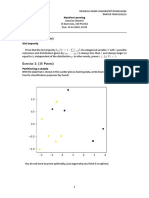
You might also like
- Machine Learning Distributions GuideDocument53 pagesMachine Learning Distributions GuidedummyNo ratings yet
- ML Section08 Linear RegressionDocument30 pagesML Section08 Linear RegressiondummyNo ratings yet
- Multivariate Probability: 1 Discrete Joint DistributionsDocument10 pagesMultivariate Probability: 1 Discrete Joint DistributionshamkarimNo ratings yet
- Prof Stanley Dukin Lectures Statistical MechanicsDocument43 pagesProf Stanley Dukin Lectures Statistical MechanicsEdney GranhenNo ratings yet
- Chapter 02Document50 pagesChapter 02Jack Ignacio NahmíasNo ratings yet
- Lectures 1Document98 pagesLectures 1Shy RonnieNo ratings yet
- Statistical Learning: First Steps: Sasha RakhlinDocument26 pagesStatistical Learning: First Steps: Sasha RakhlinIrfan FadhullahNo ratings yet
- Variational Inference in Graphical Models: December 1, 2020Document77 pagesVariational Inference in Graphical Models: December 1, 2020GeelonSoNo ratings yet
- Assign 1Document5 pagesAssign 1darkmanhiNo ratings yet
- Lect 8Document30 pagesLect 8Kanika ManochaNo ratings yet
- ML Section19 Sampling MCMCDocument61 pagesML Section19 Sampling MCMCdummyNo ratings yet
- Probabilities For Machine Learning: Roland MemisevicDocument19 pagesProbabilities For Machine Learning: Roland MemisevicDenno SteinNo ratings yet
- Data Analysis For Social Scientists (14.1310x)Document12 pagesData Analysis For Social Scientists (14.1310x)SebastianNo ratings yet
- R300 Advanced Econometrics Methods Lecture SlidesDocument362 pagesR300 Advanced Econometrics Methods Lecture SlidesMarco BrolliNo ratings yet
- Probability Density FunctionsDocument8 pagesProbability Density FunctionsThilini NadeeshaNo ratings yet
- A Very Gentle Note On The Construction of DP ZhangDocument15 pagesA Very Gentle Note On The Construction of DP ZhangronalduckNo ratings yet
- Machine Learning - Problem Setup, Conditional Probability, MLEDocument6 pagesMachine Learning - Problem Setup, Conditional Probability, MLEtarun guptaNo ratings yet
- Comp Intel Cheat SheetDocument2 pagesComp Intel Cheat SheetDanielNo ratings yet
- 3.0 2000 Polynomial Interpolation in Several Variables SURVEY 25 YEARS PDFDocument34 pages3.0 2000 Polynomial Interpolation in Several Variables SURVEY 25 YEARS PDFBhim ChaudharyNo ratings yet
- Estimation of Extreme Quantiles From Heavy-Tailed Distributions in A Semi-Parametric Location-Dispersion Regression ModelDocument19 pagesEstimation of Extreme Quantiles From Heavy-Tailed Distributions in A Semi-Parametric Location-Dispersion Regression ModelAboubacrène Ag AhmadNo ratings yet
- Estimation of Extreme Quantiles From Heavy-Tailed Distributions in A Semi-Parametric Location-Dispersion Regression ModelDocument19 pagesEstimation of Extreme Quantiles From Heavy-Tailed Distributions in A Semi-Parametric Location-Dispersion Regression ModelAboubacrène Ag AhmadNo ratings yet
- ColumbiaX Machine Learning Lecture 1 OverviewDocument615 pagesColumbiaX Machine Learning Lecture 1 OverviewAlvaro Jose Rehnfeldt SchmidtNo ratings yet
- Asset-V1 ColumbiaX+CSMM.102x+1T2018+type@asset+block@ML Lecture1Document17 pagesAsset-V1 ColumbiaX+CSMM.102x+1T2018+type@asset+block@ML Lecture1AdiNo ratings yet
- PBM NotesDocument130 pagesPBM NotesSurya IyerNo ratings yet
- CS236 Homework 1Document4 pagesCS236 Homework 1Raffael YasinNo ratings yet
- MLE for Estimating Bernoulli ParametersDocument46 pagesMLE for Estimating Bernoulli ParametersToàn Phạm ĐứcNo ratings yet
- 1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsDocument6 pages1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsJeremy WangNo ratings yet
- Analytic Number Theory in 40 CharactersDocument21 pagesAnalytic Number Theory in 40 CharactersTamás TornyiNo ratings yet
- SAA For JCCDocument18 pagesSAA For JCCShu-Bo YangNo ratings yet
- Variation AlDocument25 pagesVariation AlshomitbNo ratings yet
- Probability For Ai2Document8 pagesProbability For Ai2alphamale173No ratings yet
- Monogamy of Entanglement: IjDocument3 pagesMonogamy of Entanglement: IjDaniel Sebastian PerezNo ratings yet
- Homework 1Document4 pagesHomework 1Bilal Yousaf0% (1)
- Agricultural Land Use in KeralaDocument5 pagesAgricultural Land Use in KeralaavsanthoshNo ratings yet
- Chapter2 ProbabilityDocument45 pagesChapter2 ProbabilitywuziqiNo ratings yet
- 22 MapDocument51 pages22 MapFarid AdilazuardaNo ratings yet
- Lec5 Part1Document42 pagesLec5 Part1fhjhgjhNo ratings yet
- Computational Statistics: Simulation of Probability Distributions: Classical MethodsDocument35 pagesComputational Statistics: Simulation of Probability Distributions: Classical MethodsAchraf K-MoreNo ratings yet
- ACT6100 A2020 Sup 12Document37 pagesACT6100 A2020 Sup 12lebesguesNo ratings yet
- Monte-Carlo Methods for Risk ManagementDocument19 pagesMonte-Carlo Methods for Risk ManagementWazzupWorldNo ratings yet
- Advanced Topics in Learning and VisionDocument26 pagesAdvanced Topics in Learning and VisionHemanth MNo ratings yet
- Lecture 12Document38 pagesLecture 12Võ Minh TríNo ratings yet
- Lec08 LSHDocument7 pagesLec08 LSHjavaNo ratings yet
- Nussbaum 19 I SingDocument13 pagesNussbaum 19 I SingFNNo ratings yet
- Tutorial On Helmholtz MachineDocument26 pagesTutorial On Helmholtz MachineNon SenseNo ratings yet
- MATLAB Program for Calculating Maximum Entropy DistributionsDocument11 pagesMATLAB Program for Calculating Maximum Entropy DistributionsbielailhaNo ratings yet
- 3 Bayesian Deep LearningDocument33 pages3 Bayesian Deep LearningNishanth ManikandanNo ratings yet
- Lec22 PDFDocument8 pagesLec22 PDFjuanagallardo01No ratings yet
- Stanford University CS 229, Autumn 2014 Midterm ExaminationDocument23 pagesStanford University CS 229, Autumn 2014 Midterm ExaminationErico ArchetiNo ratings yet
- CS19M016 PGM Assignment1Document9 pagesCS19M016 PGM Assignment1avinashNo ratings yet
- Ch2 Supervised LearningDocument17 pagesCh2 Supervised LearningRikiNo ratings yet
- StatisticsDiffusionsDocument66 pagesStatisticsDiffusionsGenevieve Magpayo NangitNo ratings yet
- Kragler@hs-Weingarten - De: Operators (MIDO) Which Is Already Well Established For Ordinary DifferentialDocument17 pagesKragler@hs-Weingarten - De: Operators (MIDO) Which Is Already Well Established For Ordinary DifferentialMaria Luisa RomeroNo ratings yet
- Adaptive MCMC For EveryoneDocument13 pagesAdaptive MCMC For EveryoneWu PkNo ratings yet
- CSD311: Artificial IntelligenceDocument33 pagesCSD311: Artificial IntelligenceAyaan KhanNo ratings yet
- Lecture - 02Document36 pagesLecture - 02Abdulla ShaheedNo ratings yet
- Asymptotic Theory and Parametric InferenceDocument32 pagesAsymptotic Theory and Parametric InferenceShah FahadNo ratings yet
- Random Variable & Probability Distribution: Third WeekDocument51 pagesRandom Variable & Probability Distribution: Third WeekBrigitta AngelinaNo ratings yet
- Week 4Document48 pagesWeek 4ammarhakim180600No ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Slides Lecture02Document93 pagesSlides Lecture02dummyNo ratings yet
- Slides Lecture05 NotesDocument32 pagesSlides Lecture05 NotesdummyNo ratings yet
- ML Section19 Sampling MCMCDocument61 pagesML Section19 Sampling MCMCdummyNo ratings yet
- Slides Lecture03Document39 pagesSlides Lecture03dummyNo ratings yet
- Slides Lecture04Document55 pagesSlides Lecture04dummyNo ratings yet
- Blatt 07Document1 pageBlatt 07dummyNo ratings yet
- ML Section15 Neural NetworksDocument133 pagesML Section15 Neural NetworksdummyNo ratings yet
- Machine Learning Section 16: CausalityDocument57 pagesMachine Learning Section 16: CausalitydummyNo ratings yet
- ML 2022 Sheet 10Document1 pageML 2022 Sheet 10dummyNo ratings yet
- Nonlinear Dimensionality Reduction Techniques ComparedDocument46 pagesNonlinear Dimensionality Reduction Techniques CompareddummyNo ratings yet
- Ml2022sheet09 1Document2 pagesMl2022sheet09 1dummyNo ratings yet
- ML 2022 Sheet 03Document1 pageML 2022 Sheet 03dummyNo ratings yet
- ML 2022 Sheet 05Document2 pagesML 2022 Sheet 05dummyNo ratings yet
- ML Exercise Sheet 4Document2 pagesML Exercise Sheet 4dummyNo ratings yet
- ML 2022 Sheet 01Document2 pagesML 2022 Sheet 01dummyNo ratings yet
- ML 2022 Sheet 06Document2 pagesML 2022 Sheet 06dummyNo ratings yet
- ML 2022 Sheet 02Document2 pagesML 2022 Sheet 02dummyNo ratings yet
- Os Ass-1 PDFDocument18 pagesOs Ass-1 PDFDinesh R100% (1)
- Property Law Supp 2016Document6 pagesProperty Law Supp 2016Tefo TshukuduNo ratings yet
- Teach Empathy With LiteratureDocument3 pagesTeach Empathy With LiteratureSantiago Cardenas DiazNo ratings yet
- SCI 7 Q1 WK5 Solutions A LEA TOMASDocument5 pagesSCI 7 Q1 WK5 Solutions A LEA TOMASJoyce CarilloNo ratings yet
- DIK 18A Intan Suhariani 218112100 CJR Research MethodologyDocument9 pagesDIK 18A Intan Suhariani 218112100 CJR Research MethodologyFadli RafiNo ratings yet
- Econometrics IIDocument4 pagesEconometrics IINia Hania SolihatNo ratings yet
- Methodology of Legal Research: Challenges and OpportunitiesDocument8 pagesMethodology of Legal Research: Challenges and OpportunitiesBhan WatiNo ratings yet
- Is BN 9789526041957Document72 pagesIs BN 9789526041957supriya rakshitNo ratings yet
- Quality OrientationDocument2 pagesQuality OrientationResearcherNo ratings yet
- Namatacan HS Report on Regional Diagnostic AssessmentDocument13 pagesNamatacan HS Report on Regional Diagnostic AssessmentDonnabelle MedinaNo ratings yet
- Teaching Speaking: Daily Activities Lesson PlanDocument3 pagesTeaching Speaking: Daily Activities Lesson PlanMARCELANo ratings yet
- Strategic ManagementDocument7 pagesStrategic ManagementSarah ShehataNo ratings yet
- PricelistDocument2,276 pagesPricelistadilcmsNo ratings yet
- Indiana University PressDocument33 pagesIndiana University Pressrenato lopesNo ratings yet
- Review of Train Wheel Fatigue LifeDocument15 pagesReview of Train Wheel Fatigue Lifeabdurhman suleimanNo ratings yet
- Catalan NumbersDocument17 pagesCatalan NumbersVishal GuptaNo ratings yet
- Ch1 - A Perspective On TestingDocument41 pagesCh1 - A Perspective On TestingcnshariffNo ratings yet
- Combination Meter: D1 (A), D2 (B)Document10 pagesCombination Meter: D1 (A), D2 (B)PeterNo ratings yet
- 18.443 MIT Stats CourseDocument139 pages18.443 MIT Stats CourseAditya JainNo ratings yet
- Costallocationvideolectureslides 000XADocument12 pagesCostallocationvideolectureslides 000XAWOw Wong100% (1)
- Rizal's Works Inspire Filipino PrideDocument2 pagesRizal's Works Inspire Filipino PrideItzLian SanchezNo ratings yet
- Full Download Ebook Ebook PDF Oracle 12c SQL 3rd Edition by Joan Casteel PDFDocument41 pagesFull Download Ebook Ebook PDF Oracle 12c SQL 3rd Edition by Joan Casteel PDFdaniel.morones654100% (35)
- Water Supply PDFDocument18 pagesWater Supply PDFtechnicalvijayNo ratings yet
- Sketch 5351a Lo LCD Key Uno 1107Document14 pagesSketch 5351a Lo LCD Key Uno 1107nobcha aNo ratings yet
- Module 1 Power PlantDocument158 pagesModule 1 Power PlantEzhilarasi NagarjanNo ratings yet
- PROPOSED ARFF BUILDINGDocument27 pagesPROPOSED ARFF BUILDINGDale Bryan S DalmacioNo ratings yet
- Articulo SDocument11 pagesArticulo SGABRIELANo ratings yet
- Distributed Oracle EAM - A White PaperDocument38 pagesDistributed Oracle EAM - A White PaperrpgudlaNo ratings yet
- Mil PRF 23699FDocument20 pagesMil PRF 23699FalejandroNo ratings yet
- Physics 8 - EnergyDocument54 pagesPhysics 8 - EnergyHakim AbbasNo ratings yet