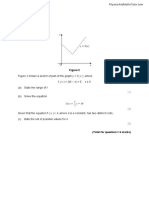
You might also like
- Axiatonal Lines Connection IntroductionDocument9 pagesAxiatonal Lines Connection IntroductionDavid Lopes100% (1)
- A Machine Learning Analysis of Stock Market Tick Data For Stock Price Trend PredictionDocument24 pagesA Machine Learning Analysis of Stock Market Tick Data For Stock Price Trend PredictionPrakash Pokhrel100% (1)
- CSS - Proper Use and Maintenance of ToolsDocument1 pageCSS - Proper Use and Maintenance of ToolsRowell Marquina100% (1)
- Treadmill Error Code GuideDocument19 pagesTreadmill Error Code GuideŞener MutluNo ratings yet
- A hybrid genetic-neural system for stock index forecastingDocument31 pagesA hybrid genetic-neural system for stock index forecastingMaurizio IdiniNo ratings yet
- Forecasting with Time Series Analysis Methods and ApplicationsFrom EverandForecasting with Time Series Analysis Methods and ApplicationsNo ratings yet
- Forecasting Stock Trend Using R and Technical IndicatorsDocument14 pagesForecasting Stock Trend Using R and Technical Indicatorsmohan100% (1)
- Stock Price Prediction Using Machine LearningDocument15 pagesStock Price Prediction Using Machine LearningIJRASETPublications100% (1)
- Applying The PROACT RCA Methodology.4.26.16Document30 pagesApplying The PROACT RCA Methodology.4.26.16Alexandar ApishaNo ratings yet
- Science: Locating Places On Earth Using Coordinate SystemDocument29 pagesScience: Locating Places On Earth Using Coordinate Systemlawrence maputolNo ratings yet
- Opening Range Breakout Stock Trading Algorithmic ModelDocument7 pagesOpening Range Breakout Stock Trading Algorithmic ModelJames MorenoNo ratings yet
- A Comparative Study of Time Series Forecasting Methods Using Real DataDocument17 pagesA Comparative Study of Time Series Forecasting Methods Using Real Dataswami vardhanNo ratings yet
- Stock Market Analysis and Prediction: Jabalpur Engineering College, Jabalpur (M.P.)Document12 pagesStock Market Analysis and Prediction: Jabalpur Engineering College, Jabalpur (M.P.)Amit AmarwanshiNo ratings yet
- Diker Ab Primenenie Metodov Mashinnogo Obucheniya Dlya Klasterizacii Finansovyh Vremennyh Ryadov 37074Document50 pagesDiker Ab Primenenie Metodov Mashinnogo Obucheniya Dlya Klasterizacii Finansovyh Vremennyh Ryadov 37074tema.kouznetsovNo ratings yet
- Stock Market Analysis Using Classification Algorithm PDFDocument6 pagesStock Market Analysis Using Classification Algorithm PDFResearch Journal of Engineering Technology and Medical Sciences (RJETM)No ratings yet
- Fulltext01 PDFDocument91 pagesFulltext01 PDFApoorv SinhaNo ratings yet
- Documentation of Stock-Market-Prediction Final ProjectDocument21 pagesDocumentation of Stock-Market-Prediction Final ProjectIndra Kishor Chaudhary AvaiduwaiNo ratings yet
- Time Series For Retail StoreDocument10 pagesTime Series For Retail Storekislaya kumarNo ratings yet
- FULLTEXT01Document41 pagesFULLTEXT01nadji rezigNo ratings yet
- IJCRT2002120Document4 pagesIJCRT2002120pvk1730No ratings yet
- Prediction of Stock Market Using Machine Learning AlgorithmsDocument12 pagesPrediction of Stock Market Using Machine Learning AlgorithmsterranceNo ratings yet
- Forecasting Stock Price Index Using Artificial Neural Networks in The Indonesian Stock ExchangeDocument67 pagesForecasting Stock Price Index Using Artificial Neural Networks in The Indonesian Stock ExchangeTimothy DiazNo ratings yet
- ICBAI 2018 Final PaperDocument10 pagesICBAI 2018 Final Papersellymargaretha41No ratings yet
- Computation 07 00067 v2Document25 pagesComputation 07 00067 v2Com DigfulNo ratings yet
- Building Rating and Data Analysis Module For The Distributor and Seller Product HandlingDocument20 pagesBuilding Rating and Data Analysis Module For The Distributor and Seller Product Handlinggattus123No ratings yet
- Forecasting Lec 1 & 2 EditedDocument27 pagesForecasting Lec 1 & 2 EditedJungle DiffNo ratings yet
- Chapter III FORECASTINGDocument14 pagesChapter III FORECASTINGYohannis YoniNo ratings yet
- Prediction Models For Indian Stock MarketDocument9 pagesPrediction Models For Indian Stock MarketRajat ShrinetNo ratings yet
- DocDocument35 pagesDocSumaNo ratings yet
- Technical Report Writing For Ca2 ExaminationDocument6 pagesTechnical Report Writing For Ca2 ExaminationAishee DuttaNo ratings yet
- 19 Stock Price Trend Predictionusing Multiple Linear RegressionDocument6 pages19 Stock Price Trend Predictionusing Multiple Linear Regressionnhoxsock8642No ratings yet
- Trading in Indian Stock Market Using ANN: A Decision ReviewDocument11 pagesTrading in Indian Stock Market Using ANN: A Decision Reviewmonik shahNo ratings yet
- Cracan ThesisDocument35 pagesCracan Thesismaq aqNo ratings yet
- V6i6 0305Document4 pagesV6i6 0305penumudi233No ratings yet
- A Technique To Stock Market Prediction Using Fuzzy Clustering and Artificial Neural Networks Rajendran SugumarDocument33 pagesA Technique To Stock Market Prediction Using Fuzzy Clustering and Artificial Neural Networks Rajendran SugumarMaryam OmolaraNo ratings yet
- Machine Learning Using Python Project Report: Stock Price Prediction Using MLDocument21 pagesMachine Learning Using Python Project Report: Stock Price Prediction Using MLSHIVAM KUMAR SINGHNo ratings yet
- Stock Price Preduction ReportDocument4 pagesStock Price Preduction Reportsavan3019No ratings yet
- A Comparative Study On Financial Stock Market Prediction ModelsDocument4 pagesA Comparative Study On Financial Stock Market Prediction ModelstheijesNo ratings yet
- Applied Sciences: Prediction of Stock Performance Using Deep Neural NetworksDocument20 pagesApplied Sciences: Prediction of Stock Performance Using Deep Neural NetworksLuiz RamosNo ratings yet
- Onward To PredictionDocument3 pagesOnward To PredictionJAN PAOLO LUMPAZNo ratings yet
- Stock Market Analysis PDFDocument5 pagesStock Market Analysis PDFVrinda VashishthNo ratings yet
- Stock Trend Prediction Using News and Sentiment Analysis: Project Guide:-Prof. Ashish AwateDocument12 pagesStock Trend Prediction Using News and Sentiment Analysis: Project Guide:-Prof. Ashish AwateManish Patil100% (1)
- Springerbriefs in Applied Sciences and Technology: Computational IntelligenceDocument89 pagesSpringerbriefs in Applied Sciences and Technology: Computational IntelligenceDipen PandyaNo ratings yet
- 5-Stock Price Forecasting by Combining News Mining ADocument5 pages5-Stock Price Forecasting by Combining News Mining AGrace MutoreNo ratings yet
- Comparing Time Series Forecasting Methods for Sales PredictionDocument25 pagesComparing Time Series Forecasting Methods for Sales Predictionswami vardhanNo ratings yet
- Bai 1960Document13 pagesBai 1960Matias VargasNo ratings yet
- Entropy: A Labeling Method For Financial Time Series Prediction Based On TrendsDocument27 pagesEntropy: A Labeling Method For Financial Time Series Prediction Based On TrendsPhillipe S. ScofieldNo ratings yet
- Sample Research Proposal 1Document16 pagesSample Research Proposal 1Nanduni ChampathiNo ratings yet
- A Decision Tree-Rough Set Hybrid System For Stock Market Trend PredictionDocument6 pagesA Decision Tree-Rough Set Hybrid System For Stock Market Trend PredictionDevRishi C. VijanNo ratings yet
- 4 Ijaema December 4812Document7 pages4 Ijaema December 4812Sarita RijalNo ratings yet
- Stock Price Prediction Using Sentiment Analysis and Deep Learning for Indian MarketsDocument15 pagesStock Price Prediction Using Sentiment Analysis and Deep Learning for Indian Marketsselecao13No ratings yet
- A Securities Exchange Prospect Utilizing AIDocument4 pagesA Securities Exchange Prospect Utilizing AIInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Comparison of Financial Models For Stock Price PredictionDocument20 pagesComparison of Financial Models For Stock Price PredictionLe Cong Nhat MinhNo ratings yet
- Entropy 18 00435 PDFDocument16 pagesEntropy 18 00435 PDFKarim LaidiNo ratings yet
- Prediction of Stock Market Prices Using Machine Learning-1Document17 pagesPrediction of Stock Market Prices Using Machine Learning-1errorfinder22No ratings yet
- Stock Market Prediction Using Machine LearningDocument7 pagesStock Market Prediction Using Machine LearningIJRASETPublications100% (1)
- Stock Price Prediction - Links and How To Approach .Document3 pagesStock Price Prediction - Links and How To Approach .Nikher VermaNo ratings yet
- Chapter 1Document7 pagesChapter 1ashi ashiNo ratings yet
- A Dual-Attention-Based Stock Price Trend Prediction Model With Dual FeaturesDocument12 pagesA Dual-Attention-Based Stock Price Trend Prediction Model With Dual FeaturesM AnNo ratings yet
- Machine Learning Techniques for Stock Market PredictionDocument60 pagesMachine Learning Techniques for Stock Market PredictionRishi GoyalNo ratings yet
- Time Series Analysis Project in R On Stock Market ForecastingDocument22 pagesTime Series Analysis Project in R On Stock Market ForecastingAnanya BohareNo ratings yet
- Experimental results for case study stock prediction modelsDocument4 pagesExperimental results for case study stock prediction modelsSri NivasNo ratings yet
- Individual AssigngmentDocument13 pagesIndividual AssigngmentKeyd MuhumedNo ratings yet
- Sentire 2018 WangDocument6 pagesSentire 2018 Wangnurdi afriantoNo ratings yet
- DNA Microarrays: DR Divya GuptaDocument33 pagesDNA Microarrays: DR Divya GuptaRuchi SharmaNo ratings yet
- Create Database VentasDocument11 pagesCreate Database VentasAnonymous BwTccxNo ratings yet
- Alayo, M. Internationalization and Entrepreneurial Orientation of Family SMEs The Influence of The Family CharacterArticle 2019Document12 pagesAlayo, M. Internationalization and Entrepreneurial Orientation of Family SMEs The Influence of The Family CharacterArticle 2019Riezz MauladiNo ratings yet
- Bypass Sony KDL-55W900A 4X LED Blinking ErrorDocument7 pagesBypass Sony KDL-55W900A 4X LED Blinking ErroruzenNo ratings yet
- Analyzing Resources and CapabilitiesDocument6 pagesAnalyzing Resources and CapabilitiesImola FazakasNo ratings yet
- Serie 700 Conmutador Ethernet Industrial Administrado Manual Del Usuario y Guía de InstalaciónDocument181 pagesSerie 700 Conmutador Ethernet Industrial Administrado Manual Del Usuario y Guía de InstalaciónJorge Andrés Pérez MillarNo ratings yet
- Experiment No. 2 Introduction To Combinational Circuits: Group Name: Group 7 Group Leader: JOSE DOROSAN Group MemberDocument11 pagesExperiment No. 2 Introduction To Combinational Circuits: Group Name: Group 7 Group Leader: JOSE DOROSAN Group MemberJoy PeconcilloNo ratings yet
- Echotrac Mkiii: Model DFDocument2 pagesEchotrac Mkiii: Model DFjonathansolverNo ratings yet
- Lord Dyrron Baratheon, Warden of the StormlandsDocument2 pagesLord Dyrron Baratheon, Warden of the StormlandsDaniel AthertonNo ratings yet
- 35.4 Uses Principles of Effective Speech Writing Focusing On Facial Expressions, Gestures and MovementsDocument4 pages35.4 Uses Principles of Effective Speech Writing Focusing On Facial Expressions, Gestures and MovementsWayne Dolorico MillamenaNo ratings yet
- Inside Earth's LayersDocument2 pagesInside Earth's Layersansh parasharNo ratings yet
- Qognify-VisionHub-Brochure - Rev.01Document4 pagesQognify-VisionHub-Brochure - Rev.01Sarah BerlianiNo ratings yet
- The 5 Stages of the Design ProcessDocument5 pagesThe 5 Stages of the Design ProcessDacia BarrettNo ratings yet
- Hydraulic ConductivityDocument8 pagesHydraulic ConductivityJill AndersonNo ratings yet
- Pellet PLNT ManualDocument19 pagesPellet PLNT ManualsubhankarprustyNo ratings yet
- Se Unit 1Document77 pagesSe Unit 1sathyaaaaa1No ratings yet
- Klein After BachelardDocument13 pagesKlein After Bachelardyupengw122No ratings yet
- Zaib Baig: EducationDocument1 pageZaib Baig: Educationapi-316869427No ratings yet
- Law of Insurance Eighth Semester SyllabusDocument3 pagesLaw of Insurance Eighth Semester SyllabusAastha PrakashNo ratings yet
- Galloping Instability To Chaos - Albert C.J. Luo, Bo YuDocument213 pagesGalloping Instability To Chaos - Albert C.J. Luo, Bo YuHuy Thông NguyễnNo ratings yet
- Mosfet 100 VoltDocument9 pagesMosfet 100 Voltnithinmundackal3623No ratings yet
- Big Data Maturity ModelDocument6 pagesBig Data Maturity Modelkatherine976No ratings yet
- Bank Reconciliation Step-By-Step TutorialDocument20 pagesBank Reconciliation Step-By-Step TutorialTạ Tuấn DũngNo ratings yet
- Modulus of FunctionsDocument14 pagesModulus of FunctionsVajan SelvaratnamNo ratings yet
- Reading PDFDocument6 pagesReading PDFoviNo ratings yet