You might also like
- Ip Practical FileDocument20 pagesIp Practical Fileayanspartan3536No ratings yet
- IP Record Final-1Document34 pagesIP Record Final-1pushpanarasimha1996No ratings yet
- ST Joseph'S Convent Senior Secondary School: Name:-Shatakshi Gaur Class:-Xii Sec:-A Board Roll No.Document65 pagesST Joseph'S Convent Senior Secondary School: Name:-Shatakshi Gaur Class:-Xii Sec:-A Board Roll No.Navjeet SinghNo ratings yet
- Saish IP ProjectDocument16 pagesSaish IP ProjectSaish ParkarNo ratings yet
- Informatics Practices Practical List22-2323Document7 pagesInformatics Practices Practical List22-2323Shivam GoswamiNo ratings yet
- Informatics Practices Practical List22-2323Document7 pagesInformatics Practices Practical List22-2323Shivam GoswamiNo ratings yet
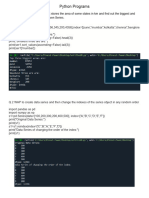
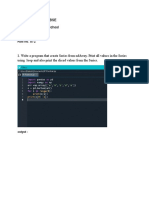
- Python ProgramsDocument9 pagesPython ProgramsHarsh Pawar100% (1)
- Informatics Practices Practical List22-2323Document6 pagesInformatics Practices Practical List22-2323Shivam GoswamiNo ratings yet
- Ipr Practical 2022Document7 pagesIpr Practical 2022Shivam GoswamiNo ratings yet
- Final Class 12 Commerce Practical FileDocument19 pagesFinal Class 12 Commerce Practical FileSnehil ChundawatNo ratings yet
- Parth B Rathod (IP)Document35 pagesParth B Rathod (IP)Bipin ChandraNo ratings yet
- Class12 Ip Practical ListDocument2 pagesClass12 Ip Practical ListPriyansh PatelNo ratings yet
- Block 1-Data Handling Using Pandas DataFrameDocument17 pagesBlock 1-Data Handling Using Pandas DataFrameBhaskar PVNNo ratings yet
- Creation of Series Using List, Dictionary & NdarrayDocument65 pagesCreation of Series Using List, Dictionary & Ndarrayrizwana fathimaNo ratings yet
- National Public School: Name-Karan Choudhary Class-XII Subject - Informatics Practices (065) Board Roll No.Document35 pagesNational Public School: Name-Karan Choudhary Class-XII Subject - Informatics Practices (065) Board Roll No.rajeshNo ratings yet
- PandaDocument33 pagesPandakrNo ratings yet
- Worksheet-1 (Python)Document9 pagesWorksheet-1 (Python)rizwana fathimaNo ratings yet
- Journal 12Document54 pagesJournal 12Be xNo ratings yet
- IP (12) Proj File Pandas&MatplotlibDocument12 pagesIP (12) Proj File Pandas&Matplotlibakarshsahu417No ratings yet
- National Public School: Name-Karan Choudhary Class-XII Subject - Informatics Practices (065) Board Roll No.Document24 pagesNational Public School: Name-Karan Choudhary Class-XII Subject - Informatics Practices (065) Board Roll No.rajeshNo ratings yet
- National Public School: Name-Mohit Kumar Class-XII Subject - Informatics Practices (065) Board Roll No.Document35 pagesNational Public School: Name-Mohit Kumar Class-XII Subject - Informatics Practices (065) Board Roll No.rajeshNo ratings yet
- National Public School: Name-Mohit Kumar Class-XII Subject - Informatics Practices (065) Board Roll No.Document35 pagesNational Public School: Name-Mohit Kumar Class-XII Subject - Informatics Practices (065) Board Roll No.rajeshNo ratings yet
- Suryadatta National School Class 12 CBSE Informatics Practices Practicals ListDocument19 pagesSuryadatta National School Class 12 CBSE Informatics Practices Practicals ListOm JagdeeshNo ratings yet
- Yash Sharma Praticle FileDocument31 pagesYash Sharma Praticle FilenitinNo ratings yet
- IP PraticalDocument56 pagesIP Praticalvaibhavm2359No ratings yet
- Class 12 IP File 23 24Document27 pagesClass 12 IP File 23 24toeshipahadiyaNo ratings yet
- IP Project 12ADocument39 pagesIP Project 12AGVWScls1No ratings yet
- Practical File: School Name School LogoDocument35 pagesPractical File: School Name School Logovinayak chandra100% (1)
- Pandas 3Document33 pagesPandas 3cr.lucianoperezNo ratings yet
- INDEXDocument2 pagesINDEXKrish BagariaNo ratings yet
- Ip PracticalDocument31 pagesIp PracticalJaspreet SinghNo ratings yet
- 12 IP Practical ExamplDocument6 pages12 IP Practical ExamplUV DabNo ratings yet
- IP Practical File XII CBSE Suryadatta National School Bhavika Rakesh Roll No. 072Document21 pagesIP Practical File XII CBSE Suryadatta National School Bhavika Rakesh Roll No. 072Bhavika RakeshNo ratings yet
- Pratical SQLDocument5 pagesPratical SQLKarthi MurthyNo ratings yet
- IP Assgn 3Document12 pagesIP Assgn 3Siérra GreenNo ratings yet
- Practical List 2022-23Document4 pagesPractical List 2022-23ANIKET RATHOUR100% (1)
- PYTHON PROGRAM - PRACTICAL FILE PROGRAMS - XII IP - Learnpython4cbseDocument16 pagesPYTHON PROGRAM - PRACTICAL FILE PROGRAMS - XII IP - Learnpython4cbseanmolsinha6157No ratings yet
- Holidays Homework - 20231204 - 195647 - 0000Document15 pagesHolidays Homework - 20231204 - 195647 - 0000Arshpreet SinghNo ratings yet
- Python Series DataFrames Commands Methods Properties Examples (2022-23) PDFDocument16 pagesPython Series DataFrames Commands Methods Properties Examples (2022-23) PDFSaniya Santhosh100% (1)
- Class 12 IP - Program List - Term1Document2 pagesClass 12 IP - Program List - Term1MANAN JOSHI JOSHINo ratings yet
- Practical Record 2 PYTHON AND SQL PROGRAMS - 2023Document76 pagesPractical Record 2 PYTHON AND SQL PROGRAMS - 2023isnprincipal2020No ratings yet
- ClassicDocument36 pagesClassicAbeer ReaderNo ratings yet
- Pandas Practicals - Term-1Document18 pagesPandas Practicals - Term-1Rudra DewanganNo ratings yet
- G Pandey PracticalDocument33 pagesG Pandey PracticalSadananda Moirãngthëm Gidi LêïjreNo ratings yet
- Ds FileDocument40 pagesDs FileYash Kumar100% (1)
- JournalDocument35 pagesJournalvinodpatel10197No ratings yet
- Ip PracticalsDocument62 pagesIp Practicalsaswinmadhav9aNo ratings yet
- Final 1Document38 pagesFinal 1Mahil PawarNo ratings yet
- Data Preprocessing Python Tome IIIDocument12 pagesData Preprocessing Python Tome IIIElisée TEGUENo ratings yet
- Practical File PythonDocument25 pagesPractical File Pythonkaizenpro01No ratings yet
- Ip Practical FileDocument49 pagesIp Practical Filegahlotkavya09No ratings yet
- IP Practical PRGMDocument41 pagesIP Practical PRGMJeya IshwaryaNo ratings yet
- Pandasmatplotlib Practical FileDocument15 pagesPandasmatplotlib Practical FilegodayushshrivastavaNo ratings yet
- Pip3 Install JupyterDocument16 pagesPip3 Install Jupyterblah blNo ratings yet
- CertificateDocument25 pagesCertificateTanmay ManeNo ratings yet
- Computer Programs JavaDocument26 pagesComputer Programs JavaSujata ShawNo ratings yet
- Practical List IpDocument10 pagesPractical List IpRaj aditya Shrivastava100% (1)
- 3 Programs 21 To 24Document3 pages3 Programs 21 To 24Rooshi RoobanNo ratings yet
- Java Programming Tutorial With Screen Shots & Many Code ExampleFrom EverandJava Programming Tutorial With Screen Shots & Many Code ExampleNo ratings yet
- CSC 1403 Database Concepts First AssignmentDocument6 pagesCSC 1403 Database Concepts First AssignmentAchyut NeupaneNo ratings yet
- Practice 4 PDFDocument5 pagesPractice 4 PDFuserNo ratings yet
- Database ListDocument70 pagesDatabase ListNeil Rao Towers0% (10)
- Insert: Create Table SyntaxDocument360 pagesInsert: Create Table SyntaxAnkurNo ratings yet
- Snapshot Standby and Active Data Guard PDFDocument23 pagesSnapshot Standby and Active Data Guard PDFG.R.THIYAGU ; Oracle DBA100% (8)
- Homework 13 Fa11Document4 pagesHomework 13 Fa11Душан СекулићNo ratings yet
- Entity Relationship Model: IS 2511 - Fundamentals of Database SystemsDocument56 pagesEntity Relationship Model: IS 2511 - Fundamentals of Database Systemsjake dossryNo ratings yet
- Huum - Info db2 Notes PRDocument77 pagesHuum - Info db2 Notes PRV JNo ratings yet
- Basic CRUD Operations, F Unctions, Expressions An D ClausesDocument35 pagesBasic CRUD Operations, F Unctions, Expressions An D ClausesgeethanjaliNo ratings yet
- SQLWorkbench Manual PDFDocument250 pagesSQLWorkbench Manual PDFChandradeep Reddy TeegalaNo ratings yet
- SQL Unguided ExerciseDocument1 pageSQL Unguided ExerciseFelix SantosNo ratings yet
- Chapter 6Document46 pagesChapter 6Abdikarim AbdullahiNo ratings yet
- PL SQL Developer Sample ResumeDocument2 pagesPL SQL Developer Sample ResumeSenthil Kumar JayabalanNo ratings yet
- Cs-403 Mid Term Mcq's by Vu Topper RMDocument34 pagesCs-403 Mid Term Mcq's by Vu Topper RMabbas abbas khanNo ratings yet
- Bs (Se) F 2019: C T: D S C C: CSS 2062 2019/Comp/AFN/BS (SE) /1925 S B: S T: M - S ODocument8 pagesBs (Se) F 2019: C T: D S C C: CSS 2062 2019/Comp/AFN/BS (SE) /1925 S B: S T: M - S OJaweriya AlamNo ratings yet
- RDBMS: Manages Data in The Form of Tables. Related Tables in RDBMS Have Relationships Through Common ValuesDocument45 pagesRDBMS: Manages Data in The Form of Tables. Related Tables in RDBMS Have Relationships Through Common ValuesaggarwalmeghaNo ratings yet
- Concurrent Manager QueriesDocument51 pagesConcurrent Manager QueriesnamrataNo ratings yet
- Day-3 Joins and Sub QryDocument46 pagesDay-3 Joins and Sub QryAshok Durai100% (1)
- Exam: NR0-013 Title: Teradata SQL v2r5 Ver: 03-03-08Document37 pagesExam: NR0-013 Title: Teradata SQL v2r5 Ver: 03-03-08Ujwal Narasapur100% (1)
- Database Sharding at NetlogDocument70 pagesDatabase Sharding at NetlogDmytro Shteflyuk100% (5)
- Tempfile - Docx 817Document51 pagesTempfile - Docx 817Alan Robert Moran CahuanaNo ratings yet
- Storing XML Using Relational Model: XML and Data Management By: Habiba Skalli For: Dr. HaddoutiDocument36 pagesStoring XML Using Relational Model: XML and Data Management By: Habiba Skalli For: Dr. Haddoutikeisan12No ratings yet
- PL/SQL Practice Quizzes Exam 2Document6 pagesPL/SQL Practice Quizzes Exam 2meachamrob0% (1)
- Ubuntu + Freeradius + MysqlDocument5 pagesUbuntu + Freeradius + MysqlranoevaNo ratings yet
- 27 Python Database Programming Study Material PDFDocument17 pages27 Python Database Programming Study Material PDFRajendra Buchade100% (1)
- APACHE REDIS Training: Trainer:David JosephDocument3 pagesAPACHE REDIS Training: Trainer:David JosephDavid JosephNo ratings yet
- DMS (22319) - Chapter 3 NotesDocument83 pagesDMS (22319) - Chapter 3 Notespdijgqam1nNo ratings yet
- 04 PostgreSQL Lab ExercisesDocument6 pages04 PostgreSQL Lab Exercisespaula Sanchez GayetNo ratings yet
- Snowflake Schema: The Snowflake Schema Is An Extension of Star Schema. in A SnowflakeDocument4 pagesSnowflake Schema: The Snowflake Schema Is An Extension of Star Schema. in A SnowflakeDeepu GoraiNo ratings yet
- Ntma Import Schema CreationDocument9 pagesNtma Import Schema CreationlakshmanNo ratings yet