You might also like
- Exp 6Document6 pagesExp 6jayNo ratings yet
- K-Nearest Neighbor On Python Ken OcumaDocument9 pagesK-Nearest Neighbor On Python Ken OcumaAliyha Dionio100% (2)
- Implementing Custom RandomSearchCV for Hyperparameter TuningDocument1 pageImplementing Custom RandomSearchCV for Hyperparameter TuningTayub khan.ANo ratings yet
- EXP 08 (ML) - ShriDocument2 pagesEXP 08 (ML) - ShriDSE 04. Chetana BhoirNo ratings yet
- Practical File of Machine Learning 1905388Document42 pagesPractical File of Machine Learning 1905388DevanshNo ratings yet
- 20MIS1025 - DecisionTree - Ipynb - ColaboratoryDocument4 pages20MIS1025 - DecisionTree - Ipynb - ColaboratorySandip DasNo ratings yet
- ML Lab ProgramsDocument23 pagesML Lab ProgramsRoopa 18-19-36No ratings yet
- Is Lab 7Document7 pagesIs Lab 7Aman BansalNo ratings yet
- Is Lab 7Document7 pagesIs Lab 7Aman BansalNo ratings yet
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- Machine LearninDocument23 pagesMachine LearninManoj Kumar 1183100% (1)
- SVM K NN MLP With Sklearn Jupyter NoteBoDocument22 pagesSVM K NN MLP With Sklearn Jupyter NoteBoAhm TharwatNo ratings yet
- ML IPN - Hands-on digit recognitionDocument14 pagesML IPN - Hands-on digit recognitionfuck off we need limitsNo ratings yet
- PCA Guide: When, Why, How and Feature ImportanceDocument9 pagesPCA Guide: When, Why, How and Feature ImportanceRaj kumarNo ratings yet
- Handwritten Character Recognition with Neural NetworksDocument12 pagesHandwritten Character Recognition with Neural Networksshreyash sononeNo ratings yet
- ML LabDocument7 pagesML LabRishi TPNo ratings yet
- Logistic Regression in 40 CharactersDocument7 pagesLogistic Regression in 40 CharactersadalinaNo ratings yet
- Linear & Polynomial Regression of X-Ray DatasetDocument4 pagesLinear & Polynomial Regression of X-Ray DatasetWahib NakhoulNo ratings yet
- Machine Learning LAB: Practical-1Document24 pagesMachine Learning LAB: Practical-1Tsering Jhakree100% (1)
- Machine Learning With SQLDocument12 pagesMachine Learning With SQLprince krish100% (1)
- Az Her and TahirDocument2 pagesAz Her and Tahirsyedosmanali040No ratings yet
- PML Ex3 FinalDocument20 pagesPML Ex3 FinalJasmitha BNo ratings yet
- Machine Learning Hands-OnDocument18 pagesMachine Learning Hands-OnVivek JD100% (1)
- Lecture 21Document138 pagesLecture 21Tev WallaceNo ratings yet
- NumpyDocument50 pagesNumpysailushaNo ratings yet
- Building a Deep Neural Network for Binary Classification in TensorFlowDocument6 pagesBuilding a Deep Neural Network for Binary Classification in TensorFlowAradhana Mehra0% (1)
- Using Any Data, Apply The Concept of Logistic Regression.Document4 pagesUsing Any Data, Apply The Concept of Logistic Regression.19-361 Sai PrathikNo ratings yet
- Matplotlib AIDocument38 pagesMatplotlib AISaif JuttNo ratings yet
- Prob13: 1 EE16A Homework 13Document23 pagesProb13: 1 EE16A Homework 13Michael ARKNo ratings yet
- Matplotlib and Seaborn PDFDocument29 pagesMatplotlib and Seaborn PDFSAGAR RAJU DUDHABHATE100% (1)
- Q 3 X 1Document4 pagesQ 3 X 1言哲凡No ratings yet
- ML Lab ManualDocument37 pagesML Lab Manualapekshapandekar01100% (1)
- Maxbox - Starter67 Machine LearningDocument7 pagesMaxbox - Starter67 Machine LearningMax KleinerNo ratings yet
- DM PracticeDocument15 pagesDM Practice66 Rohit PatilNo ratings yet
- Is Lab Aman Agarwal PDFDocument8 pagesIs Lab Aman Agarwal PDFAman BansalNo ratings yet
- Logistic Regression With A Neural Network Mindset: 1 - PackagesDocument23 pagesLogistic Regression With A Neural Network Mindset: 1 - PackagesGijacis KhasengNo ratings yet
- Lectur2 PANDASDocument65 pagesLectur2 PANDAShandotinashe15No ratings yet
- InitializationDocument16 pagesInitializationlexNo ratings yet
- Machine Learning ExperimentsDocument7 pagesMachine Learning ExperimentsIngame IdNo ratings yet
- Chapter02 Mathematical-Building-BlocksDocument9 pagesChapter02 Mathematical-Building-BlocksJas LimNo ratings yet
- 4ann - 5Th ProgDocument15 pages4ann - 5Th Progshreyas .cNo ratings yet
- ML LabDocument7 pagesML LabSharan PatilNo ratings yet
- DM Slip SolutionsDocument24 pagesDM Slip Solutions09.Khadija Gharatkar100% (1)
- 16BCB0126 VL2018195002535 Pe003Document40 pages16BCB0126 VL2018195002535 Pe003MohitNo ratings yet
- PythonfileDocument36 pagesPythonfilecollection58209No ratings yet
- Lab 4Document21 pagesLab 4parvathyms1989No ratings yet
- Advance AI and ML LABDocument16 pagesAdvance AI and ML LABPriyanka PriyaNo ratings yet
- Linear Congruential Method TestsDocument12 pagesLinear Congruential Method TestsRenato MarquesNo ratings yet
- Ilovepdf MergedDocument10 pagesIlovepdf MergedPattranit TeerakosonNo ratings yet
- Introduction To NumpyDocument41 pagesIntroduction To NumpyRam PrasadNo ratings yet
- sectionSVM PDFDocument10 pagessectionSVM PDFArif Rahman HakimNo ratings yet
- Num PyDocument48 pagesNum Pysubodhaade2No ratings yet
- Ann - Lab - Ipynb - ColaboratoryDocument7 pagesAnn - Lab - Ipynb - Colaboratorysohan kamsaniNo ratings yet
- Tutorial 6Document8 pagesTutorial 6POEASONo ratings yet
- Matplotlib (2)Document23 pagesMatplotlib (2)mereddykarthikeyamereddy88395No ratings yet
- How To Train A Model With MNIST DatasetDocument7 pagesHow To Train A Model With MNIST DatasetMagdalena FalkowskaNo ratings yet
- Big Data Assignment - 4Document6 pagesBig Data Assignment - 4Rajeev MukheshNo ratings yet
- Class 10 AI Practiacls 2023-24Document4 pagesClass 10 AI Practiacls 2023-24singhmrinalini1305No ratings yet
- Weap - ModflowDocument20 pagesWeap - Modflowguive3No ratings yet
- Water TreatmentDocument6 pagesWater TreatmentSantiago LarrazNo ratings yet
- Glossary of Permafrost and Ground-Ice IPA 2005Document159 pagesGlossary of Permafrost and Ground-Ice IPA 2005NatitaGonzàlezDíazNo ratings yet
- Neil Strauss - The Annihilation Method - Style's Archives - Volume 1 - The Origin of Style - How To Transform From Chump To Champ in No TimeDocument132 pagesNeil Strauss - The Annihilation Method - Style's Archives - Volume 1 - The Origin of Style - How To Transform From Chump To Champ in No TimeDaniel Nii Armah Tetteh100% (2)
- RJR Nabisco LBODocument14 pagesRJR Nabisco LBONazir Ahmad BahariNo ratings yet
- UFD/MMC/SD Controller Flash Support Limitation and Interconnection NoteDocument5 pagesUFD/MMC/SD Controller Flash Support Limitation and Interconnection Noteمہرؤآنہ آبہرآهہيہمہNo ratings yet
- Company Electronics Appliances Semiconductors South Korea's: SamsungDocument61 pagesCompany Electronics Appliances Semiconductors South Korea's: Samsunghaseeb ahmedNo ratings yet
- Australian Institute For Teaching and School Leadership - AITSLDocument5 pagesAustralian Institute For Teaching and School Leadership - AITSLYu LiNo ratings yet
- Som-Ii Uqb 2019-20Document23 pagesSom-Ii Uqb 2019-20VENKATESH METHRINo ratings yet
- C42135AA Beckman Coulter ClearLLab 10C Casebook PDFDocument586 pagesC42135AA Beckman Coulter ClearLLab 10C Casebook PDFHam Bone100% (1)
- Number SystemDocument4 pagesNumber SystemGlenn ThomasNo ratings yet
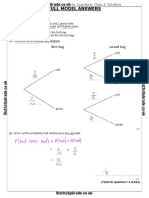
- Probability Tree Diagrams Solutions Mathsupgrade Co UkDocument10 pagesProbability Tree Diagrams Solutions Mathsupgrade Co UknatsNo ratings yet
- Quiz - Limits and ContinuityDocument3 pagesQuiz - Limits and ContinuityAdamNo ratings yet
- Teachers' Notes: ©film Education 1Document20 pagesTeachers' Notes: ©film Education 1רז ברקוNo ratings yet
- Contoh Skripsi Bahasa Inggris Case StudyDocument18 pagesContoh Skripsi Bahasa Inggris Case StudyRizki Fajrita100% (14)
- SRT95 Off-Highway Truck Rear Axle Assembly: Structure and Installation Part 2 Parts Presentation Part 3 MaintenanceDocument29 pagesSRT95 Off-Highway Truck Rear Axle Assembly: Structure and Installation Part 2 Parts Presentation Part 3 MaintenanceoktopusNo ratings yet
- Strategic Management and Municipal Financial ReportingDocument38 pagesStrategic Management and Municipal Financial ReportingMarius BuysNo ratings yet
- Lembar Jawaban Skillab Evidence Based Medicine (Ebm) Nama: Rafika Triasa NIM: 040427223270003Document11 pagesLembar Jawaban Skillab Evidence Based Medicine (Ebm) Nama: Rafika Triasa NIM: 040427223270003Yahya Darmais FaridNo ratings yet
- Danh sách KH Biệt Thự Thảo Điền - Quận 2Document4 pagesDanh sách KH Biệt Thự Thảo Điền - Quận 2La TraNo ratings yet
- Advantages and Disadvantages of Becoming EntrepreneurDocument2 pagesAdvantages and Disadvantages of Becoming EntrepreneurbxndNo ratings yet
- Taco Bell - Re EngineeringDocument6 pagesTaco Bell - Re Engineeringabcxyz2811100% (6)
- Vernacular Terms in Philippine ConstructionDocument3 pagesVernacular Terms in Philippine ConstructionFelix Albit Ogabang IiiNo ratings yet
- Design Report For Proposed 3storied ResidentialbuildingDocument35 pagesDesign Report For Proposed 3storied ResidentialbuildingMohamed RinosNo ratings yet
- Sustainability - Research PaperDocument18 pagesSustainability - Research PapermrigssNo ratings yet
- African in The Modern WorldDocument18 pagesAfrican in The Modern WorldSally AnkomaahNo ratings yet
- Duane Grant, A099 743 627 (BIA Sept. 9, 2016)Document12 pagesDuane Grant, A099 743 627 (BIA Sept. 9, 2016)Immigrant & Refugee Appellate Center, LLCNo ratings yet
- List of Blade MaterialsDocument19 pagesList of Blade MaterialsAnie Ummu Alif & SyifaNo ratings yet
- Lyrics: Original Songs: - JW BroadcastingDocument56 pagesLyrics: Original Songs: - JW BroadcastingLucky MorenoNo ratings yet
- Texto en inglesDocument5 pagesTexto en inglesJesus Andres Lopez YañezNo ratings yet
- Serv Manual SM 100 FREEDocument75 pagesServ Manual SM 100 FREEGustavo Vargas Ruiz100% (1)