You might also like
- Telecom Churn ReportDocument66 pagesTelecom Churn ReportAbhay PoddarNo ratings yet
- Upsell Model Case PDFDocument48 pagesUpsell Model Case PDFNipun GoyalNo ratings yet
- Business Statistics 10th Edition Groebner Solutions ManualDocument24 pagesBusiness Statistics 10th Edition Groebner Solutions ManualMrWayneCollierDVMibep100% (40)
- Engine Control Unit Type ECU 4/G: MTU/DDC Series 4000 Genset ApplicationsDocument62 pagesEngine Control Unit Type ECU 4/G: MTU/DDC Series 4000 Genset ApplicationsGeorge Barsoum100% (3)
- MBA SectionD MBA20235 PranayGupta Assignment RDocument16 pagesMBA SectionD MBA20235 PranayGupta Assignment RSomesh RoyNo ratings yet
- ECOTRICSDocument20 pagesECOTRICSflorenceNo ratings yet
- Codigo Final Histograma y OjivaDocument8 pagesCodigo Final Histograma y OjivaEVELYN DAIANA GALVIS ZARABANDANo ratings yet
- STAT 4540 Homework 1 Solution: 1 ISLR 2.4.1Document6 pagesSTAT 4540 Homework 1 Solution: 1 ISLR 2.4.1Babu ShaikhNo ratings yet
- An20220930 754Document2 pagesAn20220930 754Kingsley IjikeNo ratings yet
- Campus - Recruitment: Library (Knitr) Knitr::opts - Chunk$set (,, True, True, False,, ,, False, False)Document18 pagesCampus - Recruitment: Library (Knitr) Knitr::opts - Chunk$set (,, True, True, False,, ,, False, False)sparkle shresthaNo ratings yet
- Simple Linear regression-LAB4.ipynb - ColaboratoryDocument6 pagesSimple Linear regression-LAB4.ipynb - ColaboratoryPATTABHI RAMANJANEYULUNo ratings yet
- Faseeh Chap 2 ReportDocument30 pagesFaseeh Chap 2 ReportSameer YounasNo ratings yet
- 26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienDocument18 pages26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienPhạm Minh ChâuNo ratings yet
- ML0101EN Clas Logistic Reg Churn Py v1Document13 pagesML0101EN Clas Logistic Reg Churn Py v1banicx100% (1)
- Predicting The Churn in Telecom IndustryDocument23 pagesPredicting The Churn in Telecom Industryashish841No ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Big Data Machine LearningDocument6 pagesBig Data Machine LearningRandy MarmerNo ratings yet
- Association Rules:: Books Data SetDocument23 pagesAssociation Rules:: Books Data Setnehal gundrapallyNo ratings yet
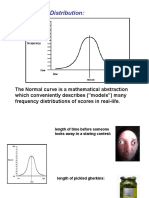
- Normal Distribution 2012Document29 pagesNormal Distribution 2012kya karegaNo ratings yet
- En Tanagra Kohonen SOM RDocument21 pagesEn Tanagra Kohonen SOM RVbg DaNo ratings yet
- Applied Exercise 5Document5 pagesApplied Exercise 5Xuanli XiongNo ratings yet
- Income Qualification Project3Document40 pagesIncome Qualification Project3NikhilNo ratings yet
- LightGBM - An In-Depth Guide PythonDocument26 pagesLightGBM - An In-Depth Guide PythonRadha KilariNo ratings yet
- Topic: Text Messaging And/or Instant Messaging Is Time-Consuming Topic Description: Text Messaging Is About Twenty-Seven Years Old (Eveleth), AndDocument14 pagesTopic: Text Messaging And/or Instant Messaging Is Time-Consuming Topic Description: Text Messaging Is About Twenty-Seven Years Old (Eveleth), AndAdroit WriterNo ratings yet
- Loading The Dataset: Import As Import As Import As Import As From Import From Import From Import From Import From ImportDocument3 pagesLoading The Dataset: Import As Import As Import As Import As From Import From Import From Import From Import From ImportDivyani ChavanNo ratings yet
- CatBoost - An In-Depth Guide PythonDocument33 pagesCatBoost - An In-Depth Guide PythonRadha KilariNo ratings yet
- Business Analytics Assignment-2 Core 5 Group 3: International School of Business & MediaDocument12 pagesBusiness Analytics Assignment-2 Core 5 Group 3: International School of Business & MediaPGDM 19 BASSAM IQRAM QURESHINo ratings yet
- Country Year Sex Age Suicides - No Population: Finding Missing ValuesDocument11 pagesCountry Year Sex Age Suicides - No Population: Finding Missing ValuesHarish Kumar PamnaniNo ratings yet
- Decision TreeDocument12 pagesDecision TreeKagade AjinkyaNo ratings yet
- K Nearest NeighboursDocument4 pagesK Nearest Neighboursbunsglazing135No ratings yet
- Pregunta1 - Pablo David - Jupyter NotebookDocument14 pagesPregunta1 - Pablo David - Jupyter NotebookDavid Albres PabloNo ratings yet
- Pendapatan Harga TahuDocument17 pagesPendapatan Harga TahuDzik KovvNo ratings yet
- Jeffrey Williams (20221013) 4Document27 pagesJeffrey Williams (20221013) 4JEFFREY WILLIAMS P M 20221013No ratings yet
- Breast Cancer DatasetDocument154 pagesBreast Cancer DatasetIris RumiNo ratings yet
- Eco 570 AssignDocument10 pagesEco 570 AssignMaryam KhanNo ratings yet
- Fashion MNIST-6Document10 pagesFashion MNIST-6akif barbaros dikmenNo ratings yet
- Exam 1Document6 pagesExam 1Danien LopesNo ratings yet
- Instructions:: Mltest2question - Jupyter NotebookDocument6 pagesInstructions:: Mltest2question - Jupyter NotebookAniruddha TrivediNo ratings yet
- Logistic Regression 205Document8 pagesLogistic Regression 205Ranadeep DeyNo ratings yet
- Let LetDocument29 pagesLet LetIsaac Daplas RosarioNo ratings yet
- Normal Distribution 2012Document29 pagesNormal Distribution 2012Isaac Daplas RosarioNo ratings yet
- Talidano Mark Vincent M Final Exam in Educ 404 1Document13 pagesTalidano Mark Vincent M Final Exam in Educ 404 1Jahazelle PoloNo ratings yet
- SVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceDocument28 pagesSVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceZuzana W100% (1)
- Arules - Association Rule Mining With R - A TutorialDocument82 pagesArules - Association Rule Mining With R - A TutorialRANIA_MKHININI_GAHARNo ratings yet
- Stat 6430 Quiz 4 PDFDocument15 pagesStat 6430 Quiz 4 PDFDouglas FraserNo ratings yet
- FDS Solved SlipsDocument63 pagesFDS Solved Slipsyashm4071100% (1)
- Logistic Regression For Binary Classification With Core APIs - TensorFlow CoreDocument22 pagesLogistic Regression For Binary Classification With Core APIs - TensorFlow Corezwd.slmnNo ratings yet
- Oup 9Document26 pagesOup 9TAMIZHAN ANo ratings yet
- Assignment 11Document7 pagesAssignment 11ankit mahto100% (1)
- Support Vector Machine (SVM) - BioinformaticsDocument10 pagesSupport Vector Machine (SVM) - BioinformaticsalihamzakrbgNo ratings yet
- Churn Prediction ModelDocument36 pagesChurn Prediction ModelkarthikeyanNo ratings yet
- Practical - 5 - 52Document4 pagesPractical - 5 - 52Royal EmpireNo ratings yet
- Exploratory Data Analysis On Mutual Funds Dataset 1707637258Document21 pagesExploratory Data Analysis On Mutual Funds Dataset 1707637258akashabimanuNo ratings yet
- S Pss by Sajid AlikhanDocument83 pagesS Pss by Sajid AlikhanArsalan TNo ratings yet
- Loadalgarve MLPDocument7 pagesLoadalgarve MLPRony RockNo ratings yet
- Rajat Kapoor Assignment No. 5 8102Document7 pagesRajat Kapoor Assignment No. 5 8102kapoorrajat859500No ratings yet
- Linear RegressionDocument10 pagesLinear RegressionWONDYE DESTANo ratings yet
- Joshua PDFDocument11 pagesJoshua PDFKavi SekarNo ratings yet
- Supervised Learning With Scikit-Learn: Preprocessing DataDocument32 pagesSupervised Learning With Scikit-Learn: Preprocessing DataNourheneMbarekNo ratings yet
- A1Document8 pagesA1DASHPAGALNo ratings yet
- CMM Cable ManualDocument69 pagesCMM Cable ManualCDELVO1382No ratings yet
- OutputDocument9 pagesOutputnenucheppanu2No ratings yet
- Elb AgDocument117 pagesElb AgniravNo ratings yet
- Case Study Problem StatementDocument2 pagesCase Study Problem StatementSahil GargNo ratings yet
- Icom F-121Document36 pagesIcom F-121Sylma Costarelli MartinNo ratings yet
- Journal of Business Research: Enrico Battisti, Simona Alfiero, Erasmia LeonidouDocument13 pagesJournal of Business Research: Enrico Battisti, Simona Alfiero, Erasmia LeonidoualwiNo ratings yet
- HeliTrim Manual en PDFDocument9 pagesHeliTrim Manual en PDFJuan Pablo100% (1)
- MATLAB and Simulink: Prof. Dr. Ottmar BeucherDocument71 pagesMATLAB and Simulink: Prof. Dr. Ottmar BeucherShubham ChauhanNo ratings yet
- Theories and Principles of Public Administration-Module-IVDocument12 pagesTheories and Principles of Public Administration-Module-IVAnagha AnuNo ratings yet
- DigiTech GNX 2 Service ManualDocument12 pagesDigiTech GNX 2 Service ManualTOTOK ZULIANTONo ratings yet
- SAC Training 01Document11 pagesSAC Training 01Harshal RathodNo ratings yet
- Republic of The Philippines Sangguniang Panlungsod City of Baguio SOFAD SESSION, 09 OCTOBER 2017, 2:00 P.M. Session Nr. 1Document3 pagesRepublic of The Philippines Sangguniang Panlungsod City of Baguio SOFAD SESSION, 09 OCTOBER 2017, 2:00 P.M. Session Nr. 1rainNo ratings yet
- Operating SystemsDocument18 pagesOperating SystemsMr. Rahul Kumar VermaNo ratings yet
- Girbau, S.A.: STI-54 / STI-77 Parts ManualDocument72 pagesGirbau, S.A.: STI-54 / STI-77 Parts ManualoozbejNo ratings yet
- Introduction To Non Parametric Statistical Methods Research GateDocument46 pagesIntroduction To Non Parametric Statistical Methods Research GateAaron FuchsNo ratings yet
- DSC-33C DSTC-40GDocument1 pageDSC-33C DSTC-40GsathishNo ratings yet
- St. Therese School Second Periodic Test Mapeh 2Document4 pagesSt. Therese School Second Periodic Test Mapeh 2dona manuela elementary schoolNo ratings yet
- A Complete Guide To Alpha OnlineDocument13 pagesA Complete Guide To Alpha OnlinejoaovictorrmcNo ratings yet
- Liquid Crystal Display Module MODEL: NMTG-S12232CFYHSGY-10 Customer's No.Document21 pagesLiquid Crystal Display Module MODEL: NMTG-S12232CFYHSGY-10 Customer's No.Игорь НесвитNo ratings yet
- Accounts Payable (J60) - Process DiagramsDocument16 pagesAccounts Payable (J60) - Process Diagramsgobasha100% (1)
- Fuzzy SetsDocument3 pagesFuzzy SetsShugal On HaiNo ratings yet
- IELTS Technology VocabularyDocument4 pagesIELTS Technology Vocabularymanju sisodiyaNo ratings yet
- Effect of Mobile Marketing On YoungstersDocument33 pagesEffect of Mobile Marketing On Youngsterssaloni singhNo ratings yet
- Battery Reliability Test System MODEL 17010Document12 pagesBattery Reliability Test System MODEL 17010G H.No ratings yet
- Cyber ArkDocument2 pagesCyber ArkHendra SoenderskovNo ratings yet
- Verafin CaseDocument3 pagesVerafin CaseMargaret Tariro MunemwaNo ratings yet
- Flutter Cheat Sheet: by ViaDocument1 pageFlutter Cheat Sheet: by ViaMichael Paul SebandoNo ratings yet
- R-PLS Path Modeling ExampleDocument8 pagesR-PLS Path Modeling ExamplemagargieNo ratings yet