without Force SensorhafizalNo ratings yet
- Modelica-Based Modeling and Simulation of Satellite On-Orbit Deployment and Attitude ControlDocument9 pagesModelica-Based Modeling and Simulation of Satellite On-Orbit Deployment and Attitude ControlGkkNo ratings yet
- Lindsey Hines Final Report PDFDocument21 pagesLindsey Hines Final Report PDFclimax1364No ratings yet
- International Conference NeruDocument10 pagesInternational Conference NeruNeeru SinghNo ratings yet
- On Characterising Microelectromechanical Processes Using Coupled ResonatorsDocument8 pagesOn Characterising Microelectromechanical Processes Using Coupled Resonatorsbcqwerty1No ratings yet
- Validation of A Tip Feedback Sensor Based Flexible Manipulator ModelDocument12 pagesValidation of A Tip Feedback Sensor Based Flexible Manipulator ModelChristopher MendozaNo ratings yet
- JVE HybridDocument17 pagesJVE HybridatifkhushnoodNo ratings yet
- Ifac08 - Seul - Yu 0457 PDFDocument6 pagesIfac08 - Seul - Yu 0457 PDFЋирка ФејзбуџаркаNo ratings yet
- Torque-Bounded Admittance Control Realized by A Set-Valued Algebraic FeedbackDocument14 pagesTorque-Bounded Admittance Control Realized by A Set-Valued Algebraic FeedbackAl-ShukaNo ratings yet
- Contact Control Concepts in Manipulation Robotics-An: Miomir andDocument13 pagesContact Control Concepts in Manipulation Robotics-An: Miomir andHaider NeamaNo ratings yet
- 22.IJAEST Vol No 7 Issue No 2 Simulation Studies On Dynamic Contact Force Between Mobile Robot Manipulator and Surrounding Environment 305 312Document8 pages22.IJAEST Vol No 7 Issue No 2 Simulation Studies On Dynamic Contact Force Between Mobile Robot Manipulator and Surrounding Environment 305 312helpdesk9532No ratings yet
- Nonlinear Delayed Feedback Control Stabilizes Chaotic Atomic Force Microscope SystemDocument9 pagesNonlinear Delayed Feedback Control Stabilizes Chaotic Atomic Force Microscope SystemFlávia Gonçalves FernandesNo ratings yet
- Adaptive Neurofuzzy Tracking Control of Load Frequency Controller For An Isolated Power System NetworkDocument12 pagesAdaptive Neurofuzzy Tracking Control of Load Frequency Controller For An Isolated Power System NetworkAbba-Gana MohammedNo ratings yet
- RBF BP JieeecDocument5 pagesRBF BP JieeecEyad A. FeilatNo ratings yet
- Analysis of Electromagnetic Characteristics of Asynchronous Induction MachineDocument4 pagesAnalysis of Electromagnetic Characteristics of Asynchronous Induction MachineИгор СтерјовскиNo ratings yet
- Wireless Power Transfer Via Strongly CouDocument5 pagesWireless Power Transfer Via Strongly Couhabiba.afrinNo ratings yet
- RBFNN Trajectory TrackingDocument4 pagesRBFNN Trajectory TrackingUday SinghNo ratings yet
- 5 Ijapbcroct20175Document6 pages5 Ijapbcroct20175TJPRC PublicationsNo ratings yet
- Cartesian Impedance Control of Redundant Robots: Recent Results With The DLR-Light-Weight-ArmsDocument6 pagesCartesian Impedance Control of Redundant Robots: Recent Results With The DLR-Light-Weight-ArmsByron Xavier Lima CedilloNo ratings yet
- Handbook of Electrochemistry G ZoskiDocument7 pagesHandbook of Electrochemistry G Zoskimkahram0% (1)
- Bounded-Impedance Absolute Stability of Bilateral Teleoperation Control Systems-PnqDocument13 pagesBounded-Impedance Absolute Stability of Bilateral Teleoperation Control Systems-PnqArchNo ratings yet
- Difference Equations in Normed Spaces: Stability and OscillationsFrom EverandDifference Equations in Normed Spaces: Stability and OscillationsNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Help - FFT - Functions (MATLAB®)Document4 pagesHelp - FFT - Functions (MATLAB®)Verdi bobNo ratings yet
- Monostori2018 ReferenceWorkEntry Cyber-PhysicalSystemsDocument8 pagesMonostori2018 ReferenceWorkEntry Cyber-PhysicalSystemsVerdi bobNo ratings yet
- Human Arm Joint Stiffness FangDocument9 pagesHuman Arm Joint Stiffness FangVerdi bobNo ratings yet
- IET Electronics Letters TemplateDocument3 pagesIET Electronics Letters TemplateVerdi bobNo ratings yet
- Tutorial 1Document11 pagesTutorial 1Verdi bobNo ratings yet
- Analysis of Mechanism Based On Two Types of Pulse Generators in micro-EDM Using Single Pulse DischargeDocument14 pagesAnalysis of Mechanism Based On Two Types of Pulse Generators in micro-EDM Using Single Pulse DischargeVerdi bobNo ratings yet
- On The Chaotic Nature of Electro-Discharge Machining: Original ArticleDocument12 pagesOn The Chaotic Nature of Electro-Discharge Machining: Original ArticleVerdi bobNo ratings yet
- Computational Modeling of Biological CelDocument144 pagesComputational Modeling of Biological CelVerdi bobNo ratings yet
- Marras 1999Document19 pagesMarras 1999Verdi bobNo ratings yet
- Animal Shelter Manager User Manual: Revision 66 (ASM 2.8.7) June 9, 2011Document98 pagesAnimal Shelter Manager User Manual: Revision 66 (ASM 2.8.7) June 9, 2011Verdi bobNo ratings yet
- Parker 1997Document7 pagesParker 1997Verdi bobNo ratings yet
- Kamat 2017Document13 pagesKamat 2017Verdi bobNo ratings yet
- Mat210 LectureNotes 1Document7 pagesMat210 LectureNotes 1Franch Maverick Arellano LorillaNo ratings yet
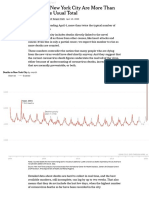
- Deaths in New York City Are More Than Double The Usual TotalDocument3 pagesDeaths in New York City Are More Than Double The Usual TotalRamón RuizNo ratings yet
- String instruction guide for data manipulationDocument11 pagesString instruction guide for data manipulationammerNo ratings yet
- UNIABROAD PitchdeckDocument21 pagesUNIABROAD PitchdeckVikas MurulidharaNo ratings yet
- The Trend Trader Nick Radge On Demand PDFDocument8 pagesThe Trend Trader Nick Radge On Demand PDFDedi Tri LaksonoNo ratings yet
- DiseasesDocument11 pagesDiseasesapi-307430346No ratings yet
- Chords, Arcs, Central and Inscribed AnglesDocument14 pagesChords, Arcs, Central and Inscribed AnglesAlice KrodeNo ratings yet
- ART Threaded Fastener Design and AnalysisDocument40 pagesART Threaded Fastener Design and AnalysisAarón Escorza MistránNo ratings yet
- But Flee Youthful Lusts - pdf2Document2 pagesBut Flee Youthful Lusts - pdf2emmaboakye2fNo ratings yet
- 2006 317Document13 pages2006 317LonginoNo ratings yet
- Cebex 305: Constructive SolutionsDocument4 pagesCebex 305: Constructive SolutionsBalasubramanian AnanthNo ratings yet
- Guru Stotram-1Document5 pagesGuru Stotram-1Green WattNo ratings yet
- 500KVA Rigsafe Framed Generator (8900Kgs)Document1 page500KVA Rigsafe Framed Generator (8900Kgs)Elsad HuseynovNo ratings yet
- Prepare SCI for Service and Merchandising BusinessesDocument8 pagesPrepare SCI for Service and Merchandising BusinessesFunji BuhatNo ratings yet
- Feynman's Hierarchy of ComplexityDocument3 pagesFeynman's Hierarchy of ComplexityjacquesyvescaruanaNo ratings yet
- Music and Yoga Are Complementary To Each OtherDocument9 pagesMusic and Yoga Are Complementary To Each OthersatishNo ratings yet
- Resume Arun.A: Career ObjectiveDocument2 pagesResume Arun.A: Career ObjectiveajithkumarNo ratings yet
- REACH ArticlesDocument12 pagesREACH ArticlesChristian SugasttiNo ratings yet
- Answerkey Precise ListeningDocument26 pagesAnswerkey Precise ListeningAn LeNo ratings yet
- Segmented Income Statements Using Variable CostingDocument34 pagesSegmented Income Statements Using Variable CostingalliahnahNo ratings yet
- Leave Management System: Software Requirements Specification DocumentDocument6 pagesLeave Management System: Software Requirements Specification Documentk767No ratings yet
- UNIT 5 Standard Costing - Variance AnalysisDocument50 pagesUNIT 5 Standard Costing - Variance AnalysisMohsin SheikhNo ratings yet
- Initial 2Document6 pagesInitial 2Asad HoseinyNo ratings yet
- Cement Grouted Rock BoltsDocument28 pagesCement Grouted Rock BoltsBhaskar ReddyNo ratings yet
- Syeda Qirtas Zehra 14948 ObcDocument20 pagesSyeda Qirtas Zehra 14948 ObcSyeda ZehraNo ratings yet
- Julia Kristeva IntroDocument7 pagesJulia Kristeva IntroShweta SoodNo ratings yet
- Alternative Refrigerants Manny A PresentationDocument29 pagesAlternative Refrigerants Manny A PresentationEmmanuel Zr Dela CruzNo ratings yet
- Teacher Thought For InterviewDocument37 pagesTeacher Thought For InterviewMahaprasad JenaNo ratings yet
- Pir Mehr Ali Shah Automata Theory ExamDocument4 pagesPir Mehr Ali Shah Automata Theory ExamIsHa KhAnNo ratings yet