You might also like
- ML 1Document4 pagesML 1yefigoh133No ratings yet
- IRIS DatasetDocument7 pagesIRIS DatasetEggg RrrrNo ratings yet
- EXAM PREPERATION - Ipynb - Colaboratory-1Document8 pagesEXAM PREPERATION - Ipynb - Colaboratory-1VkingNo ratings yet
- Week 6.2Document9 pagesWeek 6.2I.A.P. JABH RIDETNo ratings yet
- DeepTrading With TensorFlow 4 - TodoTraderDocument14 pagesDeepTrading With TensorFlow 4 - TodoTraderalypatyNo ratings yet
- BDA pr2Document2 pagesBDA pr2Dev PathakNo ratings yet
- Linear RegressionDocument1 pageLinear Regressionmogak92082No ratings yet
- DeepTrading With TensorFlow 3 - TodoTraderDocument10 pagesDeepTrading With TensorFlow 3 - TodoTraderalypatyNo ratings yet
- Implementation of Simple Linear Regression Algorithm Using PythonDocument12 pagesImplementation of Simple Linear Regression Algorithm Using Pythonayushisahoo2004No ratings yet
- Aula Big DataDocument5 pagesAula Big DataAntônio José SilvaNo ratings yet
- #Magapu Harsha #ADA Lab Slot (L47+L48) Pandas PD Numpy NP Matplotlib Pyplot PLT DF PD - Read - CSV DFDocument9 pages#Magapu Harsha #ADA Lab Slot (L47+L48) Pandas PD Numpy NP Matplotlib Pyplot PLT DF PD - Read - CSV DFSHAIK AZAJUDDIN 18MIS7192No ratings yet
- SC Assignment Q2Document7 pagesSC Assignment Q2RAGHUVAMSHI -2019BCSIIITKNo ratings yet
- Experiment-2-1-Ml KritikaDocument11 pagesExperiment-2-1-Ml KritikaKRITIKA DASNo ratings yet
- Week11 N9Document5 pagesWeek11 N920131A05N9 SRUTHIK THOKALANo ratings yet
- ENTREGABLE 3 ESTADISTICAS GC-RICARDO LA FUENTE - Ipynb - ColaboratoryDocument4 pagesENTREGABLE 3 ESTADISTICAS GC-RICARDO LA FUENTE - Ipynb - ColaboratoryRicardo Angel La FuenteNo ratings yet
- 3) Code For ID3 Algorithm ImplementationDocument8 pages3) Code For ID3 Algorithm ImplementationPrajith Sprinťèř100% (1)
- Assignments - Day 2 - Jupyter NotebookDocument6 pagesAssignments - Day 2 - Jupyter NotebookSrinAdh YadavNo ratings yet
- JTD3E - 24 - Syamsul Huda Puji Ananta - Kmeans Dan KNNDocument6 pagesJTD3E - 24 - Syamsul Huda Puji Ananta - Kmeans Dan KNNMikhail RachmanNo ratings yet
- JTD3E - 24 - Syamsul Huda Puji Ananta - Kmeans Dan KNNDocument6 pagesJTD3E - 24 - Syamsul Huda Puji Ananta - Kmeans Dan KNNMikhail RachmanNo ratings yet
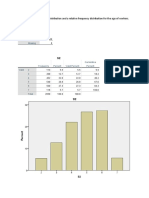
- Statistics: (C) Calculate The Frequency Distribution and A Relative Frequency Distribution For The Age of WorkersDocument3 pagesStatistics: (C) Calculate The Frequency Distribution and A Relative Frequency Distribution For The Age of WorkersMohammadNo ratings yet
- Solution 1 CDocument3 pagesSolution 1 CMohammadNo ratings yet
- Statistics: (C) Calculate The Frequency Distribution and A Relative Frequency Distribution For The Age of WorkersDocument3 pagesStatistics: (C) Calculate The Frequency Distribution and A Relative Frequency Distribution For The Age of WorkersMohammadNo ratings yet
- Spss Kelas A AnfismanDocument4 pagesSpss Kelas A AnfismanArizatul AslamiyahNo ratings yet
- Productpage 3098Document2 pagesProductpage 3098rahmat hidayatNo ratings yet
- MINI PROJECT - MergedDocument8 pagesMINI PROJECT - Mergedbhanucse16No ratings yet
- CalculusDocument11 pagesCalculusSaverus Ricky ScamanderNo ratings yet
- DK2887 App18 PDFDocument2 pagesDK2887 App18 PDFpkj009No ratings yet
- Experiment 5 Magnetic Field Report SampleDocument8 pagesExperiment 5 Magnetic Field Report SampleThuc Pham Huynh TriNo ratings yet
- Libro 1Document4 pagesLibro 1KevinarturonsNo ratings yet
- Libro 1Document4 pagesLibro 1KevinarturonsNo ratings yet
- Case 1Document23 pagesCase 1Emad RashidNo ratings yet
- Coeficientul de CorelatieDocument15 pagesCoeficientul de CorelatieCosmin Care EsteNo ratings yet
- Exam-SPSS SolutionDocument12 pagesExam-SPSS Solutionjayminshah_rose1822No ratings yet
- Client: Mosaic Fertilizantes Location: Cajati-SPDocument20 pagesClient: Mosaic Fertilizantes Location: Cajati-SPFlavio /lvesNo ratings yet
- Grade 10 Curved Graphs Tangents and GradientsDocument15 pagesGrade 10 Curved Graphs Tangents and GradientsSri Devi NagarjunaNo ratings yet
- Anova Detailed ExampleDocument19 pagesAnova Detailed ExampleMano TostesNo ratings yet
- Data Science Practical No 10Document4 pagesData Science Practical No 10Satyavan MestryNo ratings yet
- Diffraction Intensity, I Position, X (MM) : Graph 1Document3 pagesDiffraction Intensity, I Position, X (MM) : Graph 1Arif JemaliNo ratings yet
- Decision TreeDocument1 pageDecision Treesid-harth sid-harth100% (1)
- IS 3601-2006 TablesDocument3 pagesIS 3601-2006 TablesarabsniperNo ratings yet
- Motor - Choising 2Document15 pagesMotor - Choising 2Cao Thắng NguyễnNo ratings yet
- Single Slit LabDocument7 pagesSingle Slit LabBejoy SenNo ratings yet
- Docume 868 RuDocument8 pagesDocume 868 RuAkshatNo ratings yet
- Assignment 10Document9 pagesAssignment 10SHREYANSHU KODILKARNo ratings yet
- Practical 2 51Document5 pagesPractical 2 51Royal EmpireNo ratings yet
- Laboratorio Virtual Mecanica - Velocidades A y B 19 y 20 de MayoDocument31 pagesLaboratorio Virtual Mecanica - Velocidades A y B 19 y 20 de MayoLAURA NEITA PICONo ratings yet
- Charmi Shah - 20BCP299 Assignment-4Document11 pagesCharmi Shah - 20BCP299 Assignment-4PrincyNo ratings yet
- Astm e 11 09 Standards PDFDocument1 pageAstm e 11 09 Standards PDFthanhhuyenNo ratings yet
- Ranking (Top To Bottom)Document7 pagesRanking (Top To Bottom)Soma SarkarNo ratings yet
- Nominal Size (Inches) : Outside Dia. Wall ThicknessDocument14 pagesNominal Size (Inches) : Outside Dia. Wall ThicknessMohammed Ms'cNo ratings yet
- PVC Pipe Size ChartDocument1 pagePVC Pipe Size ChartPurvi PatelNo ratings yet
- New Delhi Institute of Management: PGDM 2020-22 Semester-II Paper 2 (Set-B)Document3 pagesNew Delhi Institute of Management: PGDM 2020-22 Semester-II Paper 2 (Set-B)yashNo ratings yet
- Nama: Siti Rohmawati Nim: 218037 Kelas: S1-4ADocument5 pagesNama: Siti Rohmawati Nim: 218037 Kelas: S1-4ASiti rohmawatiNo ratings yet
- Planilha 1Document2 pagesPlanilha 1rafae19077No ratings yet
- Job Satisfaction StatisticsDocument4 pagesJob Satisfaction StatisticsJoy GinesNo ratings yet
- Statistics 1Document3 pagesStatistics 1CYNTHIA DEVI SIMANJUNTAK 19520283No ratings yet
- (LINA) Assignment Data AnalysisDocument8 pages(LINA) Assignment Data AnalysislynaAPPLESNo ratings yet
- 6th November Current AffairsDocument93 pages6th November Current AffairsParamita HalderNo ratings yet
- PIB 247 - 6th To 8th November 2023Document32 pagesPIB 247 - 6th To 8th November 2023Paramita HalderNo ratings yet
- PIB 247 - 6th To 8th November 2023Document32 pagesPIB 247 - 6th To 8th November 2023Paramita HalderNo ratings yet
- Data Types and StructureDocument6 pagesData Types and StructureParamita HalderNo ratings yet
- Iot 1.2 22MSM40017Document9 pagesIot 1.2 22MSM40017Paramita HalderNo ratings yet
- Heatmap, Joint Plot, Pair Plot PDFDocument5 pagesHeatmap, Joint Plot, Pair Plot PDFParamita HalderNo ratings yet
- Machine Learning ResourcesDocument2 pagesMachine Learning ResourcesHelloNo ratings yet
- January 2023 - Week 1 CA 1674070504581 PM PDFDocument39 pagesJanuary 2023 - Week 1 CA 1674070504581 PM PDFParamita HalderNo ratings yet
- Pinnacle English Book Latest Edition PDF DownloadDocument732 pagesPinnacle English Book Latest Edition PDF DownloadCheems dog71% (31)
- Web ArchitectureDocument284 pagesWeb ArchitecturedArKhAcKsNo ratings yet
- WorkshopPLUS Windows Server 2016 Hyper VDocument2 pagesWorkshopPLUS Windows Server 2016 Hyper VRichie BallyearsNo ratings yet
- CATALOG. Baotou Steel Seamless ProductsDocument8 pagesCATALOG. Baotou Steel Seamless ProductsEdward R KaolinNo ratings yet
- IGNOU - Examination Form AcknowledgementDocument2 pagesIGNOU - Examination Form AcknowledgementDayanand ThakurNo ratings yet
- Condition Monitoring of Zinc Oxide Surge Arresters: August 2011Document19 pagesCondition Monitoring of Zinc Oxide Surge Arresters: August 2011Đức ThảoNo ratings yet
- HTML Formatting: 1) Bold TextDocument18 pagesHTML Formatting: 1) Bold TextSubha SarahNo ratings yet
- English Project: Name: Muhammad Naazraj Bin RafiqDocument10 pagesEnglish Project: Name: Muhammad Naazraj Bin RafiqNameera ThangarajNo ratings yet
- Ib ST (ZF) 24 Bai 8/I: Analog Input Module With 8 ChannelsDocument24 pagesIb ST (ZF) 24 Bai 8/I: Analog Input Module With 8 ChannelsJosep Giménez CreixellNo ratings yet
- D-155 - 3 Cylinder Diesel Engine (01/75 - 12/85) 00 - Complete Machine 14-02 - Manifold, Intake-Naturally Aspirated EnginesDocument3 pagesD-155 - 3 Cylinder Diesel Engine (01/75 - 12/85) 00 - Complete Machine 14-02 - Manifold, Intake-Naturally Aspirated EnginesMANUALESNo ratings yet
- Ambient Intelligence: Prof. Renato NunesDocument27 pagesAmbient Intelligence: Prof. Renato NunesMelek MaalejNo ratings yet
- Account Statement 270721 261021Document34 pagesAccount Statement 270721 261021RahulNo ratings yet
- Shu 2016Document11 pagesShu 2016Usuário1243No ratings yet
- NPBC-V3C-1 Rev1 1 ENDocument36 pagesNPBC-V3C-1 Rev1 1 ENeddixNo ratings yet
- Fresher ECE Resume Model 213Document3 pagesFresher ECE Resume Model 213shanky_cs82% (17)
- Scott Ledbetter ResumeDocument1 pageScott Ledbetter ResumenoscottnoNo ratings yet
- Vivado Design Suite User Guide: Designing With IPDocument113 pagesVivado Design Suite User Guide: Designing With IPsambashivaNo ratings yet
- English - BAS#27 - Philips NMS 1205 Music Module Expander (Full Version)Document9 pagesEnglish - BAS#27 - Philips NMS 1205 Music Module Expander (Full Version)Luis AriasNo ratings yet
- 42NQV035 SVMDocument99 pages42NQV035 SVMHdnrkdNo ratings yet
- Unisalento4Talents Programme - Call For Applications For Scholarshipsfor International Students - (Academic Year 2021-2022) Application FormDocument4 pagesUnisalento4Talents Programme - Call For Applications For Scholarshipsfor International Students - (Academic Year 2021-2022) Application Formwaqar aliNo ratings yet
- Crude Oil Price Prediction ModeDocument12 pagesCrude Oil Price Prediction ModeMartín E. Rodríguez AmiamaNo ratings yet
- Installation Instructions: BW Seals Q, QB SeriesDocument8 pagesInstallation Instructions: BW Seals Q, QB Seriesaliihsan3461No ratings yet
- 5 Paragraph EssaysDocument45 pages5 Paragraph Essaysxumuqvwhd100% (2)
- Bahauddin Zakariya UniversityDocument8 pagesBahauddin Zakariya UniversityDanish mughalNo ratings yet
- PGCIL 33KV GIS SpecDocument21 pagesPGCIL 33KV GIS SpecManohar PotnuruNo ratings yet
- CASE-480 Manual en InglesDocument51 pagesCASE-480 Manual en InglesHugoRamosMamani100% (1)
- SAIC-A-2005 Rev 8Document4 pagesSAIC-A-2005 Rev 8Syed ImranNo ratings yet
- Understanding HTMLDocument11 pagesUnderstanding HTMLPriyaNo ratings yet
- FERASDocument55 pagesFERASFeras SalmanNo ratings yet
- All The GoF PatternsDocument57 pagesAll The GoF PatternsLuiz GonzagaNo ratings yet
- Characterization of A Generic 90nm CMOS Technology: DS DS DS GSDocument10 pagesCharacterization of A Generic 90nm CMOS Technology: DS DS DS GSgill6335No ratings yet