You might also like
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5813)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (844)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Consignment Journal Entries and Accounts FormatsDocument3 pagesConsignment Journal Entries and Accounts FormatsAnonymous duzV27Mx380% (5)
- Back Bay Battery Simulation ManojDocument6 pagesBack Bay Battery Simulation ManojManoj SinghNo ratings yet
- Generic Pharmaceutical Industry Yearbook Torreya Feb2016 GphaDocument72 pagesGeneric Pharmaceutical Industry Yearbook Torreya Feb2016 GphaSheltie ForeverNo ratings yet
- 344 PC 07 Arabtec SX MT 00061 - 03 Paint For Steel StructureDocument327 pages344 PC 07 Arabtec SX MT 00061 - 03 Paint For Steel Structurej f100% (1)
- Transpo Batch 1 CasesDocument62 pagesTranspo Batch 1 CasesAko Si CrokieNo ratings yet
- Assignment PCMDocument3 pagesAssignment PCMnajkoz yaruNo ratings yet
- Material For The 28th ACSIC Conference 2015 Taiwan Taiwan SMEGDocument21 pagesMaterial For The 28th ACSIC Conference 2015 Taiwan Taiwan SMEGzulfikar husinNo ratings yet
- A Study On Customer Purchasing Behaviour in Online Shopping During Pandemic (Covid-19)Document62 pagesA Study On Customer Purchasing Behaviour in Online Shopping During Pandemic (Covid-19)Nandu100% (1)
- Best Example of Cover Letter For Fresh GraduateDocument7 pagesBest Example of Cover Letter For Fresh Graduatekylopuluwob2100% (3)
- Project, Portfolio, Operation Management - PMDocument3 pagesProject, Portfolio, Operation Management - PMQueen Valle50% (2)
- General Banking Act and Classifications of Banks (15nov21)Document5 pagesGeneral Banking Act and Classifications of Banks (15nov21)Robinson MojicaNo ratings yet
- XRDocument77 pagesXRFredy Efraín Tzab MutNo ratings yet
- Unit 1 Calculation of Tax LiabilityDocument10 pagesUnit 1 Calculation of Tax LiabilitySupreet UdarNo ratings yet
- Q2 2023 Embassy Suites by Hilton Fact SheetDocument2 pagesQ2 2023 Embassy Suites by Hilton Fact SheetcraZyFFNo ratings yet
- The Proposal 3Document36 pagesThe Proposal 3hadiNo ratings yet
- Brand Audit Berger Paints: Group Members: 1. Syed Maaz Ali. 2. Syed Muhammad Fahad. 3. Muhammad Haseeb SiddiquiDocument18 pagesBrand Audit Berger Paints: Group Members: 1. Syed Maaz Ali. 2. Syed Muhammad Fahad. 3. Muhammad Haseeb SiddiquiSyedMaazNo ratings yet
- MBA SyllabusDocument48 pagesMBA SyllabusHidden ModeNo ratings yet
- Ajanta Ele Gold Mobile ZebronicsDocument1 pageAjanta Ele Gold Mobile ZebronicsRajkumar WadhwaniNo ratings yet
- Anup J Deshmukh CVDocument2 pagesAnup J Deshmukh CVSahil VaishyaNo ratings yet
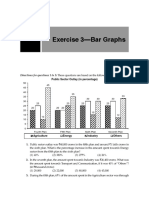
- Exercise 3-Bar Graphs: Directions For Questions 1 To 5Document5 pagesExercise 3-Bar Graphs: Directions For Questions 1 To 5avinashNo ratings yet
- Understanding The Entity and Its Environment: Phase I-CDocument1 pageUnderstanding The Entity and Its Environment: Phase I-CMarjorieNo ratings yet
- ERP in VodafoneDocument11 pagesERP in VodafoneVishakha Bople100% (1)
- Preface To Marketing Management 13th Edition Peter Solutions ManualDocument12 pagesPreface To Marketing Management 13th Edition Peter Solutions Manualsociablyrunning6y4vpe100% (22)
- Nptel QuestionsDocument4 pagesNptel QuestionsKumud SinghNo ratings yet
- Web Anal YticsDocument213 pagesWeb Anal YticsAditya KumarNo ratings yet
- Grand Strategy MatrixDocument12 pagesGrand Strategy MatrixYogita WaghNo ratings yet
- E Commerce and Trade CompleteDocument26 pagesE Commerce and Trade Completehasnain shahNo ratings yet
- PC 102 Professional Skills Gathering Agenda For Week 10Document3 pagesPC 102 Professional Skills Gathering Agenda For Week 10George CernikNo ratings yet
- Nico Quality Products VS N. C. Arya Snuff & CigarDocument13 pagesNico Quality Products VS N. C. Arya Snuff & CigarEmily FosterNo ratings yet
- General Conditions of Contract: Construction Works (2020) - CPWDDocument33 pagesGeneral Conditions of Contract: Construction Works (2020) - CPWDramrocks01No ratings yet