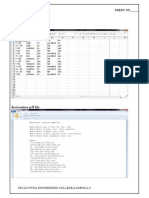
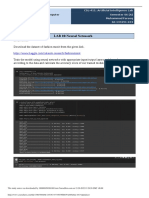
You might also like
- DATA MINING and MACHINE LEARNING. PREDICTIVE TECHNIQUES: ENSEMBLE METHODS, BOOSTING, BAGGING, RANDOM FOREST, DECISION TREES and REGRESSION TREES.: Examples with MATLABFrom EverandDATA MINING and MACHINE LEARNING. PREDICTIVE TECHNIQUES: ENSEMBLE METHODS, BOOSTING, BAGGING, RANDOM FOREST, DECISION TREES and REGRESSION TREES.: Examples with MATLABNo ratings yet
- ML Lab 6Document7 pagesML Lab 6Jahangir AwanNo ratings yet
- Ai Lab 7Document3 pagesAi Lab 7Aeman ArainNo ratings yet
- St. John College of Engineering and Management, Palghar - MaharashtraDocument11 pagesSt. John College of Engineering and Management, Palghar - MaharashtrapranayNo ratings yet
- ML 2.4 PrashantDocument3 pagesML 2.4 Prashantdeadm2996No ratings yet
- Data Mining and Warehousing Concepts Lab: (ITPC - 228)Document6 pagesData Mining and Warehousing Concepts Lab: (ITPC - 228)Angelina TutuNo ratings yet
- DL Record MergedDocument113 pagesDL Record MergedeeshikagandiNo ratings yet
- CNN CodeDocument6 pagesCNN CodeSudhanNo ratings yet
- ML Lab Manual (1-10) FINALDocument34 pagesML Lab Manual (1-10) FINALchintuNo ratings yet
- Iris - Regression - Jupyter NotebookDocument5 pagesIris - Regression - Jupyter NotebookBibhudutta SwainNo ratings yet
- ML 2.3 PrashantDocument4 pagesML 2.3 Prashantdeadm2996No ratings yet
- 20BCS7251 - ML Lab 2.1Document7 pages20BCS7251 - ML Lab 2.1Anukrati 20BCS7238No ratings yet
- ML Priyesha - 778Document23 pagesML Priyesha - 778shivanipate05No ratings yet
- Lab 1. Boston HouseDocument7 pagesLab 1. Boston Housedimas bayuNo ratings yet
- Iris Dataset Clustering and Spam Email SeparationDocument20 pagesIris Dataset Clustering and Spam Email SeparationAkash M ShahzadNo ratings yet
- Vishal AIML 2.2Document4 pagesVishal AIML 2.2Vishal SinghNo ratings yet
- Safety For Drivers Using OpenCV in PythonDocument8 pagesSafety For Drivers Using OpenCV in PythonIJRASETPublicationsNo ratings yet
- DM + KavithaDocument22 pagesDM + Kavithasyam_5491983No ratings yet
- Generative AI Binary ClassificationDocument7 pagesGenerative AI Binary ClassificationCyborg UltraNo ratings yet
- IRIS BPNN - Ipynb - ColaboratoryDocument4 pagesIRIS BPNN - Ipynb - Colaboratoryrwn data100% (1)
- Feature SelectionDocument8 pagesFeature SelectionAbinaya CNo ratings yet
- Keras CheatSheet PGAADocument1 pageKeras CheatSheet PGAAPooja BhushanNo ratings yet
- Reagrding Lab TestDocument8 pagesReagrding Lab Testaman rajNo ratings yet
- ML JournalDocument37 pagesML JournalVaishnavis ARTNo ratings yet
- DL RecordDocument37 pagesDL RecordNAWAS HussainNo ratings yet
- 7-2 AssDocument3 pages7-2 AssRamya AnushaNo ratings yet
- Ai Lab 9Document2 pagesAi Lab 9Ali RajpootNo ratings yet
- Tutorial 2 - ClusteringDocument6 pagesTutorial 2 - ClusteringGupta Akshay100% (2)
- ML - LAB - FILE AmritDocument13 pagesML - LAB - FILE AmritkhatmalmainNo ratings yet
- Decision Tree, Random ForestDocument37 pagesDecision Tree, Random ForestAkshay kashyapNo ratings yet
- Deep Learning RecordDocument70 pagesDeep Learning Recordmathan.balaji.02No ratings yet
- Aman Raj DTDocument8 pagesAman Raj DTSachin kumarNo ratings yet
- Week 9 Assignment 9.1 1Document2 pagesWeek 9 Assignment 9.1 1Charan NuthalapatiNo ratings yet
- Ilovepdf MergedDocument25 pagesIlovepdf Mergedrohitfc3105No ratings yet
- Introduction To Python and Computer Programming 1704298503Document44 pagesIntroduction To Python and Computer Programming 1704298503el.tico.138623No ratings yet
- CV 5Document4 pagesCV 5jiteshkumardjNo ratings yet
- Lab - 5 (CB - En.u4ece22115)Document5 pagesLab - 5 (CB - En.u4ece22115)Daejuswaram GopinathNo ratings yet
- Lab7.ipynb - ColaboratoryDocument5 pagesLab7.ipynb - ColaboratoryPRAGASM PROG100% (1)
- Worksheet No. 9: 1. Aim/Overview of The PracticalDocument6 pagesWorksheet No. 9: 1. Aim/Overview of The PracticalBLACKER EMPIRENo ratings yet
- Experiment No.: 8: T. Y. B. Tech (CSE) - II Subject: Open Source Lab-IIDocument2 pagesExperiment No.: 8: T. Y. B. Tech (CSE) - II Subject: Open Source Lab-IIASHISH MALINo ratings yet
- Deeptech Batch ANP-C5984,5743 2-ADocument9 pagesDeeptech Batch ANP-C5984,5743 2-ADhanush ArjunanNo ratings yet
- PL IiDocument43 pagesPL IiRohan 7No ratings yet
- ML - Practical FileDocument15 pagesML - Practical FileJatin MathurNo ratings yet
- Output2Document2 pagesOutput2Laptop-Dimas-249No ratings yet
- 21BEE0103 (Iot 2theory)Document7 pages21BEE0103 (Iot 2theory)srujanNo ratings yet
- DM 6Document4 pagesDM 6Ayush KashyapNo ratings yet
- 361 Project CodeDocument10 pages361 Project CodeskdlfNo ratings yet
- Lab W7Document4 pagesLab W7ARINA SYAKIRAH MUHAIYUDDINNo ratings yet
- Logistic RegressionDocument8 pagesLogistic RegressionNipuniNo ratings yet
- AIML Exp 9Document8 pagesAIML Exp 9Kartik GuleriaNo ratings yet
- Assignment 3 DS5620Document11 pagesAssignment 3 DS5620humaragptNo ratings yet
- Aiml 6 and 7 DayanaDocument2 pagesAiml 6 and 7 DayanaI yr IT 10-Cherisha SNo ratings yet
- 4 Decision Tree - Jupyter NotebookDocument2 pages4 Decision Tree - Jupyter Notebookvenkatesh mNo ratings yet
- Experiment:3.2: Relevance of The ExperimentDocument8 pagesExperiment:3.2: Relevance of The Experimentnishant singhNo ratings yet
- HIM&MDA Manual 8Document2 pagesHIM&MDA Manual 8mostafa abouzeedNo ratings yet
- Training and EvaluationDocument20 pagesTraining and Evaluationnegisid126No ratings yet
- Quiz MasterDocument17 pagesQuiz MasterMukesh JangraNo ratings yet
- Cs2258 Database Management Systems LabDocument12 pagesCs2258 Database Management Systems LabDhayaNo ratings yet
- ML - LAB - FILE PankajDocument13 pagesML - LAB - FILE PankajkhatmalmainNo ratings yet
- Audio ClassificationDocument1 pageAudio Classification1MV19ET014 Divya TANo ratings yet
- Database RevisionDocument10 pagesDatabase RevisionSergio YazNo ratings yet
- General Physics 1: Tayabas Western Academy Recognized by The Government Candelaria, QuezonDocument6 pagesGeneral Physics 1: Tayabas Western Academy Recognized by The Government Candelaria, QuezonNoel AbrazadoNo ratings yet
- Discrete-Time Fourier Methods: M. J. Roberts All Rights Reserved. Edited by Dr. Robert AklDocument72 pagesDiscrete-Time Fourier Methods: M. J. Roberts All Rights Reserved. Edited by Dr. Robert AklvenkatNo ratings yet
- Lagrange2 NokeyDocument2 pagesLagrange2 NokeyAdityaNo ratings yet
- SJB Institute of Technology: Module - 2 Symmetric CiphersDocument67 pagesSJB Institute of Technology: Module - 2 Symmetric Cipherssasindhur rNo ratings yet
- IFEM Ch28Document6 pagesIFEM Ch28Yiling HeNo ratings yet
- Case Study Solution - Network of QueuesDocument26 pagesCase Study Solution - Network of Queuesvasu_ks438No ratings yet
- Transfer Function - Poles and Zeros - StabilityDocument9 pagesTransfer Function - Poles and Zeros - Stability666667No ratings yet
- Research Chapter 1Document3 pagesResearch Chapter 1Drea TheanaNo ratings yet
- Tamil Handwritten Character Recognition: BY V.Meenalochini K.DharshiniDocument31 pagesTamil Handwritten Character Recognition: BY V.Meenalochini K.DharshiniDHARSHINI KNo ratings yet
- ELG3155 - Control SystemsDocument5 pagesELG3155 - Control SystemsTurab HaiderNo ratings yet
- Notes On Stochastic Processes: 1 Learning OutcomesDocument26 pagesNotes On Stochastic Processes: 1 Learning OutcomesSheikh Mijanur RahamanNo ratings yet
- Melody Generation Using An Interactive Evolutionary AlgorithmDocument6 pagesMelody Generation Using An Interactive Evolutionary AlgorithmOmar Lopez-RinconNo ratings yet
- Big M MethodDocument12 pagesBig M MethodAbhishek SinghNo ratings yet
- Complex Weak Values in Quantum MeasurementDocument3 pagesComplex Weak Values in Quantum MeasurementsankhaNo ratings yet
- Good Books On Quantum ComputingDocument3 pagesGood Books On Quantum ComputingDeon100% (1)
- Introduction To CryptographyDocument31 pagesIntroduction To CryptographyzaikoryuNo ratings yet
- Real Time Deep Learning Weapon Detection Techniques For Mitigating Lone Wolf AttacksDocument16 pagesReal Time Deep Learning Weapon Detection Techniques For Mitigating Lone Wolf AttacksAdam HansenNo ratings yet
- Question Bank 2021-22Document5 pagesQuestion Bank 2021-22Tanmay DoshiNo ratings yet
- CES521 - 3 - Stifeness Method (Truss)Document49 pagesCES521 - 3 - Stifeness Method (Truss)Imran37AfiqNo ratings yet
- Test 6 and 7B AP Statistics Name:: Y - 1 0 1 2 - P (Y) 3C 2C 0.4 0.1Document5 pagesTest 6 and 7B AP Statistics Name:: Y - 1 0 1 2 - P (Y) 3C 2C 0.4 0.1Elizabeth CNo ratings yet
- General EquilibriumDocument4 pagesGeneral EquilibriumSaadgi AgarwalNo ratings yet
- Kalman FilterDocument11 pagesKalman FilterSanjay Kumar GuptaNo ratings yet
- Coursera - Online Courses From Top Universities. Join For Free - CourseraDocument7 pagesCoursera - Online Courses From Top Universities. Join For Free - CourseraPum Chung TinhNo ratings yet
- Santos 2023 UsingDocument19 pagesSantos 2023 Usingjomehovotim3No ratings yet
- Ajol File Journals - 660 - Articles - 229282 - Submission - Proof - 229282 7780 557222 1 10 20220805Document17 pagesAjol File Journals - 660 - Articles - 229282 - Submission - Proof - 229282 7780 557222 1 10 20220805dzulfikar fahleviNo ratings yet
- Lecture # 39Document13 pagesLecture # 39Mazoon ButtNo ratings yet
- Quantum Electrodynamics by Imran AzizDocument29 pagesQuantum Electrodynamics by Imran AzizDr.Imran Aziz0% (1)
- Assignment 1Document2 pagesAssignment 1Mohammed BahysmiNo ratings yet
- Intro MUSSVDocument4 pagesIntro MUSSVMohammad Naser HashemniaNo ratings yet