You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- String Matching 2019Document50 pagesString Matching 2019yetsedawNo ratings yet
- MybestDocument9 pagesMybestyetsedawNo ratings yet
- Sentiment Analysis of Tweets Using Natural Language Processing (#1130188) - 2484168Document3 pagesSentiment Analysis of Tweets Using Natural Language Processing (#1130188) - 2484168yetsedawNo ratings yet
- Iijcs 2018 02 08 11Document11 pagesIijcs 2018 02 08 11yetsedawNo ratings yet
- Related WorkDocument24 pagesRelated WorkyetsedawNo ratings yet
- CD7687Document24 pagesCD7687yetsedawNo ratings yet
- Shsconf Stehf2022 03018Document6 pagesShsconf Stehf2022 03018yetsedawNo ratings yet
- Levenshtein Algorithm 1 PDFDocument10 pagesLevenshtein Algorithm 1 PDFyetsedawNo ratings yet
- Defini'on of Minimum Edit DistanceDocument52 pagesDefini'on of Minimum Edit DistanceyetsedawNo ratings yet
- Dynamic Programming: Longest Common SubsequencesDocument11 pagesDynamic Programming: Longest Common SubsequencesyetsedawNo ratings yet
- Lecture 12Document13 pagesLecture 12yetsedawNo ratings yet
- Ijiset V2 I1 50Document6 pagesIjiset V2 I1 50yetsedawNo ratings yet
- String Matching Algorithms and Their Applicability in Various ApplicationsDocument5 pagesString Matching Algorithms and Their Applicability in Various ApplicationsyetsedawNo ratings yet
- TwiterDocument9 pagesTwiteryetsedawNo ratings yet
- Research Article: Subha R., Anandakumar K and Bharathi ADocument7 pagesResearch Article: Subha R., Anandakumar K and Bharathi AyetsedawNo ratings yet
- Performance Evaluation of Weighted Greedy Algorithm in Resource MDocument73 pagesPerformance Evaluation of Weighted Greedy Algorithm in Resource MyetsedawNo ratings yet
- An Approximate String-Matching Algorithm: Jong Yong Kim and John Shawe-Taylor QFDocument11 pagesAn Approximate String-Matching Algorithm: Jong Yong Kim and John Shawe-Taylor QFyetsedawNo ratings yet
- D4.2 (Modified)Document39 pagesD4.2 (Modified)yetsedawNo ratings yet
- A Comparative Study On String Matching Algorithms of Biological SequencesDocument5 pagesA Comparative Study On String Matching Algorithms of Biological SequencesyetsedawNo ratings yet
- Lec4 2 4Document6 pagesLec4 2 4yetsedawNo ratings yet
- Github Copilot Ai Pair Programmer: Asset or Liability?Document20 pagesGithub Copilot Ai Pair Programmer: Asset or Liability?yetsedawNo ratings yet
- A Modified Activity Selection Algorithm With New Parameter: Minimum MakespanDocument4 pagesA Modified Activity Selection Algorithm With New Parameter: Minimum MakespanyetsedawNo ratings yet
- Acstv10n8 43Document14 pagesAcstv10n8 43yetsedawNo ratings yet
- On-Line Approximate String Searching Algorithms: Survey and Experimental ResultsDocument22 pagesOn-Line Approximate String Searching Algorithms: Survey and Experimental ResultsyetsedawNo ratings yet
- Erd TicketsDocument1 pageErd TicketsyetsedawNo ratings yet
- Assignment 2Document3 pagesAssignment 2yetsedawNo ratings yet
- Lec 676Document8 pagesLec 676Saad Ather MSDS 2021No ratings yet
- SE ExamDocument5 pagesSE ExamyetsedawNo ratings yet
- Arise Bostnar StudyDocument19 pagesArise Bostnar StudyyetsedawNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
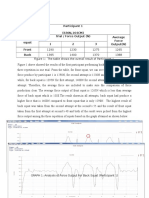
- Result: Participant 1 (630N, 164CM) Type of Squat Trial / Force Output (N) Average Force Output (N) 1 2 3 Front BackDocument5 pagesResult: Participant 1 (630N, 164CM) Type of Squat Trial / Force Output (N) Average Force Output (N) 1 2 3 Front BackpatenggNo ratings yet
- Challenges For Control Research CompilationDocument76 pagesChallenges For Control Research CompilationAlexander Losada AlmonacidNo ratings yet
- Kalaha in Java - An Experiment in Artificial Intelligence and NetworkingDocument102 pagesKalaha in Java - An Experiment in Artificial Intelligence and NetworkingapNo ratings yet
- Flow Diagram, Equipment and Tag IdentificationDocument24 pagesFlow Diagram, Equipment and Tag Identificationmkpq100% (1)
- Application Note For Customized CellsDocument13 pagesApplication Note For Customized Cellsxian liuNo ratings yet
- Analog Vs DigitalDocument6 pagesAnalog Vs DigitalMohan AwasthyNo ratings yet
- Kinematic of MechanismDocument12 pagesKinematic of MechanismFennyFebrinaNurlitaSariNo ratings yet
- Hybrid Audio Amplifier: The Best of Both Worlds?Document9 pagesHybrid Audio Amplifier: The Best of Both Worlds?Yeison MedranoNo ratings yet
- BIT Baroda Institute of Technology: Creo (Pro/ENGINEER) Training atDocument4 pagesBIT Baroda Institute of Technology: Creo (Pro/ENGINEER) Training atNIRALINo ratings yet
- ArchModels Volume - 126 PDFDocument40 pagesArchModels Volume - 126 PDFgombestralalaNo ratings yet
- Innermost - Main CatalogueDocument214 pagesInnermost - Main CatalogueLiteHouseNo ratings yet
- Grammar Skills QuestionnaireDocument4 pagesGrammar Skills QuestionnaireemanNo ratings yet
- INTRO TO ECE - HW Assignment 2:, I, I, I V, V, V, V, P P PDocument8 pagesINTRO TO ECE - HW Assignment 2:, I, I, I V, V, V, V, P P PVienNgocQuangNo ratings yet
- Series: Instruction Manual Digital TheodoliteDocument64 pagesSeries: Instruction Manual Digital TheodoliteJhon Smit Gonzales UscataNo ratings yet
- Psd4135G2: Flash In-System-Programmable Peripherals For 16-Bit McusDocument94 pagesPsd4135G2: Flash In-System-Programmable Peripherals For 16-Bit McusSiva Manohar ReddyNo ratings yet
- The Essential Building Blocks of E2E Network SlicingDocument11 pagesThe Essential Building Blocks of E2E Network Slicingyadav_dheeraj19815No ratings yet
- Discussion Sa QualiDocument2 pagesDiscussion Sa QualiAngel Rose SalinasalNo ratings yet
- DOP-C02demo Exam Practice QuestionsDocument7 pagesDOP-C02demo Exam Practice Questionslovegeorge393No ratings yet
- Aerodynamics Lab 3 - Direct Measurements of Airfoil Lift and DragDocument18 pagesAerodynamics Lab 3 - Direct Measurements of Airfoil Lift and DragDavid Clark83% (12)
- Nat Reviewer Set B - Math 10Document2 pagesNat Reviewer Set B - Math 10Jo Mai Hann90% (10)
- IV Computation Formulas and ExamplesDocument11 pagesIV Computation Formulas and ExamplesSheniel VariacionNo ratings yet
- Analysis of Elevated Square Water Tank With Different Staging SystemDocument4 pagesAnalysis of Elevated Square Water Tank With Different Staging SystemInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Unit 3 Tree StructureDocument19 pagesUnit 3 Tree StructureNida AhmedNo ratings yet
- DM200094_Marts 3000_DK400041_ENDocument28 pagesDM200094_Marts 3000_DK400041_ENipasrl.guestNo ratings yet
- Mca 5th Sem AssignDocument16 pagesMca 5th Sem AssignVikas GuptaNo ratings yet
- Active Heave Drilling Drawworks Improve Rig EfficiencyDocument5 pagesActive Heave Drilling Drawworks Improve Rig Efficiencygplese0No ratings yet
- Physics ART INTEGRATED PROJECTDocument24 pagesPhysics ART INTEGRATED PROJECTPRATHAM BANSAL67% (3)
- Actizal Energy Audit Trials Report SummaryDocument28 pagesActizal Energy Audit Trials Report SummaryDSGNo ratings yet
- Strcteng200 S1 2021Document11 pagesStrcteng200 S1 2021ChengNo ratings yet
- 11 17 2014 Differential CalculusDocument1 page11 17 2014 Differential CalculusEj ApeloNo ratings yet