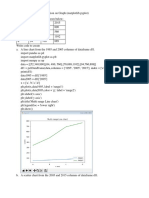
You might also like
- 20mid0209 Assessment - 7Document10 pages20mid0209 Assessment - 7R B SHARANNo ratings yet
- Heatmap InstructionDocument9 pagesHeatmap InstructionNguyễn Hải ĐăngNo ratings yet
- Exploratory VisualisationsDocument16 pagesExploratory Visualisationskaru gaNo ratings yet
- Rstudio Study Notes For PA 20181126Document6 pagesRstudio Study Notes For PA 20181126Trong Nghia VuNo ratings yet
- Unit10 QB VHADocument36 pagesUnit10 QB VHAdaku5246No ratings yet
- Data Visulization Lab Assignment 2 PDFDocument14 pagesData Visulization Lab Assignment 2 PDFnimiNo ratings yet
- Assignment Business Analytics B BiswasDocument7 pagesAssignment Business Analytics B BiswasSRINIVAS PANDANo ratings yet
- Exp2 - Data Visualization and Cleaning and Feature SelectionDocument13 pagesExp2 - Data Visualization and Cleaning and Feature SelectionmnbatrawiNo ratings yet
- Assignment 4 On Visualization On Graph With SolutionDocument14 pagesAssignment 4 On Visualization On Graph With Solutionvikas_2No ratings yet
- R Unit5Document12 pagesR Unit5Bhagyalaxmi TambadNo ratings yet
- Chapter 03 Visualization (R)Document30 pagesChapter 03 Visualization (R)hasanNo ratings yet
- Oefentt Jaar 3Document11 pagesOefentt Jaar 3Branco SieljesNo ratings yet
- Ggplot2 Library BoxplotDocument20 pagesGgplot2 Library BoxplotLuis EmilioNo ratings yet
- Saveetha Institute of Medical and Technical Sciences: Unit V Plotting and Regression Analysis in RDocument63 pagesSaveetha Institute of Medical and Technical Sciences: Unit V Plotting and Regression Analysis in RMuzakir Laikh KhanNo ratings yet
- Unit10 - QB - Solution - Jupyter NotebookDocument33 pagesUnit10 - QB - Solution - Jupyter Notebookdaku5246No ratings yet
- 2 R - Zajecia - 4 - EngDocument7 pages2 R - Zajecia - 4 - EngRasooly MNNo ratings yet
- Creating Plots in R Using Ggplot2 - Part 9: Function PlotsDocument17 pagesCreating Plots in R Using Ggplot2 - Part 9: Function PlotsLaura RodriguezNo ratings yet
- 1 - Linear - Regression - Ipynb - ColaboratoryDocument7 pages1 - Linear - Regression - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- Final - DNN - Hands - On - Jupyter NotebookDocument8 pagesFinal - DNN - Hands - On - Jupyter Notebooktango charlie25% (4)
- Test RunsDocument7 pagesTest Runsarslan sabirNo ratings yet
- Display ListDocument4 pagesDisplay ListGeorge PuiuNo ratings yet
- Data Visualization With Ggplot2, Asthetic Mappings, Facets, Common Problems, Layered Grammar of GraphicsDocument21 pagesData Visualization With Ggplot2, Asthetic Mappings, Facets, Common Problems, Layered Grammar of GraphicskeexuepinNo ratings yet
- Bipin Python ProgrammingDocument21 pagesBipin Python ProgrammingVipin SinghNo ratings yet
- ProjectDocument17 pagesProjectmohamed mohsenNo ratings yet
- Python Data Analysation and VisualisationDocument4 pagesPython Data Analysation and VisualisationJagmohanNo ratings yet
- Content: Dplyr, Readr, TM, Ggplot2/+ggforce/, Tidyr, Broom DplyrDocument8 pagesContent: Dplyr, Readr, TM, Ggplot2/+ggforce/, Tidyr, Broom DplyrИван РадоновNo ratings yet
- Código VIII.8.Generar Diveros GraficosDocument13 pagesCódigo VIII.8.Generar Diveros GraficosharolNo ratings yet
- CV Assignment 2 Group02Document12 pagesCV Assignment 2 Group02Manash BarmanNo ratings yet
- B2a018029 - Iffah Norma H. - Kuis DatminDocument7 pagesB2a018029 - Iffah Norma H. - Kuis DatminIffahNo ratings yet
- Micro Eportfolio Fall 13 Assign PC and Monop 1Document3 pagesMicro Eportfolio Fall 13 Assign PC and Monop 1api-231890132No ratings yet
- Week 10Document15 pagesWeek 10Hanumanthu GouthamiNo ratings yet
- SVM Example in RDocument4 pagesSVM Example in RJohn Alexis CabolisNo ratings yet
- K MeansDocument4 pagesK Meansmohamed mohsenNo ratings yet
- Lecture 02 ProportionDocument25 pagesLecture 02 ProportionDhruv PatelNo ratings yet
- DV Lab Ex - No.8Document3 pagesDV Lab Ex - No.8chandra Shekar balaji AeluriNo ratings yet
- Case Study in MatlabDocument47 pagesCase Study in MatlabscribdssrNo ratings yet
- Peer Review Assignment 4: InstructionsDocument17 pagesPeer Review Assignment 4: Instructionshamza omar100% (1)
- R GraphicsDocument76 pagesR GraphicsFaca CórdobaNo ratings yet
- Sakhil Assignment 02Document8 pagesSakhil Assignment 02JenishNo ratings yet
- Coding IntroductionDocument46 pagesCoding Introductionlijiayi2023666No ratings yet
- EDA & Data VizDocument21 pagesEDA & Data VizAdisya Yuliasari RohimanNo ratings yet
- OR RecordDocument35 pagesOR RecordGOWTHAM H : CSBS DEPTNo ratings yet
- Exercise-9..Study and Implementation of Data Visulization With GgplotDocument1 pageExercise-9..Study and Implementation of Data Visulization With GgplotSri RamNo ratings yet
- Final - DNN - Hands - On - Jupyter NotebookDocument6 pagesFinal - DNN - Hands - On - Jupyter NotebookAradhana Mehra0% (1)
- Mlaifile1 3Document27 pagesMlaifile1 3Krishna kumarNo ratings yet
- Grpahs and Charts in RDocument12 pagesGrpahs and Charts in RMohammed IrfanNo ratings yet
- Ip Practical FileDocument20 pagesIp Practical Fileayanspartan3536No ratings yet
- CCA175 Demo ExamenesDocument19 pagesCCA175 Demo ExamenesJosé Ramón Espinosa MuñozNo ratings yet
- Variosalgoritmos - Jupyter NotebookDocument9 pagesVariosalgoritmos - Jupyter NotebookPAULO CESAR CALDERON BERMUDO100% (1)
- Urmi ML Practical FileDocument37 pagesUrmi ML Practical Filebekar kaNo ratings yet
- R Version 3Document31 pagesR Version 3Isela Zecua AlejoNo ratings yet
- DM Slip SolutionsDocument24 pagesDM Slip Solutions09.Khadija Gharatkar100% (1)
- Micro Eportfolio Fall 13 Assign PC and Monop-1 2Document8 pagesMicro Eportfolio Fall 13 Assign PC and Monop-1 2api-260803388No ratings yet
- K Means Clustering in R Example - Learn by MarketingDocument3 pagesK Means Clustering in R Example - Learn by MarketingAri CleciusNo ratings yet
- DM PracticeDocument15 pagesDM Practice66 Rohit PatilNo ratings yet
- Machine Learning LAB: Practical-1Document24 pagesMachine Learning LAB: Practical-1Tsering Jhakree100% (1)
- Machine Learning Notes: 2. All The Commands For EdaDocument5 pagesMachine Learning Notes: 2. All The Commands For Edanaveen katta100% (1)
- 2020-21 XIIInfo - Pract.S.E.155Document11 pages2020-21 XIIInfo - Pract.S.E.155Haresh NathaniNo ratings yet
- Wildlife EcologyDocument1 pageWildlife EcologyR B SHARANNo ratings yet
- Ujera8 19591328Document7 pagesUjera8 19591328R B SHARANNo ratings yet
- LSM Final DADocument5 pagesLSM Final DAR B SHARANNo ratings yet
- IJCRT2006263Document4 pagesIJCRT2006263R B SHARANNo ratings yet
- Last YearDocument60 pagesLast YearR B SHARANNo ratings yet
- Winter Sem 2022 - MergedDocument14 pagesWinter Sem 2022 - MergedR B SHARANNo ratings yet
- Bare JRNLDocument11 pagesBare JRNLR B SHARANNo ratings yet
- Day To Day ActivitieDocument6 pagesDay To Day ActivitieR B SHARANNo ratings yet
- Brain Tumor Identification and Classification Using Neural NetworkDocument17 pagesBrain Tumor Identification and Classification Using Neural NetworkR B SHARANNo ratings yet
- E-Commerce Price Comparison Website Using Web ScrapingDocument14 pagesE-Commerce Price Comparison Website Using Web ScrapingR B SHARANNo ratings yet
- Sharan Intern ReportDocument19 pagesSharan Intern ReportR B SHARANNo ratings yet
- JETIR2306031Document6 pagesJETIR2306031R B SHARANNo ratings yet
- Kokila 2021 J. Phys. Conf. Ser. 1916 012226Document10 pagesKokila 2021 J. Phys. Conf. Ser. 1916 012226R B SHARANNo ratings yet
- 22MIC0214Document3 pages22MIC0214R B SHARANNo ratings yet
- 20mid0209 Da 1Document9 pages20mid0209 Da 1R B SHARANNo ratings yet
- 20MID0209 Lab Assignmnet 2Document11 pages20MID0209 Lab Assignmnet 2R B SHARANNo ratings yet
- Caesar Cipher:: Applied Cryptography and Network Security SLOT: L21+L22 Lab Assignment - 1Document13 pagesCaesar Cipher:: Applied Cryptography and Network Security SLOT: L21+L22 Lab Assignment - 1R B SHARANNo ratings yet
- Data Structures and Algorithm Analysis - Quiz 1 Sep 27th 2023 at 9.10 - 9.25 AmDocument11 pagesData Structures and Algorithm Analysis - Quiz 1 Sep 27th 2023 at 9.10 - 9.25 AmR B SHARANNo ratings yet
- 20mid0209 Assessment - 10Document14 pages20mid0209 Assessment - 10R B SHARANNo ratings yet
- 20mid0209 Java Da-1Document14 pages20mid0209 Java Da-1R B SHARANNo ratings yet
- 20mid0209 Assessment - 5Document6 pages20mid0209 Assessment - 5R B SHARANNo ratings yet
- CSI3020 ADA AM Final A2 Slot KeyDocument6 pagesCSI3020 ADA AM Final A2 Slot KeyR B SHARANNo ratings yet
- 6-Shneideman''s Eight Golden Rules-20!01!2023Document1 page6-Shneideman''s Eight Golden Rules-20!01!2023R B SHARANNo ratings yet
- 20mid0209 Assessment - 6Document8 pages20mid0209 Assessment - 6R B SHARANNo ratings yet
- 20mid0209 Assessment - 4Document16 pages20mid0209 Assessment - 4R B SHARANNo ratings yet
- 20mid0209 R Prog - 1Document9 pages20mid0209 R Prog - 1R B SHARANNo ratings yet
- 20mid0209 Assessment - 8Document7 pages20mid0209 Assessment - 8R B SHARANNo ratings yet
- 20mid0209 R Prog - 2Document12 pages20mid0209 R Prog - 2R B SHARANNo ratings yet
- Csi3017 - Business-Intelligence - TH - 1.0 - 66 - Csi3017 - 61 AcpDocument2 pagesCsi3017 - Business-Intelligence - TH - 1.0 - 66 - Csi3017 - 61 AcpR B SHARANNo ratings yet