You might also like
- Ian Stewart, David Tall - Complex Analysis-Cambridge University Press (2018) PDFDocument404 pagesIan Stewart, David Tall - Complex Analysis-Cambridge University Press (2018) PDFE R100% (4)
- Intro Stats 5th Edition by Richard D de Veaux Ebook PDFDocument42 pagesIntro Stats 5th Edition by Richard D de Veaux Ebook PDFdelmar.jackson88497% (36)
- Graph Theory and Its Applications To Problems of Society PDFDocument132 pagesGraph Theory and Its Applications To Problems of Society PDFTeddy112100% (1)
- Simple Quiz App Using PythonDocument47 pagesSimple Quiz App Using Pythonatozdhiyanes100% (1)
- LG 23MT77V LW50A Schematic Diagram and Service ManualDocument34 pagesLG 23MT77V LW50A Schematic Diagram and Service Manualaze1959No ratings yet
- Excel NotesDocument9 pagesExcel NotesAhnNo ratings yet
- Sakchi Saraf Project 5Document25 pagesSakchi Saraf Project 5Sakchi SarafNo ratings yet
- Stability Analysis of Continous-Time Recurrent Neural NetworksDocument11 pagesStability Analysis of Continous-Time Recurrent Neural NetworksAnonymous kK5O7WFZ5No ratings yet
- Differential Expression of Rna-Seq Data at The Gene Level - The Deseq PackageDocument24 pagesDifferential Expression of Rna-Seq Data at The Gene Level - The Deseq PackageVijay SansanwalNo ratings yet
- Abs & Contents ListDocument3 pagesAbs & Contents ListPaul WalkerNo ratings yet
- Real Estate Web Application Using FlaskDocument11 pagesReal Estate Web Application Using FlaskdataprodcsNo ratings yet
- Prediction of Copd Using Machine Learning TechniqueDocument11 pagesPrediction of Copd Using Machine Learning TechniquedataprodcsNo ratings yet
- Spectrum Sensing in Cognitive Radio Networks: by Waleed Ejaz 2006-Nust-Ms Phd-Come-01Document85 pagesSpectrum Sensing in Cognitive Radio Networks: by Waleed Ejaz 2006-Nust-Ms Phd-Come-01Prasanna Kumar KottakotaNo ratings yet
- Harvard Math 25b 2018spDocument115 pagesHarvard Math 25b 2018spk2444633No ratings yet
- KB Raborife Stability of de Assignment 10Document25 pagesKB Raborife Stability of de Assignment 10Kagi RaborifeNo ratings yet
- Amber ToolsDocument350 pagesAmber Toolslaksh688No ratings yet
- TemplatesDocument117 pagesTemplatesInderpreet SinghNo ratings yet
- Entropy and Efficiency of The ETF MarketDocument31 pagesEntropy and Efficiency of The ETF MarkettrolllolfuckubitchNo ratings yet
- What Drives Option PricesDocument23 pagesWhat Drives Option PricesNikhil AroraNo ratings yet
- Tess Version 2.3 - Reference Manual August 2009: Eric Durand Chibiao Chen Olivier FrançoisDocument30 pagesTess Version 2.3 - Reference Manual August 2009: Eric Durand Chibiao Chen Olivier FrançoisCarlos PaganiNo ratings yet
- Verification of Systems and Circuits Using LOTOS, Petri Nets, and CCSFrom EverandVerification of Systems and Circuits Using LOTOS, Petri Nets, and CCSNo ratings yet
- PresDocument6 pagesPresThe TruthNo ratings yet
- Novel Learning Deep Q Network For Dense Traffic ControlDocument11 pagesNovel Learning Deep Q Network For Dense Traffic ControldataprodcsNo ratings yet
- AADS Exam Note 2022Document12 pagesAADS Exam Note 2022曹德欢No ratings yet
- How Many Clusters? Which Clustering Method? Answers Via Model-Based Cluster AnalysisDocument22 pagesHow Many Clusters? Which Clustering Method? Answers Via Model-Based Cluster AnalysisFake nameNo ratings yet
- Using Genetic Algorithms To Evolve Artificial Neural NetworksDocument24 pagesUsing Genetic Algorithms To Evolve Artificial Neural NetworkskamutmazNo ratings yet
- Applied AI - Machine Learning Course Syllabus PDFDocument22 pagesApplied AI - Machine Learning Course Syllabus PDFAkash Raghavendra Kathavate Dept of TENo ratings yet
- AADS Exam Note 2022Document12 pagesAADS Exam Note 2022曹德欢No ratings yet
- Tellicorp An Ensemble Model To Predict Crop Using Machine Learning AlgorithmsDocument11 pagesTellicorp An Ensemble Model To Predict Crop Using Machine Learning AlgorithmsdataprodcsNo ratings yet
- Dot 62941 DS1Document122 pagesDot 62941 DS1civil sohiNo ratings yet
- Fake News Detection Using Machine LearningDocument11 pagesFake News Detection Using Machine LearningVj KumarNo ratings yet
- Prediction Stock Price Using Data Science TechniqueDocument11 pagesPrediction Stock Price Using Data Science TechniquedataprodcsNo ratings yet
- Gosser D. R For Quantitative Chemistry 2023Document119 pagesGosser D. R For Quantitative Chemistry 2023jobpei2No ratings yet
- AADS Exam Note 2022Document12 pagesAADS Exam Note 2022曹德欢No ratings yet
- Original PDF Intro Stats 5th Edition by RichardDocument61 pagesOriginal PDF Intro Stats 5th Edition by Richardcarla.campbell348100% (41)
- UCTE System Adequacy MethodologyDocument29 pagesUCTE System Adequacy Methodologycamille.vanhoenackerNo ratings yet
- Designinglogicsystemsusingstatemachines Text PDFDocument121 pagesDesigninglogicsystemsusingstatemachines Text PDFarielguerreroNo ratings yet
- ReportDocument42 pagesReportjadhavvikram863No ratings yet
- Sat - 7.Pdf - Predicting Student's Performance Based On Machine LearningDocument11 pagesSat - 7.Pdf - Predicting Student's Performance Based On Machine LearningVj KumarNo ratings yet
- Date: 17 November 2021: Great Learning Authored By: ANIMESH HALDERDocument27 pagesDate: 17 November 2021: Great Learning Authored By: ANIMESH HALDERanimehNo ratings yet
- Semiparametric RegressionDocument22 pagesSemiparametric Regressionshamz17No ratings yet
- Reshma Project ReportDocument47 pagesReshma Project ReportV MERIN SHOBINo ratings yet
- Gs Short Ex 04feb2015Document100 pagesGs Short Ex 04feb2015juan camiloNo ratings yet
- ECS 315: Probability and Random Processes: September 2010Document54 pagesECS 315: Probability and Random Processes: September 2010Anonymous Nw6c3H0No ratings yet
- Ad 1194755Document56 pagesAd 1194755alialiklmo9No ratings yet
- 1201428-000-ZKS-0011-r-Delft Dashboard - Final PDFDocument74 pages1201428-000-ZKS-0011-r-Delft Dashboard - Final PDFYuwana SetiabudiNo ratings yet
- Investigation of The Effect of Using Stochastic and Local Volatility When Pricing Barrier OptionsDocument56 pagesInvestigation of The Effect of Using Stochastic and Local Volatility When Pricing Barrier Optionsnexxus hcNo ratings yet
- Speech Emotion Detection Using Machine LearningDocument11 pagesSpeech Emotion Detection Using Machine LearningdataprodcsNo ratings yet
- A Minimal Introduction To Geostatistics With R/gstat: //WWW - Itc.nl/personal/rossiterDocument69 pagesA Minimal Introduction To Geostatistics With R/gstat: //WWW - Itc.nl/personal/rossiterΣοφία Α.No ratings yet
- 1.probability Random Variables and Stochastic Processes Athanasios Papoulis S. Unnikrishna Pillai 1 300 1 30Document30 pages1.probability Random Variables and Stochastic Processes Athanasios Papoulis S. Unnikrishna Pillai 1 300 1 30AlvaroNo ratings yet
- 4 5958578051531934422Document297 pages4 5958578051531934422Shakeel AminNo ratings yet
- Effective Heart Disease Prediction Using Data Mining TechniqueDocument11 pagesEffective Heart Disease Prediction Using Data Mining TechniqueVj KumarNo ratings yet
- Data MiningDocument40 pagesData MiningnamtaNo ratings yet
- MTH3901 Mini Project Report 2021Document83 pagesMTH3901 Mini Project Report 2021Nur Ain Syamira RazmiNo ratings yet
- Pmap Manual 2Document34 pagesPmap Manual 2salihguvensoy1No ratings yet
- Reporte Etabs CafDocument61 pagesReporte Etabs Cafamaury2223No ratings yet
- 22p3916 Sampling Design Guidelines Part2Document75 pages22p3916 Sampling Design Guidelines Part2Oscar GomezNo ratings yet
- Monotonicty Diamond and DDFV Type Finite Volume Schemes For 2D Elliptic ProblemsDocument39 pagesMonotonicty Diamond and DDFV Type Finite Volume Schemes For 2D Elliptic ProblemsmedNo ratings yet
- Khatibzadeh Amir AliDocument114 pagesKhatibzadeh Amir AliDai LewisNo ratings yet
- Eco No MetricsDocument312 pagesEco No MetricshalhoshanNo ratings yet
- Predictor Effects Graphics GalleryDocument44 pagesPredictor Effects Graphics GalleryAriake SwyceNo ratings yet
- Sanam MathDocument13 pagesSanam MathAbrar Ahmed KhanNo ratings yet
- SD) Relay Settings CalculationsDocument8 pagesSD) Relay Settings CalculationsElectrical RadicalNo ratings yet
- Level Wound Copper TubeDocument1 pageLevel Wound Copper TubeAamer Abdul MajeedNo ratings yet
- PD2083-EL-HAZ-A1-004.pdf HAZARDOUS AREA CLASSIFICATION SV STATION-3Document1 pagePD2083-EL-HAZ-A1-004.pdf HAZARDOUS AREA CLASSIFICATION SV STATION-3Alla Naveen KumarNo ratings yet
- Two Day Workshop On: Embedded Systems Design Using ARDUINO BoardsDocument2 pagesTwo Day Workshop On: Embedded Systems Design Using ARDUINO BoardsBritto Ebrington AjayNo ratings yet
- 777D.Schematic ElectricDocument2 pages777D.Schematic ElectricDedeNo ratings yet
- 1.4435 - C Stainless Steel DetailsDocument3 pages1.4435 - C Stainless Steel DetailsmeenakshiNo ratings yet
- Entrepreneurial Skills-II: in This Chapter..Document34 pagesEntrepreneurial Skills-II: in This Chapter..TECH-A -TRONICSNo ratings yet
- 2190 9172 9172A Inst InstrDocument4 pages2190 9172 9172A Inst InstrDushantha RoshanNo ratings yet
- Cie-III Verilog HDL QPDocument2 pagesCie-III Verilog HDL QPvijayarani.katkamNo ratings yet
- Cryptocurrency System Using Body Activity Data Wo2020060606 2 of 6Document1 pageCryptocurrency System Using Body Activity Data Wo2020060606 2 of 6Nemo NemoNo ratings yet
- Solaris 10 Installation Guide: Basic InstallationsDocument58 pagesSolaris 10 Installation Guide: Basic InstallationsHakim HamzaouiNo ratings yet
- Comprehensive Comparison of 99 Efficient Totem-Pole PFC With Fixed PWM or Variable TCM Switching FrequencyDocument8 pagesComprehensive Comparison of 99 Efficient Totem-Pole PFC With Fixed PWM or Variable TCM Switching FrequencyMuhammad Arsalan FarooqNo ratings yet
- Penawaran Harga ACCOR Vacation Club-1Document4 pagesPenawaran Harga ACCOR Vacation Club-1Sedana HartaNo ratings yet
- Anil Laul BharaniDocument30 pagesAnil Laul BharaniBharani MadamanchiNo ratings yet
- Infografia Línea Del Tiempo Historia de La Computadoras en InglesDocument1 pageInfografia Línea Del Tiempo Historia de La Computadoras en InglesGEORGEGAMER MCNo ratings yet
- Seminar Topic On Compuetr ForensicsDocument11 pagesSeminar Topic On Compuetr ForensicsS17IT1207Hindu Madhavi100% (1)
- UST - A1100 Guardian Overfill Prevention ValveDocument1 pageUST - A1100 Guardian Overfill Prevention ValvelauraNo ratings yet
- Education: Palamala Venkata Sai GireeshDocument2 pagesEducation: Palamala Venkata Sai Gireeshvenkata sai gireesh pNo ratings yet
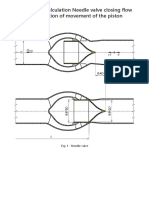
- Hydrodynamic Calculation Needle Valve Closing Flow Against The Direction of Movement of The PistonDocument23 pagesHydrodynamic Calculation Needle Valve Closing Flow Against The Direction of Movement of The Pistonmet-calcNo ratings yet
- An Inflection Point For The Data-Driven Enterprise: Pulse SurveyDocument20 pagesAn Inflection Point For The Data-Driven Enterprise: Pulse SurveyAndy BaneNo ratings yet
- ISO Accredited Training and Certification: VCAT I - Vibration AnalysisDocument3 pagesISO Accredited Training and Certification: VCAT I - Vibration AnalysisPraveenNo ratings yet
- QuestionPaper TemplateDocument2 pagesQuestionPaper Templatesurender.ascentNo ratings yet
- Advance Adgressor 3220D Parts ManualDocument52 pagesAdvance Adgressor 3220D Parts Manualerik49No ratings yet
- Atc Investor Relations U.S. Technology and 5g Update q4 2020Document35 pagesAtc Investor Relations U.S. Technology and 5g Update q4 2020Valtteri ItärantaNo ratings yet
- New Gen Trunnion Soft Seat Ball ValveDocument7 pagesNew Gen Trunnion Soft Seat Ball ValvedirtylsuNo ratings yet
- Linear Algebra 2: Final Test Exam (Sample) : T: V V A Linear TransformationDocument3 pagesLinear Algebra 2: Final Test Exam (Sample) : T: V V A Linear TransformationDavidNo ratings yet